
Retour sur DevOps Rex 2018

![]() Le mardi 16 Octobre a eu lieu la 3ème édition de la conférence DevOps Rex, la conférence DevOps 100% retours d’expérience. Dédiée aux applications concrètes de la méthodologie DevOps en entreprise, les talks de cette conférence portent sur des cas d’utilisation concrets abordés sous le prisme DevOps, afin de constater ses bénéfices mais aussi ses contraintes et ses limites.
Le mardi 16 Octobre a eu lieu la 3ème édition de la conférence DevOps Rex, la conférence DevOps 100% retours d’expérience. Dédiée aux applications concrètes de la méthodologie DevOps en entreprise, les talks de cette conférence portent sur des cas d’utilisation concrets abordés sous le prisme DevOps, afin de constater ses bénéfices mais aussi ses contraintes et ses limites.
Cette année, Devops REX a investi la prestigieuse Grande Salle du Grand REX ! La conférence s’est tenue sur une journée, basculant entre talks, collations, puis “Social Club” pour finir en beauté cette journée, riche en retours.
La journée a commencé par un petit jeu sympa : “Parle à ton voisin”, petit jeu qui a permis un échange entre les personnes présentes dans la salle. C’est un peu les maîtres-mots des DevOps Rex : partage et échange.
Poser des questions aux speakers à la fin de leur conférence respective a été un jeu d’enfant : en effet l’équipe de DevOps Rex a mis en place une foire aux questions sur le site Sli.do avec le hashtag #DevOpsRex.
Comme maîtresse de cérémonie, c’est Aurore Malherbes qui a été aux commandes cette année, développeuse mobile chez Bam.tech.
Voici un résumé de chaque talk.
La mise en oeuvre du devops dans une entreprise classique IT
Premier talk de la journée, David Herviou (Responsable Cloud) et Philippe Le Guen (Coordinateur Projet) du Crédit Mutuel Arkea nous ont présenté leur situation. Cette dernière est assez “traditionnelle” : des développeurs qui veulent une réduction du time to market, des Ops qui assurent la stabilité de la plateforme de production, et un non alignement des objectifs entre ces deux équipes. Les Ops travaillent selon la méthode ITIL, et la majorité des tâches et des processus n’est pas automatisé.
Plusieurs problématiques se sont posées :
- Côté OPS :
- Pilotage par la qualité de service
- Patch management à intégrer
- Mise en exploitation après la mise en production
- Supervision instrumentée de manière manuelle
- Côté Dev :
- Tout projet commence par la connaissance de la date de mise en production (sans avoir même discuté des tâches à faire)
- Une maturité variable sur le testing
- Exploitation non intégrée
Ils ont décidé de faire une expérimentation DevOps, avec une équipe Pilote, dont l’une des tâches a été de mettre en place un cloud privé (Arkea On Demand). Ils ont donc sollicité des personnes motivées, expertes dans leur domaine. L’équipe s’est construite autour d’une idée forte : communiquer ensemble :
- Mise en place d’un point hebdomadaire
- Intégration et Déploiement continu
- Flexibilité
- Définition d’une matrice de responsabilités
La mise en place de cette équipe n’a pas été sans conséquences :
- Génératrice de frustrations
- Approche pragmatique ?
- Nouvelles frontières de responsabilités
Les deux speakers ont mis en place une méthode d’accompagnement au changement au sein de leurs équipes :
- Présentation de la démarche en plénière
- Présentation des nouvelles fiches métiers
- Création d’un module de formation
- Accompagnement spécifique des OPS (peur que leur métier soit automatisé)
You build it, you run it : no way !! C’est assez clair de la part des speakers. Pas question que le développeur gère la production. Le développeur est responsable du périmètre hors production, et les opérationnels de la production.
Le constat après 1 an et demi :
- Dev vs Dev : certains devs ne sont pas rentrés dans le “DevOps” et n’ont pas pris en main les outils mis à disposition par les Ops. D’autres au contraire ont complètement pris la démarche de la méthode, les outils, l’autonomie.
- Ops vs Ops : certains ops voient cela comme un moyen d’apprendre des nouvelles technologies, langages. D’autres rechignent par peur que leur poste n’évolue pas dans le bon sens.
