
Présentation de GoCD
Un mot d’introduction
À l’ère du DevOps, l’importance accordée aux phases de livraison d’une application est devenue croissante et constitue un enjeu conséquent pour n’importe quelle équipe qui délivre des softwares.
Une phase de delivery va passer par un grand nombre d’étapes qui devront être maîtrisées et exécutées avec soin par toute une population.
L’axe principal, sur lequel devront travailler les équipes, sera la réduction du temps de cycle de ces livraisons, pour que le plus petit changement apporté devienne rapidement accessible et dans de bonnes conditions.
La difficulté va consister alors à conserver un niveau de qualité irréprochable, tout en augmentant la réactivité et le feedback des opérations.
Ainsi, notre objectif pourra se résumer ainsi : Livrer aux utilisateurs un logiciel fonctionnel assurant un haut niveau de qualité, de la façon la plus rapide et la plus sécurisée possible.
Toutes ces réflexions sont tirées d’une part de mon expérience personnelle, mais aussi de mes récentes lectures, et plus particulièrement celle de l’excellent livre Continuous Delivery par Jez Humble et David Farley, dont l’un des chapitres est accessible gratuitement.
Dans cette série de deux articles, nous allons aborder plusieurs thèmes :
- Certains concepts de base du Continuous Delivery
- Un focus sur un outil de CI/CD : GoCD
Et dans un second temps :
- Un retour d’expérience sur l’implémentation de ces concepts et sur l’outil, en mission clientèle
Concepts du continuous delivery
Avant de se lancer dans la présentation de l’outil GoCD, nous allons aborder quelques concepts pour nous permettre de mieux appréhender la suite.
Le pipeline de déploiement
La définition d’un pipeline de déploiement, issue du livre Continuous Delivery est la suivante :
A deployment pipeline is, in essence, an automated implementation of your application’s build, deploy, test, and release process
En d’autres termes, c’est une implémentation dont la principale fonction est l’automatisation des phases du cycle de vie d’une application.
Cette implémentation peut varier d’une organisation à une autre mais les caractéristiques restent les mêmes.
Le principe est simple : chaque changement réalisé sur une application (configuration, code source, etc.) déclenche une nouvelle instance d’un pipeline.
Les étapes les plus communes d’un pipeline seront de construire un binaire de l’application, puis de tester ce binaire, et enfin d’en effectuer la release.
Un pipeline de déploiement sera donc fortement basé sur la notion d’intégration continue.
L’objectif d’un pipeline de déploiement est triple :
- Rendre visible les processus de construction, déploiement, testing, et livraison à tous les membres d’une organisation
- Améliorer le feedback, en notifiant au plus tôt les problèmes liés à ces étapes
- Donner la possibilité aux équipes de déployer à n’importe quel moment, sur n’importe quel environnement, et de façon automatisée
Automatisation & Fréquence
Ces 2 concepts intimement liés sont une partie intégrante du continuous delivery.
Si un processus n’est pas automatisé, il n’est pas reproductible.
Il est donc source d’erreurs et introduit forcément une baisse de qualité.
D’autre part, si des livraisons sont effectuées de manière fréquente, le delta entre ces livraisons sera minimisé.
Par conséquent, le feedback ainsi que les opérations de rollback s’en trouvent grandement améliorés.
Nous retiendrons ceci :
“Une tâche exécutée manuellement est plus lente, et n’est pas auditable”
Le feedback
La rétro-action (appelée aussi feedback) est une composante à ne pas négliger dans l’automatisation de processus.
Elle correspond à l’action en retour d’un effet sur l’origine de celui-ci. (Source : Wikipedia)
Dans un contexte de déploiement continu, le feedback va permettre de s’assurer principalement des points suivants :
- Validité du code source
- Passage des tests unitaires
- Respect des critères de qualité
- Passage des tests d’acceptance fonctionnels
- Passage des tests d’acceptance techniques
- Ouverture à des possibilités de démonstration, d’exploration, d’ouverture anticipée, de campagnes de tests manuels, etc.
