
Benchmark : java lambda vs. classe anonyme


Depuis l’arrivée de Java 8 l’année dernière, et notamment des lambda expressions, nous avons découvert de nouveaux patterns de code : en effet, même si java reste un langage orienté objet, il sera désormais teinté de programmation fonctionnelle ! Il s’agit là bien sûr d’une évolution majeure du langage (au même titre qu’avait pu l’être en son temps java 5), qui va changer notre façon d’écrire un programme en java ; mais c’est sous un autre angle que je vais étudier aujourd’hui cette nouveauté du langage : celui de la performance ! A vos benchmarks, prêts… partez !
Lambda, es-tu anonyme ?
Avant toute chose, un petit rappel, s’il en convient, sur les lambdas. Il existe déjà beaucoup de littérature sur le sujet ; je ferai donc la version courte :
lambda expression = fonction anonyme
Ah ! Rien de bien compliqué alors ! Qu’y a-t-il de révolutionnaire dans tout cela, me direz-vous ? Il y a déjà bien longtemps que java dispose des classes anonymes, qui nous permettent d’écrire des fonctions anonymes (une classe anonyme avec une seule méthode). Les Runnable et Callable en sont de parfaits exemples !
callable = new callable<String>() {
public String call() {
return “Hello world !”;
}
};
… Qui devient une lambda :
Callable<String> f = () -> "hello world !";
Mais alors, pourquoi avoir introduit les lambdas ? S’agit-il simplement de “sucre syntaxique” pour économiser les lignes de code ?
Et bien oui, les lambdas allègent le code… MAIS PAS QUE ! Et c’est ce que Brian Goetz nous avait promis lors de sa conférence Lambda : a peek under the hood : en effet, elles sont également plus performantes que les classes anonymes.
Don’t guess, measure !
 « Les lambdas, ça poutre ! » C’est en substance la conclusion que l’on retiendra de cette conférence, corroborée par ailleurs par les benchmarks réalisés par d’autres éminents spécialistes de chez Oracle, tels que Sergey Kuksenko (voir Jdk 8 : Lambda performence study).
« Les lambdas, ça poutre ! » C’est en substance la conclusion que l’on retiendra de cette conférence, corroborée par ailleurs par les benchmarks réalisés par d’autres éminents spécialistes de chez Oracle, tels que Sergey Kuksenko (voir Jdk 8 : Lambda performence study).
La confiance n’excluant par le contrôle (même envers des éminences dont la réputation n’est plus à faire), j’ai voulu mesurer et vérifier, avec mes petits yeux, sur un cas pratique, ce que les lambdas allaient pouvoir me faire gagner en performance.
On n’est pas que des code-bytes
J’ai donc sorti mon JMH de ma boite à outils, pour benchmarker un cas pratique : le tri d’un tableau, en utilisant les Comparator, sur des beans simples, modélisant des personnes :
public class Personne {
String nom;
String prenom;
...