Finalité de l’histoire : la mise en place du DevOps se fait selon les besoins. Au Crédit Mutuel Arkea, les Ops gardent la main sur la production, les développeurs sur la partie hors production. Le développeur est autonome tant qu’il remplit le contrat fourni par l’ops. L’échange et le partage sont très importants afin de permettre la collaboration entre les Devs et Ops : coaching, office hours, à adapter en fonction des personnes, du contexte. Il ne faut pas hésiter non plus à anticiper la démarche.
Comment la qualité reflète-t-elle nos organisations ?
Joris Calabrese, ex-Head Of Backend Developers chez Meetic est venu nous parler de la qualité, et de l’impact de nos organisations sur celle-ci. Chez Meetic, la qualité n’est rien d’autre que la gestion des risques (changement de composant, mise à jour de la version du système d’exploitation…) : il faut pouvoir gérer les potentielles régressions afin d’assurer un certain niveau de qualité.
La qualité tourne autour de trois axes principaux :
- L’Automatisation : le coût de détection, de correction d’un incident a un impact sur le coût global de l’entreprise (à savoir que le bug en production est plus cher). Il faut donc pouvoir le détecter au plus tôt. L’automatisation des tests va permettre de se concentrer sur des tests plus complexes
- Le temps de cycle : déployer ne doit pas être un événement (des erreurs humaines peuvent apparaître)
- Il faut passer de “changements importants rarement” à “peu de changements souvent”
Le bug flow : pourquoi ? L’expérience de l’utilisateur est dégradée si on laisse beaucoup de bugs en production.

Meetic avait un cycle de livraison de 15 jours : l’équipe de développement développait les nouvelles fonctionnalités par sprint, puis passait cela à une équipe de QA, qui s’occupait des tests sur les différents environnements, puis envoyait la livraison en production. Cette équipe QA était séparée des développeurs. Une fois en production, une équipe de TMA (tierce maintenance applicative) était en charge d’analyser et soumettre les bugs qui arrivaient en production.
Au fur et à mesure, plus il y avait de features (business) développées, plus la charge en matière de test augmentait. Jusqu’au point de ne plus arriver à tenir l’engagement des 15 jours.
“Nos organisations ont un impact sur ce que l’on va produire !” soutient le speaker. Dans l’organisation, les développeurs étaient séparés des équipes QA, mais également des équipes de TMA, et des opérationnels. Pour pallier aux soucis rencontrés, Meetic a procédé à un split organisationnel, par domaine fonctionnel, réunissant les développeurs et les opérationnels.
Cela a eu un impact flagrant sur la qualité (le nombre de bugs présents en production principalement).
Il n’y a pas de recette magique pour le DevOps : il faut faire en fonction des personnes et du contexte présent. Le devops est la capacité de votre organisation à ajouter de la valeur pour vos utilisateurs.
Pour conclure, le speaker finit par : “Pour améliorer la qualité, améliorez votre organisation”
Le Devops par IFS.ALPHA : comment le devops nous a permis de créer des produits commercialisables en seulement 6 mois ?
Ce talk fut présenté par Aly Micki (Solution Designer), Annick Amani (Responsable Practice Testing) et Dino Dona (Référent Automatisation des tests) de chez IFS.ALPHA, filiale de BNP Group. Chez IFS.ALPHA, le but est de trouver de nouvelles façons de travailler avec le groupe BNP.
Côté Organisation, la principale nouveauté fut la création de “Chapters” pour le partage, et l’augmentation du niveau des équipes. Des Chapters ont été créés pour les Scrum Master, les développeurs, les opérationnels. Ces “Chapters” viennent du “modèle” Spotify.
Les trois mots des Speakers autour de cette organisation : Culture, Liberté, Partage.
Au sein de IFS.ALPHA, l’agilité a facilité les échanges entres les individus, les équipes, et a permis d’agir plus rapidement face aux problèmes.
Le DevOps est pour eux l’automatisation ! La première version du pipeline qu’ils ont mis en place permettait de : construire les applications / réaliser les tests techniques / déployer dans différents environnements.
Ce pipeline a bien fonctionné, mais il manquait l’automatisation des tests fonctionnels.