En règle générale, voici les 4 composantes d’un software, accompagnées de quelques-uns de leurs principes :
- Un ou plusieurs exécutables
- Doivent être les mêmes dans tous les environnements
- Ne doivent jamais faire l’objet d’un rebuild
- Un ensemble de configurations
- Tout changement sur la configuration doit être consigné
- Et doit être testé sur tous les environnements
- Un environnement hôte
- Au sens large, un environnement peut être considéré comme un groupe de ressources physiques ou virtuelles
- Tout changement doit être également consigné pour pouvoir être rejoué de façon prédictible
- Les data
- Mêmes principes, tout changement doit être consigné, puis rejouable
Quelques autres caractéristiques du feedback à retenir :
- Rapidité du retour d’une opération
- L’automatisation est la clé pour obtenir un feedback rapide
- Une tâche exécutée manuellement est plus lente, et n’est pas auditable
- Implication de toute une population
- Toute personne intervenant dans le cycle des livraisons doit être informée
- Nécessite de diffuser l’information
- Approche de près ou de loin : Développeurs, testeurs, opérationnels, DBAs, managers…
- Permet une réaction au plus tôt
Le Value Stream Mapping
Le Value Stream Mapping (appelé VSM) peut être défini comme étant un outil qui regroupe toutes les actions (à valeur ajoutée ou non) qui amènent un produit d’un état initial à un état final (source : Wikipedia).
Le but d’un VSM est d’avoir une vision simple et claire d’un processus, pour permettre de l’améliorer ensuite.
Le VSM s’inscrit dans une démarche Lean, l’idée étant d’être le plus efficace possible tout en restant simple et en éliminant le gaspillage.
Nous verrons que GoCD restitue très bien ces notions, au moyen de son propre outil de VSM qui nous montre l’efficacité d’une chaîne de déploiement.
Présentation de GoCD
GoCD est outil OpenSource écrit en Java et en Ruby, proposé par ToughtWorks sous licence Apache License 2.0.
Initialement sorti en 2007 sous le nom de Cruise, l’outil a été renommé en 2010.
C’est un outil destiné à aider les équipes à automatiser la livraison continue d’une application.
Il supporte nativement l’intégration des outils de versionning comme Subversion, Git, Mercurial, Perforce et Team Foundation Server.
Tout comme d’autres outils d’intégration continue, il vient accompagné d’un ensemble de plugins dont nous discuterons plus tard.
Nous pouvons le retrouver dans la Table périodique des outils DevOps dans la section Deployment.
Features de GoCD
Les principales features de GoCD sont :
La cohérence des builds de bout en bout
Toute étape d’un pipeline est cohérente dans son enchaînement et dans la production d’artéfacts, par rapport aux étapes précédentes ou suivantes.
La traçabilité des commits
Il sera aisé de retrouver un commit dans n’importe quelle étape des pipelines, et donc de voir concrètement jusqu’où le changement aura été poussé.
Pipeline as code
GoCD offre une WebUI permettant de concevoir des pipelines grâce à des formulaires Web.
Bien que facile d’utilisation, ce procédé reste peu flexible et ne favorise pas la notion de everything as code.
C’est ici qu’intervient un plugin permettant la définition et l’intégration de pipeline en YAML ou en JSON.
Templating
Il est possible grâce à la WebUi d’extraire des templates de pipelines existants et des les réutiliser pour être le plus DRY possible (Don’t Repeat Yourself).
Malheureusement, nous verrons plus tard qu’il n’est pas encore possible de définir ces templates par du code versionné.
Plugins
Un certain nombre de plugins sont disponibles, nous retiendrons celui-ci : gocd-yaml-config-plugin de l’utilisateur Github @tomzo.
À noter qu’il est possible d’écrire son propre plugin, en utilisant l’API Plugin GoCD.
Sécurisation et RBAC
Possibilité de mettre en place une authentification pour accéder à l’interface Web, et de définir des rôles pour le contrôle d’accès.
Cloud native deployment
Intégration native sur les plateformes Cloud Kubernetes avec, entre autres, l’utilisation de Helm Chart pour déployer la solution, plugin de provision d’agents avec élasticité, etc.
Les plateformes Cloud supportées dans la documentation se limitent à Google Kubernetes Engine et AWS, mais il est certainement possible de cibler d’autres plateformes comme Azure Kubernetes Service, la plupart des opérations se réalisant avec l’outil kubectl.
Rollback et réexécution
Possibilité de rejouer des pipelines complets, ou même à un plus fin niveau des stages ou jobs.
Publication d'artéfacts
Chaque étape peut donner lieu à la publication d’artéfacts qui pourront être téléchargés et réutilisés dans les étapes suivantes.
Historique et auditing
Possibilité de consulter l’historique des builds, de visualiser les agents ayant exécuté les opérations, ainsi que de comparer des exécutions entre elles.
Enchaînement d'étapes avec ou sans approbation
Il est possible de définir si une étape doit attendre une approbation manuelle pour poursuivre son exécution.
