
Redécouvrons le développement web en Java avec Play! – Partie #1 : Enfin un framework web Java
![]() Je voudrais vous parler d’un framework web qui fait de plus en plus parler de lui : Play! Framework. Cette présentation est axée sur l’usage de Play! par un développeur Java. Cependant il est important de garder à l’esprit que dans Play! l’aspect important n’est pas Java mais plutôt le couple JVM + Web. Ainsi dans la dernière version (2) de Play! , le core du framework a été redéveloppé en Scala, également choisi comme langage de templating.
Je voudrais vous parler d’un framework web qui fait de plus en plus parler de lui : Play! Framework. Cette présentation est axée sur l’usage de Play! par un développeur Java. Cependant il est important de garder à l’esprit que dans Play! l’aspect important n’est pas Java mais plutôt le couple JVM + Web. Ainsi dans la dernière version (2) de Play! , le core du framework a été redéveloppé en Scala, également choisi comme langage de templating.
Ce billet est le premier d’une série consacrée à Play! 2. Ce n’est pas tutoriel et le but n’est pas vraiment de montrer du code. Il ne s’agit pas non plus d’une présentation détaillée du framework, contrairement au livre Play for Java référencé ci-dessous dont je me suis largement inspiré et recommande la lecture. L’objectif est de présenter le framework en soulignant ses atouts et ses différences avec Java EE. Le prochain billet, sera quant à lui, un tutoriel sur la création et la mise en ligne d’une webapp Play!
Play! et Scala
Avant toute chose, il convient de comprendre la place de Scala dans Play!
Play! est écrit en Scala
Lors du passage de la version 1 à la version 2, le framework a été réécrit en Scala. Le choix de Scala est justifié par les possibilités offertes par ce langage. Par exemple, l’accès aux bases de données pour les développeurs Scala est simplifié grâce à ANORM (Anorm is Not an Object Relational Mapper) qui est une couche au-dessus de JDBC. ANORM permet d’utiliser la puissance de Scala pour utiliser directement JDBC sans passer par les ORM.
Dans la première version de Play!, les templates étaient écrits en Groovy. Mais dans la version 2, c’est Scala qui a été choisi. Dans la pratique, le développeur Java n’est pas obligé de connaitre Scala pour écrire des templates Play! . Il a juste besoin de connaitre :
- les boucles
- les structures conditionnelles
- les imports de classe
L’usage de Scala, qui est “type safe“, et la compilation des templates est particulièrement utile pour le débogage et les tests unitaires. Je reviendrai sur ce point-ci dans la suite.
Coexistence d’une API Java et d’une API Scala
Même si le framework a été réécrit en Scala, l’API existe sous deux versions : une en Java et une seconde en Scala. Si on en croit les concepteurs de Play! ces deux versions sont fonctionnellement équivalentes. On n’est donc pas obligé de se mettre à Scala pour développer en Play!.
Play! et le pattern MVC
Play! est un framework MVC. Les sources sont situées dans le dossier /app et dans ce dossier, par convention (CoC), on définit les sources dans trois packages : models, views et controllers. Il est possible, en plus de ces packages, de définir d’autres packages pour un besoin spécifique. Par exemple, on pourrait définir un package security.
Les objets du domaine
Ils sont définis dans le package models. En pratique il s’agira de POJOs utilisant des annotations JPA ou héritant de classes spécifiques dans le cas où l’on utilise EBeans.
Les vues
Ce sont des fichiers suffixés “.scala.html“. Ces fichiers doivent être stockés dans le package views.
@(pageTitle: String)(content: Html)
<!DOCTYPE html>
<html>
@_header(Messages("application.title"))
<body>
<div id="dataCollectForm">
<h1>@pageTitle</h1>
@content
</div>
</body>
@_footer()
</html>
Dans l’exemple ci-dessus, nous définissons un template qui reçoit deux paramètres : “pageTitle” de type String et “content” de type play.api.templates.Html . Dans le même template, nous incluons le fragment header. Il faut noter deux choses au sujet de ce fragment _header :
- ce fragment est un fichier nommé “_header.scala.html”
- ce fragment prend lui-même un paramètre de type String
À la fin de la page, un second fragment “_footer” est inclus. Ce second fragment n’attend aucun argument en entrée. Pour inclure le fragment, tout se passe comme si on appelait un constructeur au sens Java. Cette manière d’inclure un template dans un autre ne nécessite aucun framework supplémentaire.