Ils se sont confrontés à certains problèmes de qualité. Leur idée a été de créer une quality gate (pas seulement technique), afin de prendre en compte les aspects réglementaires, de continuité, les sondes, etc. à différents niveaux d’exigence.
Pour finir, chez IFS.ALPHA, la collaboration a été un vecteur d’enrichissement, d’amélioration technique et humaine. Certains développeurs ont évolué vers de nouveaux rôles comme Scrum Master ou Tech Lead.
Table ronde “Qu’avez vous appris depuis votre intervention à DevOps Rex ?”
Nous avons ensuite assisté à une table ronde, qui réunissait des anciens speakers : Thomas Chappe (Product Owner chez Orange), Anna Dao (Développeuse Backend chez Photobox), Maziar Dowlatabadi (Directeur adjoint du Numérique chez Radio France) et Laurent Nyffels (Référent guilde de développement chez AXA). Cette table ronde était menée par Frédéric Simottel, Rédacteur en chef 01 Business Forum.
Chacun de nous a raconté un peu les difficultés et les challenges rencontrés dans nos entreprises autour du DevOps : incompréhension, communication et non responsabilisation sont quelques mots-clés qui sont ressortis de cet échange. Difficultés que l’on a également rencontrées dans les situations des speakers de la journée.
DevSecOps chez Thales Group
Après avoir parlé tests, qualité, organisation, nous voilà avec Raphaël HIET, Architecte logiciel, et Gérald Compoint, Design Authority de chez Thales pour parler sécurité avec le DevOps.
Thales Group est un groupe international orienté sur l’aérospatial, la défense, la sécurité, et le transport terrestre. Sachant que le piratage est une menace importante qui vise un certain nombre de secteurs sensibles comme la défense, Thales prend depuis toujours la mesure très au sérieux. Les menaces émanent d’acteurs étatiques par de puissants groupes de cybercriminels.
Le DevSecOps a commencé depuis 2013 environ, quelques années après le DevOps. En effet, Thales s’est vite rendu compte que la sécurité du système, automatique soit-il, est très importante.
Dans la culture DevOps, on parle souvent du mur de la confusion, entre les développeurs et les opérationnels. Lorsque la philosophie DevOps a été mise en place, ce mur a disparu, mais un nouveau est apparu : le mur entre les Dev(Ops) et l’équipe de Sécurité. En effet aujourd’hui, le RSSI (responsable de la sécurité du système d’information) met en place beaucoup de choses, d’outils, de tests qui cassent la dynamique des DevOps. La sécurité passe par la gouvernance et par le RSSi qui peut donner l’impression d’être un frein à l’innovation et à l’agilité.
Afin de fluidifier le circuit d’échange : la sécurité intervient chez Thales à chaque phase du projet : avant, pendant, après. Par :
- De l’automatisation
- Différents types de tests : analyse statique, dynamique, test d’intrusion…
Pour les développeurs, les incidences de la sécurité sont des contraintes importantes mais la sécurité fait partie de l’ADN de Thales Group. La sécurité devient donc un élément crucial du quotidien du développeur.
Chez Thales, ils ont créé les “Abuser stories” : en tant que hacker, je veux récupérer le mot de passe de la base de données. Ces Stories font partie intégrante du backlog. Le but est vraiment de sensibiliser les développeurs, car la sécurité doit être la préoccupation de toutes les équipes.
Les speakers expliquent que le “mouvement” DevSecOps s’intégrera progressivement dans le DevOps, cela viendra naturellement.
Mise à l’échelle d’une équipe d’astreinte
Damien Pacaud, Director of Engineering & Infrastructure chez Teads, est un spécialiste Infrastructure depuis plus de 12 ans. Il crée et gère des équipes d’astreinte depuis près de 10 ans.
Pour commencer, Damien a expliqué les difficultés qui apparaissent lorsque l’on fait de l’astreinte en France : le cadre légal. En effet, cette contrainte légale et les contraintes organisationnelles sont difficilement compatibles avec l’hyper croissance d’une entreprise comme Teads.
Au départ chez Teads, l’équipe d’astreinte se composait d’une seule personne. Au fur et à mesure, Damien a vite compris qu’il fallait grossir l’équipe d’astreinte, et que plus elle était importante, moins les équipes stressaient, et plus elles voulaient s’impliquer dans l’astreinte.
