
L’océrisation en pratique

Introduction
Face à l’explosion des données et des documents en libre accès, l’analyse rapide et efficace des documents commerciaux est un enjeu de taille. Une question anime les débats dans les entreprises : comment avoir accès, grâce à l’océrisation, aux informations pertinentes contenues dans les documents commerciaux, les contrats ou encore les notes de frais ?
Qu’est-ce que l’océrisation ?
L’une des plus vieilles techniques de vision par ordinateur est l’océrisation. Ce barbarisme est inspiré de l’acronyme anglais OCR (Optical Character Recognition) : reconnaissance optique de caractères. L’océrisation est le processus permettant l’extraction du texte contenu dans une image.
L’océrisation peut être utilisée pour différents types de problématiques dans le but de faire de l’extraction :
- de numéros de maisons comme dans le cas du dataset SVHN (Street View House Numbers)
- de plaques d’immatriculation
- d’informations issues d’images PDF
Dans cet article, nous allons traiter des images d’emballage de produits alimentaires afin d’extraire les informations pertinentes sur ces derniers.
Pour ce faire, nous avons utilisé Tesseract OCR : un outil open source créé par des ingénieurs de Hewlett Packard entre 1985 et 1995. Cependant, l’outil fut abandonné pendant dix longues années jusqu’à ce qu’en 2005 le projet soit repris par Google.
La dernière version, Tesseract 4, possède une couche de réseau de neurones LSTM (Long Short-Term Memory) qui détecte les lignes, en plus de la reconnaissance de caractères. Tesseract adopte le format Unicode (UTF-8) et peut reconnaître plus de 100 langues.
Comment fonctionne l’OCR ?
- Le prétraitement : dans notre cas, nous allons traiter des images PDF, mais avant il faudrait appliquer quelques conversions sur les niveaux de gris, le lissage, la détection de contours, ou encore la réduction du coefficient d’asymétrie (skewness). En ce qui concerne le traitement des images numériques, les surfaces sombres et brillantes ont tendance à être plus asymétriques que les surfaces claires et mates. Par conséquent, nous pouvons utiliser l’asymétrie pour équilibrer les surfaces de l’image.
- La segmentation : la segmentation d’images vise à isoler les lignes et les caractères contenus dans l’image.
- La reconnaissance des mots et des caractères : Tesseract utilise un modèle de Machine Learning pré-entraîné sur de vastes bases de formes pour être en mesure de décider à quelle classe appartient chaque forme.

Processus de segmentation et de reconnaissance de caractères
Ensuite, une liste triée de caractères candidats est générée en se basant sur l’ensemble de l’apprentissage.
- Le post-traitement : à partir du score de confiance obtenu lors des étapes précédentes et du dictionnaire des données, les caractères les plus pertinents seront choisis par l’algorithme.
Ci-dessous, l’architecture générale d’un OCR.

Architecture d’un OCR
Camelot
Camelot est un package open source implémenté en python, offrant un libre accès à la donnée et cela peu importe l’organisation du document.
Il offre deux algorithmes d’extraction de tableaux depuis des images PDF : Stream et Lattice.
Stream est utilisé pour analyser des tableaux comportant des espaces entre les cellules, afin de simuler une structure de table.

Tandis que Lattice peut être utilisé pour analyser les tableaux dont les cellules sont délimitées par des bordures. Il permet également l’analyse automatique de plusieurs tableaux présents sur une même page. Cette solution répond à la majorité des tableaux que l’on rencontre.
Démonstration :
Dans ce qui suit, nous allons voir le processus, de l’extraction de l’information d’images PDF jusqu’à leur exploitation. Pour notre démonstration, nous allons extraire la date de péremption ainsi que les valeurs nutritionnelles d’une photographie de pot de yaourt.