Déclenchement sur changements de différentes sources
Un pipeline peut être déclenché selon un changement dans la base de code, ou suite à l’exécution d’un upstream.
Variables sécurisées
GoCD offre la possibilité de définir des variables sécurisées, dont le contenu ne sera jamais visible, ni dans la WebUi, ni dans les logs.
Zoom sur l’outil : un modèle serveur / multi-agents
L’architecture GoCD est basée sur un modèle serveur – agents :
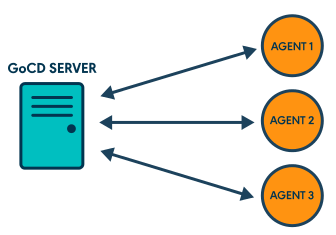
Source : Documentation GoCD
Le serveur
Il contrôle tout l’écosystème, fournit l’interface utilisateur et distribue les jobs aux agents qui se seront enregistrés auprès de lui.
Le serveur n’exécute aucune tâche utilisateur spécifique, c’est-à-dire qu’il ne fera jamais aucun déploiement, ni build, etc.
Il va centraliser tous les éléments de configuration, comme la déclaration des pipelines, les environnements, et d’autres éléments du modèle que nous détaillerons plus tard.
Sa configuration sera en partie stockée dans une structure au format XML, gérée par un dépôt Git interne, ce qui permettra son audit.
Les agents
Ils vont exécuter un ensemble de tâches (déploiements, runs, compilations, etc.) qui auront été préalablement configurées par un utilisateur ou un administrateur.
À l’inverse du serveur, les agents disposent de tout le matériel nécessaire pour réaliser ces actions.
C’est pour cette raison qu’il est nécessaire d’attacher au moins 1 agent au serveur, ce dernier n’étant qu’un “orchestrateur”.
Concepts de bases
GoCD s’articule autour de plusieurs notions que nous allons détailler ci-après.
Le pipeline
Pour rappel, nous avons vu qu’un pipeline est l’implémentation d’un workflow ou d’une partie d’un workflow, qui va permettre de rassembler des étapes et d’en diviser ses phases en plusieurs sous-étapes.
Ces sous-étapes vont se subdiviser en d’autres éléments plus petits : les stages, jobs, et tasks.
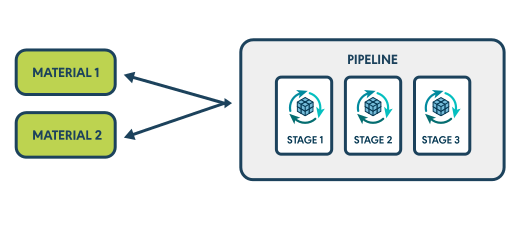
Source : Documentation GoCD
Au-delà de la composition d’un pipeline, il est important de souligner ce qui permet d’en déclencher l’exécution.
Il existe plusieurs façons de déclencher un pipeline dans GoCD :
- Avec les materials
- Manuellement
- Ou périodiquement grâce à une expression Cron
Les materials
Un material est en quelque sorte la cause du déclenchement d’un pipeline.
Il sera typiquement un dépôt de sources (Git, Subversion, etc.) dans lequel un commit provoquera le déclenchement des opérations du pipeline.
Note : GoCD fournit nativement plusieurs connecteurs pour gérer différents dépôts de sources.
Un autre type de material pourra être une dépendance d’un autre pipeline, que l’on appelle un upstream.
Cette dernière configuration permettra d’enchaîner des pipelines de manière automatique, suivant le résultat d’un stage ou d’un job en amont du pipeline.
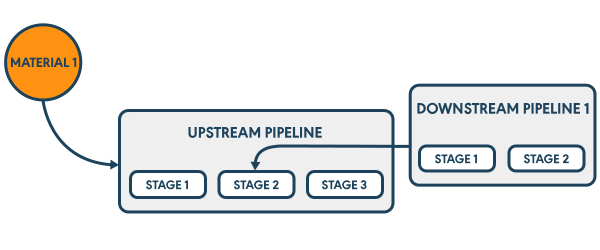
Source : Documentation GoCD
Enfin, GoCD permet la définition d’autant de materials que nécessaire, à condition d’en spécifier au minimum un.
Les stages
Revenons maintenant à la composition d’un pipeline, plus précisément aux sous-étapes qui le composent, appelées des stages.
Un stage GoCD est une collection de jobs, eux-mêmes divisés en tasks.
Chaque stage est exécuté de manière séquentielle et conditionne l’exécution du suivant.