Qui a envie de se faire réveiller à 3H du matin pour remonter un nœud Cassandra, seul, et sans connaissance Cassandra ?
La confiance a été une clé de la réussite de cette équipe d’astreinte :
- Un ingénieur résout des problèmes
- L’ingénieur ne peut pas tout savoir
- L’ingénieur fait de son mieux
- On accepte l’erreur
Chez Teads, ils ont donc mis en place un système de pair-astreinte. Deux personnes sont appelées afin de réparer le système, deux personnes dont les compétences sont complémentaires (un développeur et un opérationnel par exemple). De part ce fait, les responsabilités sont partagées, ce qui permet de réduire le stress de ces personnes, et d’améliorer leur cadre de travail. Il n’y a pas d’escalade, les deux personnes sont réveillées en même temps par leur robot, et résolvent le problème.
La question d’une documentation propre à l’astreinte s’est également imposée à Damien. Mais force est de constater que les réunions dédiées à ce sujet sautent pour un oui ou un non.
La construction d’une équipe d’astreinte s’est faite par la confiance et le partage des responsabilités, afin de donner envie aux membres des équipes d’y participer.
Damien a également précisé plusieurs points pour l’amélioration des conditions d’astreintes :
- Avoir des développeurs disponibles sur différents fuseaux horaires afin de couvrir l’horloge et éviter d’avoir à réveiller des gens en pleine nuit
- Chaque bug remonté lors d’une astreinte fait l’objet d’un traitement afin d’automatiser sa correction et de réduire au maximum les interventions lors des astreintes
Ces points vont dans le sens que l’astreinte reste une contrainte forte génératrice de stress et sa réduction à un minimum, voire sa disparition, reste l’objectif à long terme.
L’UX a sauvé mon DevOps
Estelle LANDRY, Product Owner, représente l’équipe de développement mais aussi l’UX, puisqu’elle est Product Owner de cette dernière, et François Teychene, Cloud Developer, la partie production “Ops” chez Elium.
Les deux speakers rappellent le fameux mur qui sépare les deux “mondes” Dev et Ops : les développeurs fournissent le code source de leurs applications (exemple très extrême) à la production, qui ne sait pas quoi faire de ce code, comment le builder, le déployer. Et inversement, la production qui propose des améliorations techniques comme par exemple la modification du processus de configuration des applications, dont les développeurs ne s’occupent pas ou très peu.
Sachant que les Ops sont souvent beaucoup moins nombreux face aux développeurs, ils se sentent un peu “seuls” face à l’armée de développeurs.
Premier essai : améliorer la communication :
- Ré analyse des demandes ensemble
- Speed Boat : nos forces, nos faiblesses
Deuxième essai : apporter de la visibilité
- Intégrer les objectifs d’automatisation dans la roadmap
- “Atelier des 5 pourquoi”, afin de comprendre et déterminer la source des problèmes (beaucoup de problèmes entre le moment où les développeurs font un commit et la mise en production du produit)
“Le problème avec la mise en place du DevOps c’est de susciter une volonté et un engagement de la part des deux parties : Dev et Ops”, rappellent les speakers.
Troisième essai : rapporter de l’engagement entre les équipes
- Les 6 Chapeaux de Bono : un exercice de résolution de problèmes voire même de créativité. Le but est de découper en 6 émotions différentes les problèmes de l’individu, ou du groupe : neutralité (les environnements sont instables), émotion (ex : frustration des développeurs), créativité (le développeur gère son intégration), pessimisme (perte de contrôle), optimisme (mise à disposition des environnements par feature), organisation (intégration à la roadmap)
Les speakers ont également essayé de définir les personnes via des Personas. Le but est de définir des profils types dans l’entreprise. Les équipes se sont alors penchées sur un brainstorming afin de définir ces types de profils.

Source : présentation d’Estelle LANDRY
Le bilan ?