}
Sur le banc d’essai, plusieurs implémentassions…
L’expérience témoin
Tout d’abord, le code qui me servira de référence, utilisant une classe anonyme, compilée avec un JDK7 et exécutée avec un JRE 7 :
@Benchmark
public void anonymous_class(PersonnesContainer c, Blackhole blackHole) {
Arrays.sort(c.personneToSortArray,
new Comparator<Personne>() {
public int compare(Personne p1, Personne p2) {
int nomCompaison = p1.getNom().compareTo(p2.getNom());
return (nomCompaison != 0) ? nomCompaison : p1.getPrenom().compareTo(p2.getPrenom()) ;
}
});
blackHole.consume(c.personneToSortArray);
}
Le petit frère du témoin
Il s’agit simplement du même code, mais compilé et tournant cette fois avec un JDK/JRE 8 :
@Benchmark
public void anonymous_class(PersonnesContainer c, Blackhole blackHole) {
Arrays.sort(c.personneToSortArray,
new Comparator<Personne>() {
public int compare(Personne p1, Personne p2) {
int nomCompaison = p1.getNom().compareTo(p2.getNom());
return (nomCompaison != 0) ? nomCompaison : p1.getPrenom().compareTo(p2.getPrenom()) ;
}
});
blackHole.consume(c.personneToSortArray);
}
Le challenger
Sujet principal du benchmark : je remplace la classe anonyme par une expression lambda :
@Benchmark
public void lambda(PersonnesContainer c, Blackhole blackHole) {
Arrays.sort(c.personneToSortArray,
(p1, p2) -> {
int nomCompaison = p1.getNom().compareTo(p2.getNom());
return (nomCompaison != 0) ? nomCompaison : p1.getPrenom().compareTo(p2.getPrenom());
});
blackHole.consume(c.personneToSortArray);
}
La cousine du challenger
Preuve que même sans classe, on peut être distingué, la “méthode référence” accompagnée de l’interface Comparator et de ses méthodes statiques comparing() et thenComparing(), est selon moi la manière la plus élégante d’exprimer simplement les critères d’un tri :
@Benchmark
public void method_reference(PersonnesContainer c, Blackhole blackHole) {
Arrays.sort(c.personneToSortArray,
Comparator.comparing(Personne::getNom)
.thenComparing(Personne::getPrenom));
blackHole.consume(c.personneToSortArray);
}
Les mêmes, le parallélisme en plus
Le JDK8 débarque avec une nouvelle méthode de tri parallèle utilisant l’ex-fork/join pool de java7, qui tire profit du multi-coeurs :
@Benchmark
public void parallel_anonymous_class(PersonnesContainer c, Blackhole blackHole) {
Arrays.parallelSort(c.personneToSortArray,
new Comparator<Personne>() {
public int compare(Personne p1, Personne p2) {
int nomCompaison = p1.getNom().compareTo(p2.getNom());
return (nomCompaison != 0) ? nomCompaison : p1.getPrenom().compareTo(p2.getPrenom()) ;
}
});
blackHole.consume(c.personneToSortArray);
}
@Benchmark
public void parallel_lambda(PersonnesContainer c, Blackhole blackHole) {
Arrays.parallelSort(c.personneToSortArray,
(p1, p2) -> {
int nomCompaison = p1.getNom().compareTo(p2.getNom());
return (nomCompaison != 0) ? nomCompaison : p1.getPrenom().compareTo(p2.getPrenom());
});
blackHole.consume(c.personneToSortArray);
}
@Benchmark
public void parallel_method_reference(PersonnesContainer c, Blackhole blackHole) {
Arrays.parallelSort(c.personneToSortArray,
Comparator.comparing(Personne::getNom)
.thenComparing(Personne::getPrenom));
blackHole.consume(c.personneToSortArray);
}
Les mêmes, nourris au Stream
Grosse nouveauté du JDK8, l’API Stream (introduite pour faire du map/filter/reduce) permet également de faire du tri. Même s’il ne s’agit plus d’un tri “sur place”, j’ai voulu voir, par curiosité, ce que cela donnait côté performance. On reprend donc les mêmes, mais nourris au Stream :
@Benchmark
public void stream_anonymous_class(PersonnesContainer c, Blackhole blackHole) {
Object[] sortedPersonnes = Arrays.stream(c.personneToSortArray)
.sorted(new Comparator<Personne>() {
public int compare(Personne p1, Personne p2) {
int nomCompaison = p1.getNom().compareTo(p2.getNom());
return (nomCompaison != 0) ? nomCompaison : p1.getPrenom().compareTo(p2.getPrenom()) ;
}
})
.toArray();
blackHole.consume(sortedPersonnes);
}
@Benchmark
public void stream_lambda(PersonnesContainer c, Blackhole blackHole) {
Object[] sortedPersonnes = Arrays.stream(c.personneToSortArray)
.sorted((p1, p2) -> {
int nomCompaison = p1.getNom().compareTo(p2.getNom());
return (nomCompaison != 0) ? nomCompaison : p1.getPrenom().compareTo(p2.getPrenom());
})
.toArray();
blackHole.consume(sortedPersonnes);
}
@Benchmark
public void stream_method_ref(PersonnesContainer c, Blackhole blackHole) {
Object[] sortedPersonnes = Arrays.stream(c.personneToSortArray)
.sorted(Comparator.comparing(Personne::getNom)
.thenComparing(Personne::getPrenom))
.toArray();
blackHole.consume(sortedPersonnes);
}
Les mêmes, nourris au parallel Stream
Quitte à faire du Stream, faisons du parallel Stream !
