
Déclarer la guerre aux données déséquilibrées : VAE

Introduction
Comme nous l’avons vu dans une première partie, la méthode SMOTE permet d’augmenter considérablement notre dataset. Découvrons ensemble aujourd’hui une autre approche de suréchantillonnage orientée Deep Learning nommée Variational Auto-encoder.
Auto-Encodeurs
Les auto-encodeurs (AE) sont des algorithmes d’apprentissage profonds (Deep Learning) non supervisés. Les scénarios d’utilisation des AE sont souvent la réduction de la dimension spatiale, le débruitage (retirer du bruit) ou la visualisation de données. Ici, nous allons les utiliser pour augmenter notre dataset. Le CAE, (Auto-Encodeur Convolutif) utilise des convolutions afin de mieux gérer les données telles que l’audio, l’image ou même le texte.
Un auto-encodeur est composé de 2 réseaux de neurones : un encodeur et un décodeur.
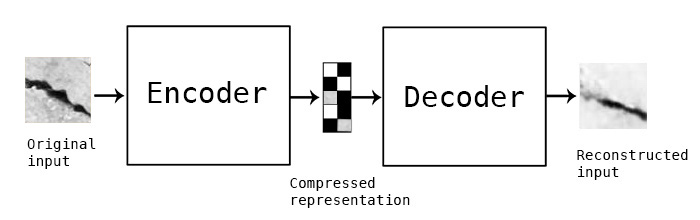 Structure schématique d’un auto-encodeur |
Encodeur : le modèle de reconnaissance encode l’image sous forme d’une représentation compressée (un code) dans un espace de dimension réduit (espace latent). L’image compressée a généralement l’air d’être une déformation de l’image originale.
Décodeur : le modèle génératif décode l’image réduite (le code) à sa dimension originale. L’image décodée est une reconstruction approximative de l’image originale.
Afin de suréchantillonner notre dataset, il suffit de passer au décodeur un code aléatoire, et il générera une image proche de celles qu’il a appris à reconstruire.
Variational Auto-Encoder (VAE)
 Structure schématique d’un auto-encodeur variationnel |
Les Auto-Encodeur Variationnel sont des moyens avancés de réduction de la dimensionnalité spatiale. Au lieu d’encoder une image à un vecteur fixe à la fois, le VAE encode l’ensemble du dataset dans une représentation compressée de sa distribution gaussienne (moyenne et variance). Afin de générer une image, il faut prendre un échantillon aléatoire (le code) dans cette distribution et le passer dans le décodeur.
Lors de l’apprentissage du modèle VAE, il faut optimiser ces paramètres (poids et biais) pour minimiser son risque d’erreur. Cependant, nous ne pouvons pas faire cela à cause du processus d’échantillonnage aléatoire qui coupe la chaîne de la rétropropagation. Afin de contourner ce problème, nous utilisons l’astuce de la reparamétrisation, que nous allons détailler ci-dessous.
La fonction objective :
Durant l’apprentissage d’un modèle VAE, on optimise la fonction objective suivante :

Le premier terme maximise la vraisemblance de la reconstruction du modèle. Tandis que le deuxième terme maximise la similarité (minimise la divergence de Kullback-Leibler) entre le modèle de reconnaissance (encodeurq) et le modèle génératif (décodeurp).
L’astuce de la reparamétrisation :
Le premier terme de la fonction objective demande un échantillonnage stochastique (aléatoire) de z (le code), nous ne pouvons donc pas rétropropager le gradient. Afin de résoudre ce problème, nous allons traiter les vecteurs de la moyenne et de la variance autant que des paramètres du modèle (biais et poids respectivement).
Concrètement, on échantillonne un élément d’une distribution normale centrée réduite ε ∽ N(0,I) puis on le met à l’échelle en multipliant par la variance σ (le poids) de la distribution de l’espace latent, on décale ensuite ces valeurs par le vecteur moyen μ (le biais) z=ε.σ+μ.
 L’astuce de la reparamétrisation |
Grâce à cette astuce, le modèle est maintenant reparamétrisé, ce qui nous donne accès aux paramètres de la distribution afin d’optimiser sa moyenne et sa variance. Ainsi, on maintient le processus d’échantillonnage aléatoire.
une implementation du Variational Auto-Encoder par l'équipe Tensorflow de Google. Vous permettre d'utiliser votre propre architéctures d'encodeur et du décodeur
class CVAE(tf.keras.Model):
def __init__(self, latent_dim):
super(CVAE, self).__init__()
self.latent_dim = latent_dim
self.inference_net = encoder(INPUT_SHAPE, latent_dim)
self.generative_net = decoder(latent_dim)
@tf.function
def sample(self, eps=None):
if eps is None:
eps = tf.random.normal(shape=(100, self.latent_dim))
return self.decode(eps, apply_sigmoid=True)
def encode(self, x):
mean, logvar = tf.split(self.inference_net(x),
num_or_size_splits=2, axis=1)
return mean, logvar
def reparameterize(self, mean, logvar):
eps = tf.random.normal(shape=mean.shape)
return eps * tf.exp(logvar * .5) + mean
def decode(self, z, apply_sigmoid=False):
logits = self.generative_net(z)
if apply_sigmoid:
probs = tf.sigmoid(logits)
return probs
return logits<br />
Auto-encodeurs variationnels comme modèle génératif :
Afin de suréchantillonner notre dataset, on génère des éléments aléatoires de la distribution d’espace latent apprise auparavant via le modèle VAE. Puis, en utilisant le décodeur (le modèle génératif), on construit de nouvelles données, similaires aux données de la classe minoritaire.
La figure ci-dessous représente des exemples d’images générées par le décodeur d’un auto-encodeur variationnel, entraîné sur des données de fissures de murs.
 Exemple d’images générées par le VAE par epoch (1500 epochs) |
Conclusion
Nous venons de découvrir différentes approches d’augmentation de données.
Les Auto-encodeurs variationnels apprennent la distribution de la classe minoritaire, contrairement à SMOTE. En sélectionnant un point aléatoire dans cette distribution, ils génèrent une nouvelle observation pour cette classe.
Comme vous avez pu le constater, les images générées par les VAE ne sont pas de bonne qualité comparées à celles de SMOTE. Néanmoins les fissures générées par VAE ont des nouvelles formes purement synthétiques, que l’on ne trouve pas dans le jeu d’apprentissage.
Pour aller plus loin
Un autre type d’auto-encodeur β-VAE ou “Disentangled Variational auto-encoder” sorti dans les papiers de recherche en 2017 montre des résultats prometteurs et ouvre de nouvelles perspectives. Ainsi, les réseaux contradictoires génératifs (Generative Adversarial Networks par Ian J. Goodfellow en 2014) permettent de générer des données synthétiques d’une qualité proche de la réalité, que nous vous présenterons prochainement sur le Blog.
Références
Variational auto-encoders : www.arxiv.org/pdf/1606.05908.pdf;
Git : www.github.com/SoatGroup/data_augmentation/blob/master/notebooks/02-cvae.ipynb;