Un stage n’est considéré terminé que lorsque tous ses jobs sont eux-mêmes terminés.
Les jobs
Un job est une unité d’exécution, divisée en plusieurs tâches.
Chaque job au sein d’un stage doit impérativement être indépendant des autres, pour la simple et bonne raison qu’ils seront exécutés de manière non séquentielle, soit potentiellement par des agents différents.
Cette parallélisation constitue un atout intéressant pour la rapidité d’exécution de vos pipelines (à condition bien sûr de disposer d’assez d’agents disponibles pour des exécutions simultanées).
Un job est considéré comme étant terminé lorsque toutes ses tâches ont été elles-mêmes terminées.
Les tâches
Une tâche GoCD est la plus petite unité d’exécution.
Chaque tâche s’exécute séquentiellement avec d’autres tâches au sein d’un même job.
Elle peut être implémentée par une commande, un script, un plugin ou encore la copie d’un artefact d’un pipeline précédent (opération appelée fetch).
Vue d’ensemble
Voici une vue qui récapitule les principaux concepts que nous venons de voir :
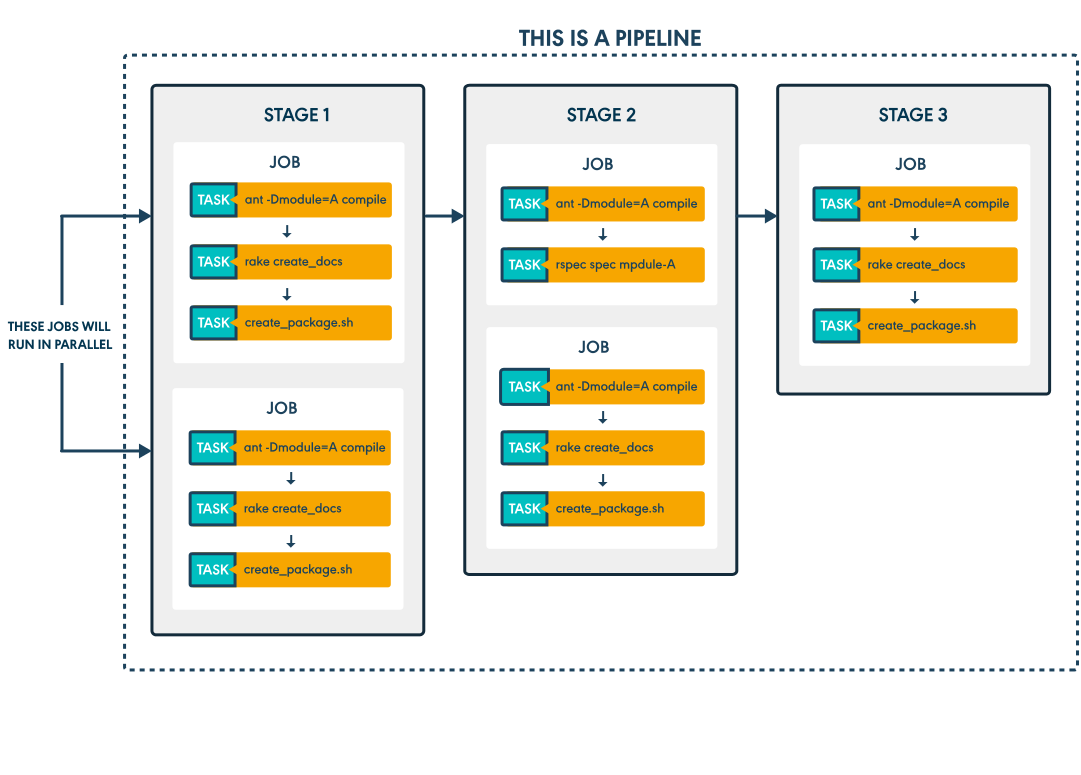
Source : Documentation GoCD
Ce découpage et les règles de parallélisation qui en découlent vont fortement conditionner la manière dont vous concevrez vos pipelines.
Concepts avancés
Maintenant que nous avons vu les principaux concepts qui composent le pipeline, nous allons rapidement aborder d’autres concepts introduits par l’outil.
Les artéfacts
Un artéfact est un élément de build produit par un job, destiné à être exploité ultérieurement.
Il existe deux types d’artéfacts :
- Les artéfacts de build
- Les artéfacts issus des tests (comme les rapports par exemple)
Lorsqu’un artéfact est produit par un agent, il est rapatrié sur le serveur, ce qui le rend accessible à d’autres jobs.