- Prétraitement :
Un texte dans une image PDF ne peut être sélectionné. Dans le cas où les documents ne contiennent pas de tableaux, la solution est vite trouvée avec Tesseract. Cependant, les images de pots de yaourts contiennent des tableaux nutritionnels et nous allons utiliser Camelot pour les extraire. Il sera nécessaire de transformer nos images avant, en utilisant cette bibliothèque python.
- Traitement :
Nous allons extraire le texte hors du tableau### Les imports nécessaires try: from PIL import Image except ImportError: import Image import pytesseract import re import camelot import stringpytesseract.pytesseract.tesseract_cmd = r'chemin du dossier tesseract dans le bin ' image = Image.open("chemin vers l'image sans tableau") ### on spécifie le format de sortie et les langues à traiter image_as_string = pytesseract.image_to_string(image_yaourt, output_type="string", lang="fra+eng")Maintenant nous avons le choix entre la sauvegarde du fichier sous format texte ou l’utilisation directe du résultat stocké dans la variable image_as_string.
Le résultat de l’océrisation est illustré dans la figure suivante :
Résultat de l’océrisation du produitPour ce qui est des images contenant des tableaux, l’utilisation de Camelot se fait comme ceci :

tables = camelot.read_pdf("chemin vers l'image PDF sélectionnable")Le résultat de Camelot est sous le format TableList transformable facilement en dataframe en appliquant un slicing de la sorte :
tables[n].df # n = len(tables)

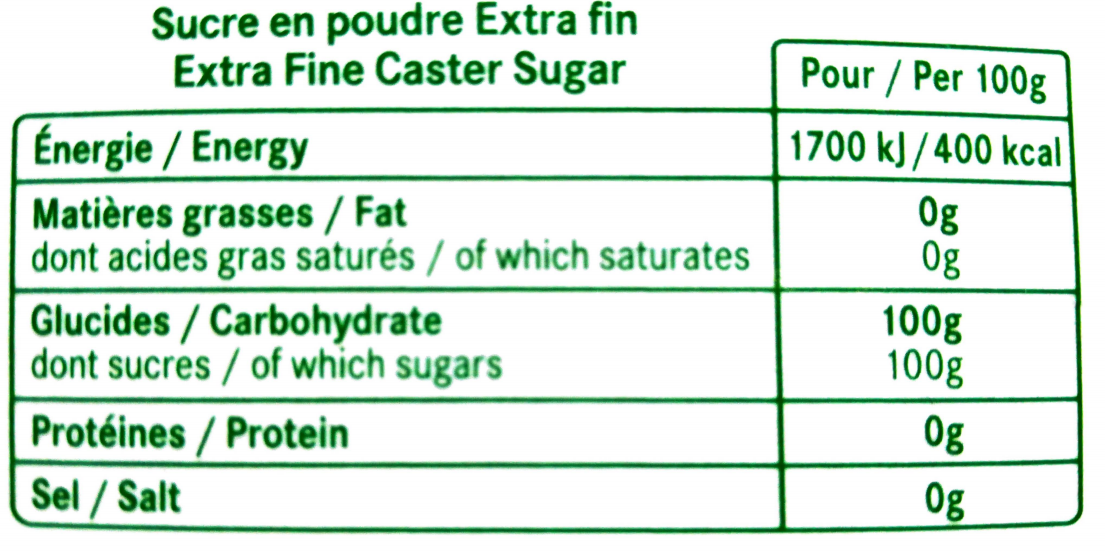
Extraction des valeurs nutritionnelles du produit
Exploiter les informations : du sur-mesure
Le texte de l’emballage a été intégré, de même que l’éventuel tableau. Reste la troisième étape, tout aussi essentielle : exploiter ces informations. Les fichiers texte peuvent être exploités directement. Les fichiers CSV des tableaux sont quant à eux lus, donnant des Data frames à transformer en listes de strings.
- Post-traitement : Le post-traitement dépend grandement du texte obtenu, néanmoins nous allons mentionner quelques étapes de traitement de texte qui varient suivant le document à traiter.
- Mettre le texte en minuscule :
image_to_string_lower = image_to_string.lower() - Enlever la ponctuation et les caractères spéciaux :
string.punctuation = "#$%&\'()*+;<=>?@[\\]^_`{|}~!""" # à définir au choixtranslator = str.maketrans('', '', string.punctuation) print(image_to_string_lower.translate(translator)) - Enlever tous les caractères blancs du début et de la fin :
string_blank_removed = image_to_string_lower.strip() - Remplacer tous les caractères \n par un espace :
string_to_replace = string_blank_removed replaced = re.sub('\n', ' ', string_to_replace) print(replaced)
- Mettre le texte en minuscule :
Ce qu’il faudrait retenir est que le traitement de texte n’est pas une recette de cuisine prête à l’emploi. Tout dépend de l’image et de ce que nous voulons en extraire.
Maintenant que notre texte est prêt à être utilisé, nous allons pouvoir procéder à l’exploitation des données.
Nous avons appliqué, sur les tableaux comme sur les textes, des “expressions régulières”, des moules spécialisés, créés spécialement pour lire et comprendre chaque donnée. C’est à dire un moule pour la date de péremption, un autre pour le montant de la facture, encore un autre pour les valeurs nutritionnelles du produit, etc.
Il est indispensable de faire du sur-mesure, pour adapter les moules à l’information à extraire. Un moule devient ainsi capable de reconnaître automatiquement différentes manières de présenter une même information (par exemple “MG” ou “matière grasse”), de lire les différentes unités de mesure (microgramme, gramme…) ou d’intégrer tous les formats d’une date de péremption (“expiration le”, “exp. le”, “à consommer avant le”…).
Extraction de la date :
Dans le cas où nous avons bien fait le prétraitement de notre texte en enlevant tous les bruits pouvant dégrader et induire en erreur nos expressions régulières, nous pouvons récupérer la date de péremption simplement en appliquant :
re.findall(r"avant le \d+.\d+.\d+", replaced)
# ou encore :
re.findall(r" avant le \d+.\d+.\d+|avant le \d+/\d+/\d+| avant le \d+:\d+:\d+| avant le \d+-\d+-\d+", string_blank_removed)
Le résultat du traitement est illustré dans la figure suivante :
![]()
L’exemple est beaucoup plus parlant pour des fiches de paie ou encore des factures, car généralement le texte suit une nomenclature précise.
Nous avons aussi testé notre exemple sur un ticket de caisse duquel nous avons voulu extraire le montant total et hors taxe de la commande.