@Benchmark
public void parallel_stream_anonymous_class(PersonnesContainer c, Blackhole blackHole) {
Object[] sortedPersonnes = Arrays.stream(c.personneToSortArray)
.parallel()
.sorted(new Comparator<Personne>() {
public int compare(Personne p1, Personne p2) {
int nomCompaison = p1.getNom().compareTo(p2.getNom());
return (nomCompaison != 0) ? nomCompaison : p1.getPrenom().compareTo(p2.getPrenom()) ;
}
})
.toArray();
blackHole.consume(sortedPersonnes);
}
@Benchmark
public void parallel_stream_lambda(PersonnesContainer c, Blackhole blackHole) {
Object[] sortedPersonnes = Arrays.stream(c.personneToSortArray)
.parallel()
.sorted((p1, p2) -> {
int nomCompaison = p1.getNom().compareTo(p2.getNom());
return (nomCompaison != 0) ? nomCompaison : p1.getPrenom().compareTo(p2.getPrenom());
})
.toArray();
blackHole.consume(sortedPersonnes);
}
@Benchmark
public void parallel_stream_method_ref(PersonnesContainer c, Blackhole blackHole) {
Object[] sortedPersonnes = Arrays.stream(c.personneToSortArray)
.parallel()
.sorted(Comparator.comparing(Personne::getNom)
.thenComparing(Personne::getPrenom))
.toArray();
blackHole.consume(sortedPersonnes);
}
Contexte du benchmark
J’ai réalisé ce benchmark JMH en mode AverageTime, sur 100 itérations de 100 ms chacune, et une phase de “warmup” équivalente. Afin de ne pas re-trier un tableau déjà trié par l’invocation précédente (puisqu’il s’agit d’un tri sur place) j’ai utilisé une fixture pour réinitialiser l’ordre des éléments du tableau entre chaque invocation. Comme nous le verrons dans les résultats, la durée d’une invocation étant d’une part suffisamment longue, et d’autre part le temps de réinitialisation du tableau suffisamment court, les valeurs mesurées ne devraient pas être significativement biaisées par le benchmark lui-même. De plus, la marge d’erreur obtenue sur les mesures est satisfaisante (de l’ordre de quelques pourcents).
Par ailleurs, afin de prendre en compte l’impact de la taille du tableau sur les différentes méthodes de tri, j’ai paramétré mon benchmark pour faire varier la taille du tableau de 10 à 500000 items à trier.
Précisons enfin que le benchmark a été exécuté sur la machine/JVMs suivante :
JDK7 (jdk1.7.0_75) et JRE7 oracle 64bits
java version "1.7.0_75" Java(TM) SE Runtime Environment (build 1.7.0_75-b13) Java HotSpot(TM) 64-Bit Server VM (build 24.75-b04, mixed mode)
JDK8 (jdk1.8.0_51) et JRE8 Oracle 64 bits
java version “1.8.0_51”
Java(TM) SE Runtime Environment (build 1.8.0_51-b16) Java HotSpot(TM) 64-Bit Server VM (build 25.51-b03, mixed mode)
CPU Intel(R) Core(TM) i5-2500K CPU @ 3.30GHz
Système Ubuntu 15.04 64 bits (kernel 3.19.0-31-generic)
Il ne reste plus qu’à donner le top départ !
NB : Les sources java du benchmark sont disponibles sur github.