Trois piliers se sont dégagés :
- La communication
- La visibilité
- L’engagement
Estelle a évoqué d’autres éléments complémentaires et partagé quelques liens sur le sujet :
- Experience map : Construire une expérience Map / Experience Map 8 Modèles Inspirants
- La technique du “crazy 8”
- Et quelques conseils de livres sur le sujet de l’UX : “Méthodes de Design UX” (par Carine Lallemand) / “Game Storming” (par James Macanufo, Sunni Brown et Dave Gray)
L’idée de parvenir à motiver et à améliorer la communication entre les équipes via ces méthodes issues de l’UX était particulièrement intéressante et en a fait l’un des talks les plus instructifs de la journée.
Faire du DevOps dans une relation contractuelle et commerciale entre client (Dev) et fournisseur (Ops)
Notre speaker Ludovic Piot, Responsable de l’offre Cloud / DevOps chez SOAT est enfin arrivé sur scène.
L’infogérance, c’est laisser les clés de la production mais aussi de la qualité technique de la plateforme. Les besoins du client sont souvent importants et exigeants (tels une Rolls Royce), mais la réalité n’est pas au niveau attendu. En réalité, le cadre mis en place est assez strict et l'”infogérant” possède plusieurs clients, qui veulent tous être “le client qui compte”. L’infogérant a donc une place importante et est un peu le roi du monde.
Avec le temps, la confiance s’érode entre le client et le fournisseur (infogérant), et il arrive même que le client refuse de payer la prestation, car le fournisseur n’a pas réussi à comprendre les contraintes.
Ludovic propose de renverser le modèle pour rétablir la confiance et la collaboration. L’infogérant doit partager avec son client les rituels (points quotidiens, réunions, workshop) et un backlog commun. Ils utilisent alors des outils de communication et de gestion de projet. Les choix techniques sont également partagés et discutés.

Source : présentation de Ludovic PIOT
Le fournisseur doit autant que possible utiliser les outils du client, ce qui permet de rassurer ce dernier, et de mieux collaborer. Au pire, le fournisseur doit pouvoir proposer de nouveaux outils dans le cadre de leur collaboration.
Afin d’être alignés, le client et le fournisseur doivent également mettre en place un document contractuel (le contrat) qui décrit à la fois l’opérationnel, la réalité du moment mais aussi la cible à atteindre. Ce document doit évoluer au fil du temps puisque la situation évolue.
La relation client / fournisseur réside fortement dans le lien de confiance qui les unit, ainsi que dans leur niveau de collaboration.
Échouer pour mieux réussir : les GameDays chez Datadog
Ce talk fut présenté par Léo Cavaillé, Lead SRE chez Datadog. Chez Datadog, comme son nom l’indique, on traite de la donnée. Des milliards de données chaque jour, ce qui implique que le système doit être fiable, et résister à n’importe quel événement extérieur (arrêt d’un serveur, connexion à la base de données inopérante…).
Afin de tester de multiples scénarios “catastrophe”, quoi de mieux que de les mettre en pratique soi-même, afin d’anticiper et de réagir au mieux le jour où cela arrive vraiment. C’est ce que nous propose Datadog : les Game Days.
Le concept est assez simple :
- On prépare un scénario de chaos pour un service.
- On exécute le scénario (et on observe ce qui se passe).
- On met en place des actions d’amélioration afin de mieux gérer la situation lorsque l’incident se produira de manière non volontaire.

L’enjeu des GameDays est de mettre sur le grill les équipes (Dev et Ops) avec une situation catastrophique simulée. Afin d’obtenir toutes les compétences nécessaires pour résoudre la situation, un Dev et un Ops sont réunis sur le Game Day.
Le speaker préconise d’ailleurs d’effectuer ces Game Days régulièrement, pour que cela soit un vrai rituel (voire des tâches dans le backlog) afin de tester le système en production. On peut même rejouer plusieurs fois le même scénario pour vérifier que les équipes ont bien appris des dernières fois, et que la situation est mieux maîtrisée.
Ce qui est important, souligne le speaker, c’est la documentation de ces GameDays : documenter les scénarios de catastrophes, afin qu’ils soient plus simples à jouer les prochaines fois (commandes à exécuter, serveur mis à mal…), et documenter également ce qui a été détecté et mis en place pour résoudre la situation. Cela permettra aux futures équipes de connaître la situation de crise, qui peut éventuellement arriver.
Pour conclure : l’échec est enrichissant et doit être partagé, célébré avec les équipes de Dev/Ops.