Résultat de l’océrisation d’un ticket de caisse
re.findall(r"total ttc \d+, \d+|total ttc \d+,\d+|total ttc \d+.\d* |total ht \d+, \d+|total ht \d+,\d+", replaced)Voici le résultat obtenu :
![]()
Résultat de l’extraction du montant d’un ticket de caisse
Limitations de Tesseract :
- Des numérisations de mauvaise qualité peuvent produire une OCR de mauvaise qualité.
- Par défaut, Tesseract n’est pas capable de reconnaître l’écriture manuscrite.
- L’OCR a du mal à différencier les caractères, tels que le chiffre zéro et un “O” majuscule.
- Si un document contient des langues autres que celles indiquées dans les arguments -l LANG, les résultats peuvent être médiocres.
Conclusion
Conversion d’une image en texte, conversion et lecture d’un tableau, extraction intelligente des données et Machine Learning sont les axes traités dans cet article.
La solution que nous avons présentée est efficace, comme nous avons pu le constater, dans certaines applications. Ceci dit, l’océrisation dépend grandement de la qualité des documents en entrée.
Pour aller plus loin et passer outre les expressions régulières nous obligeant à créer des moules pour chaque type d’information à récupérer, nous pouvons imaginer l’utilisation des NER (Named Entity recognition) en prenant soin d’entraîner notre modèle à reconnaître les patterns que l’on veut extraire.
On pourrait imaginer des usages plus grand public à notre solution, notamment la numérisation de livres pour les partager plus facilement, numérisation des boîtes de médicaments pour éviter les erreurs de prise ou de dosage, etc.
En bout de chaîne, une intervention humaine est toujours nécessaire pour valider un document océrisé à l’aide d’une base de vérité.
De quoi donner des idées à toute entreprise confrontée au problème de documents à numériser, archiver et traiter.
© SOAT
Toute reproduction interdite sans autorisation de l’auteur.