Résultats des courses
Comme vous allez le voir, les résultats de ce benchmark sont assez surprenants. Les logs complètes sont disponibles ici pour java 7 et là pour java 8. En voici une synthèse…
Java 7 vs. Java 8
Commençons par comparer les résultats de la classe anonyme de java 7 à ses challengers de java 8, à savoir :
- la classe anonyme (code identique mais JRE8)
- la lambda
- la méthode référence

Globalement, on constate que :
- la classe anonyme de java 8 est meilleure que celle de java 7 de 4,4% en moyenne.
- De même, pour la lambda avec un gain moyen de 4%.
Le JRE8 apporte donc un gain immédiat : la classe anonyme de java 8 et la lambda donnent en revanche des temps similaires (parfois même légèrement moins bon pour la lambda !). Par ailleurs, la méthode référence est toujours plus lente, de 8,7% en moyenne.
Tri parallèle
Ce benchmark nous donne également une comparaison du tri parallèle de la nouvelle méthode Arrays.parallelSort() de java 8, avec son équivalent historique non parallélisé toujours présent dans le JDK8 (Arrays.sort()) :
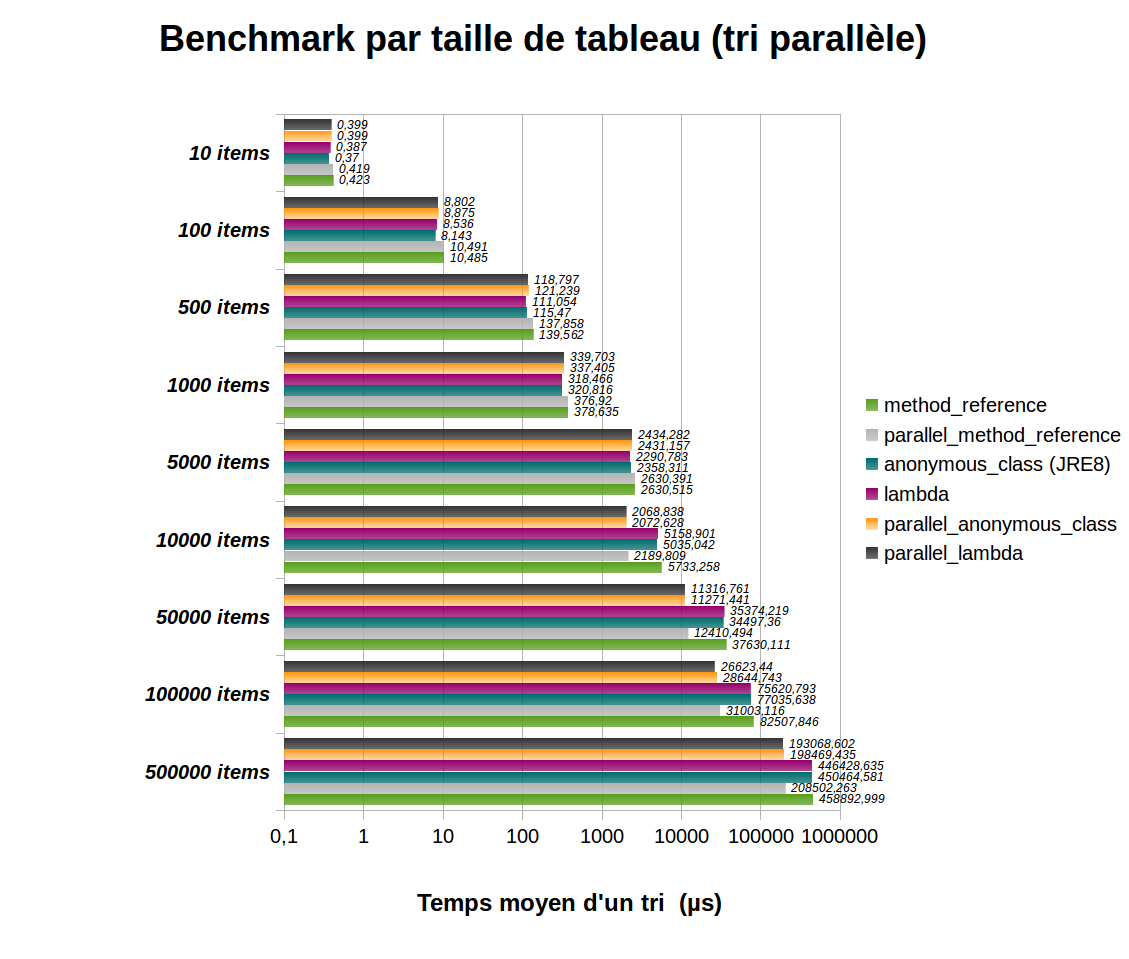
Comme on peut le voir :
- sur les tris de moins de 5000 items, les tris parallèles se sont montrés un peu plus lents que leurs homologues mono-thread (de 5 à 6% en moyenne), sauf pour la méthode référence qui donne des résultats similaires, parallélisée ou non, mais encore une fois moins bons qu’avec une classe anonyme ou une lambda.