Keynote de clôture : un sujet toujours d’actualité “Les femmes dans la Tech”
La maîtresse de cérémonie Aurore Malherbes termine la journée en beauté, pour parler des Femmes dans la tech. Le constat est assez clair, et on le répète assez souvent pour bien le connaître : seulement 26% des personnes qui travaillent dans la tech sont des femmes. Et seulement 6% sont des femmes qui travaillent dans la technique (développeuse, ops) souligne la speakeuse.
En effet, si nous jouons au jeu “cite-moi le plus de femmes CTO”, nous n’allons pas très loin, comparé à la longue liste des CTO de sexe masculin.
Dans les années 70, il n’y avait aucun “problème” souligne Aurore. Et c’est réellement au début des années 80 que la chute est importante : la sortie du premier ordinateur personnel.
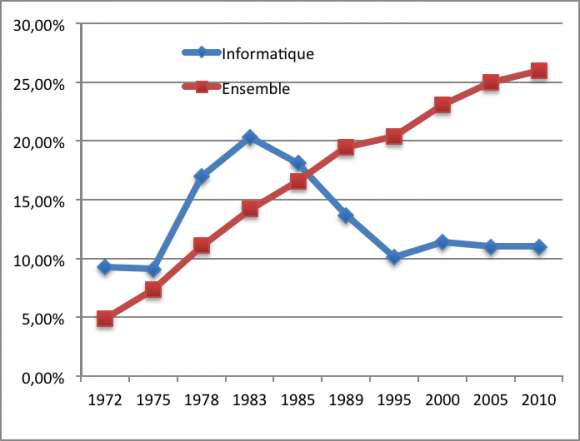
Extrait de “Effet de genre : le paradoxe des études d’informatique”, Isabelle Collet (Tic&Société, 2011)
Et à y regarder de plus près, rien n’a été fait à l’époque pour inciter la gente féminine à s’intéresser à ce dernier : toutes les publicités montraient des hommes à l’écran, les jeux de ces ordinateurs étaient fortement tournés pour le sexe masculin.
Aurore propose donc de faire un P.I.S.C.A.R (venant du Lean) :
- Problème : chiffre anormal par rapport à un standard. Si nous considérons qu’il y a 50% de femmes sur terre, comparé à 26% dans la Tech, il y a effectivement un écart par rapport au standard (50%).
- Impact. L’exemple pris par Aurore est le suivant : les entreprises dans la tech ont du mal à recruter. En effet, entre les arrivées théoriques et la réalité, il y a toujours un écart. Imaginez s’il y avait 50% de femme dans la tech, cela aurait un impact bénéfique sur les recrutements.
- Situation : le sujet est une personne (femme), et l’on décrit sa vie :
- Ouverture au monde par les loisirs, l’école
- Premier contact avec le monde professionnel
- Entrée en études supérieures
- Candidature pour un premier job
- Premier jour au travail

- Causes : décrites en haut de l’image
- “Les jouets tech sont pour les garçons”
- “Je connais pas de femmes CTO”
- “Il n’y a pas de filles en école d’ingénieurs”
- “Je n’y arriverai jamais” (proverbe féminin)
- Actions : beaucoup de choix possibles dans les actions que l’on peut faire pour améliorer la situation
- Jeu de codage dès le plus jeune âge
- Donner des exemples dans la vraie vie
- Donner des modèles
- Coacher et Challenger
- Résultats : Aurore lance un défi aux spectateurs dans la salle :
Chacun d’entre vous contribue à l’arrivée dans la tech d’une fille avant le 16 Octobre 2019 (date de Devops Rex pour l’année prochaine).
Le défi est lancé, à nous de jouer !
Conclusion
Après cette journée d’échange, de partage, de retours d’expérience, la journée s’est terminée avec un “Social Event” dont le but fut de discuter participants/speakers autour d’un buffet et d’une bonne bière. Les speakers étaient disponibles pour approfondir les sujets et répondre aux questions qui n’avaient pas pu être posées pendant la journée.
Les slides sont disponibles ici et vous pouvez revoir les vidéos des années précédentes sur la chaine Youtube de la conférence (à la date de publication, les vidéos 2018 ne sont pas encore disponibles).
© SOAT
Toute reproduction est interdite sans autorisation de l’auteur.