Pour bien comprendre son utilité, prenons l’exemple d’un projet Java construit avec Maven : le fichier JAR produit par le stage de build pourra être déclaré comme artéfact.
Vous pourrez ensuite le récupérer dans un autre stage (grâce à une opération de fetch) pour l’injecter par exemple dans une image Docker contenant un environnement d’exécution Java.
Enfin, un artéfact peut même être récupéré d’un pipeline qui n’est pas l’ancêtre direct de celui qui demande cet artéfact.
Cette gestion simplifiée répond à l’un des concepts du Continous Deployment qui consiste à ne construire un binaire qu’une seule fois.
Les agents
Nous avons vu que l’organisation du modèle GoCD était axé sur une architecture serveur / multi-agents.
Un agent est un processus, soit une instance du service go-agent.
Il contient tous les outils nécessaires à l’exécution des jobs d’un pipeline (binaires java, shell, ssh, maven, etc.).
Ces outils devront bien sûr être installés sur le système qui héberge le service.
Un agent peut être spécialisé en lui affectant des ressources (tags) et/ou un environnement, ce qui permettra de réserver son utilisation à des tâches bien spécifiques.
Le serveur choisira alors un agent grâce à la combinaison de ces deux notions pour lui faire exécuter un travail.
Environnement
Un environnement est un élément du modèle GoCD visant à regrouper des ressources :
- Des pipelines
- Des variables d’environnement
- Des variables d’environnement sécurisées
- Des agents
VSM
Le Value Stream Map permet de visualiser graphiquement et de manière synthétique, une instance de pipeline ainsi que toutes ses dépendances (upstreams et downstreams).
L’idée ici est de représenter le chemin emprunté par un commit, de l’instant où il a été poussé jusqu’à son déploiement en production.

Source : Documentation GoCD
Ce schéma, issu du livre Continous Delivery, représente les interactions entre les dépôts de sources, les dépôts d’artéfacts et les différents stages des pipelines de déploiement.
L’implémentation apportée par GoCD diffère légèrement, principalement au niveau de la terminologie.
Cette fonctionnalité apporte 4 avantages :
- Abstraction : l’implémentation des pipelines n’est pas exposée ici, néanmoins nous avons une bonne vision end-to-end
- Intégrité : les artéfacts sont construits une et une seule fois, puis véhiculés à travers toute la chaîne
- Parallélisation : exécuter différents tests en parallèle sur notre binaire (tests d’acceptance, tests de charges, etc.) permet d’accélérer les opérations, et donc de fournir un feedback rapide
- Traçabilité : notre commit est pleinement auditable, du push à la production
FanIn et FanOut
Ces 2 concepts vont être intimement liés à la parallélisation et à la cohérence de nos pipelines.
Le concept de FanOut permet à un pipeline de posséder plusieurs dépendances aval, appelées downstreams.
Cela permet de déclencher plusieurs opérations parallèles et d’accroître la vitesse de feedback.

Source : Documentation GoCD
À l’inverse, le concept de FanIn indique qu’un pipeline peut avoir plusieurs dépendances amont, appelées upstreams.
Le principe est le suivant : GoCD assure pour un pipeline que toutes ses dépendances en amont sont dans un état cohérent.
Ainsi pour un commit, GoCD assure une chaîne de pipeline cohérente, et ce même si des instances de ce même pipeline ont été exécutées depuis.
Voici un exemple, tiré de la documentation GoCD qui illustre ces 2 concepts :

Source : Documentation GoCD
À noter ici qu’un material identifié par un dépôt de sources peut être une dépendance amont d’un ou plusieurs pipelines, ce qui illustre tout aussi bien le concept de Fan-out
Nous noterons également que ce schéma illustre bien la façon dont GoCD implémente son propre Value Stream Map
En conclusion
Nous avons vu dans cet article quelles étaient les principales composantes du Continuous Delivery, en passant par un focus sur l’outil GoCD et la manière dont il les implémente.
Dans un prochain article, nous aborderons un retour d’expérience en clientèle sur la mise en place de l’outil, en démontrant ses forces et ses faiblesses, puis en terminant par une réflexion sur le maintien de cette solution dans le cadre de ma mission.
Ressources
- Page du produit GoCD
- Documentation GoCD
- Blog GoCD
- Plugins GoCD supportés
- Dépôt Github du plugin de configuration YAML
- Images Docker GoCD sur DockerHub
- Table périodique Devops de XebiaLabs
© SOAT
Toute reproduction interdite sans autorisation de l’auteur.