- Avec 10000 items et plus en revanche, la parallélisation apporte un gain de performance de 60% en moyenne !
API Stream
Dans le monde de java 8, l’utilisation de l’API Stream pour trier un tableau, au lieu de la méthode Arrays.sort(), nous donne les performances suivantes :

Pas de contestation possible : l’utilisation d’un Stream uniquement pour réaliser un tri est contre-performante. Plus le tableau est petit, plus les performances se dégradent. Néanmoins, plus le tableau est grand, plus l’écart se réduit.
Stream parallèle
Pour être exhaustif, j’ai également comparé le tri parallèle du JDK8 (Arrays.parallelSort()) avec le tri parallèle via l’API Stream :

Alors que l’implémentation de Arrays.parallSort() a l’intelligence de ne pas paralléliser le tri sur des tableaux trop petits (limitant ainsi la casse), le Stream parallèle quant à lui est clairement contre-performant sur les petits tableaux (jusqu’à 8 fois plus lent sur ces tris !). Plus le tableau est grand, plus l’écart de performance se réduit.
Conclusion
Nous venons de réaliser un benchmark comparatif entre java 7 et java 8, sur une opération simple en java : le tri d’un tableau. Alors, java 8 plus performant ou pas ?
Tout d’abord, la 1ère bonne nouvelle, c’est que migrer son application java en version 8, même sans adaptation de code, améliore la performance (gain de l’ordre de 4% en moyenne mesuré sur l’exemple du tri).
L’autre bonne nouvelle est l’apparition dans le JDK8 du tri parallèle sans fork/join pool, par la méthode Arrays.parallelSort(), qui diminue significativement le temps d’un gros tri.
Enfin, le dernier constat que j’ai pu faire à travers ce benchmark est que, contrairement à ce que j’espérais, l’utilisation d’une lambda à la place d’une classe anonyme n’a pas amélioré la performance d’un tri (temps significativement identiques). L’explication semblant la plus probable selon moi est que les gains de performances annoncés sur les lambdas ne touchent jusqu’à aujourd’hui que le “linkage” et la “capture” de la lambda (correspondant au “class loading” et à l’instanciation de la classe), mais pas son “Invocation”. Or, l’utilisation d’un Comparator dans une méthode de tri, ne nécessite qu’une seule opération de “linkage” et “capture”, puis de nombreuses (n.log(n)) “invocations”. Donc pas d’amélioration majeure coté performance sur ce cas d’utilisation !
Néanmoins, les expressions lambda étant encore bien jeunes dans le monde java, on est en droit d’espérer des optimisations notables sur leur invocation, dans les prochaines versions de JVM (optimisations qui seront prises en compte dynamiquement, sur un bytecode java déjà “lambda ready”, grâce à l’utilisation d’invokeDynamic !).
Pour terminer enfin sur le sujet des lambdas (et l’argument est d’autant plus valable pour les ”méthodes références”), je conclurai de la manière suivante : même si le gain en performance n’est pas, à ce jour, à la hauteur de mes espérances, cela n’a pas d’importance, leur principale qualité restant, à mes yeux, qu’utilisées à bon escient elles améliorent la lisibilité et la maintenabilité du code !