On peut également remarquer que ces deux fragments ont des noms préfixés de “_”. Cela signifie que ces fragments ne peuvent pas être accéder directement à moins d’être inclus dans un autre template.
Pour finir avec les templates, attardons-nous sur la portion ci-dessous pour étudier le fonctionnement du caractère spécial “@”.
Ce caractère “@” est l’élément central des templates Play! 2. Il marque le début d’une expression Scala à évaluer. Le parseur est “intelligent” et arrive à identifier la fin des blocs Scala. Ainsi la portion “@pageTitle” sera remplacée par sa valeur.
Les contrôleurs
Ils sont situés dans le package controllers. Si l’on souhaite changer le nom de ce package, il faut alors spécifier le nouveau nom dans le fichier de configuration.
À la place de l’API servlet, Play! propose une nouvelle API pour gérer les dialogues HTTP. Ainsi, si “doSomething” est une méthode d’un contrôleur, on pourrait écrire :
public static Result doSomething() {
return ok();//Le browser va recevoir une réponse HTTP de code 200
//return badRequest(); //Le browser va recevoir une réponse HTTP de code 400
//return notFound();//Le browser va recevoir une réponse HTTP de code 404
}
A noter que les méthodes ci-dessus sont surchargées et qu’il est possible de leur passer un paramètre de type play.api.mvc.Content qui possède deux champs : “type” et “body”. Ceci permet de manière intuitive, et en une ligne, de spécifier au browser qu’on lui envoie une réponse HTTP avec un code, un message et le type de données renvoyé.
On peut voir que là où l’API servlet a voulu masquer HTTP, considéré comme complexe, Play! choisit d’exposer clairement toutes les spécificités de HTTP.
Définition des routes
Le fichier des routes est un contrôleur de premier niveau. Il identifie le contrôleur concerné par la requête et l’appelle. Ce fichier “routes” est situé dans le dossier /conf. Il est analogue à ceux que l’on peut retrouver au niveau des frameworks Struts et JSF même s’il n’est pas identique.
Le fichier routes est déclaratif et fait correspondre à une requête HTTP donnée (type + path), une action d’un contrôleur.
Voici un exemple d’une ligne de ce fichier :
GET /statistiques controllers.StatisticsCtrl.defaultQuery()
Dans l’exemple ci-dessus, lorsque le serveur recevra une requete de type GET à partir du chemin /statistiques, la méthode defaultQuery du contrôleur StatisticsCtrl sera appelée.
Quelques éléments différenciants de Play!
Gestion des dépendances
Les dépendances sont définies dans le fichier /project/Build.scala. Ce fichier permet de définir la version et le nom du projet ainsi que ses dépendances. Par exemple, dans la ligne ci-dessous, on définit une dépendance pour la version 3.0 de Apache commons-math3.
"org.apache.commons" % "commons-math3" % "3.0"
Ceux qui sont habitués à Maven ne devraient pas être dépaysés. Play! interagit d’ailleurs avec les repositories Maven.
Notons, pour les inconditionnels de Maven, qu’il existe un module qui permet d’utiliser Maven sur un projet Play! ; mais je ne l’ai pas expérimenté donc je n’en parlerai pas davantage.
Play! est stateless
Le web est stateless car le web est bâti sur HTTP qui est un protocole sans état. Le principe d’un état géré coté serveur est donc à l’encontre des fondements du web. Malheureusement dès les origines de Java EE et les débuts de l’API Servlet, tout a été fait pour fonctionner en mode statefull.
C’est cette incohérence qui est la cause de nombre de problèmes dans le développement web en Java. Par exemple, lorsque la charge augmente et qu’on doit scaler en ajoutant un serveur, il arrive fatalement un moment où la synchronisation de la session entre les différents serveurs ne se déroule pas comme il faudrait. Si on respecte le caractère stateless du web, on n’a pas ce genre de problème.
Play! est stateless et oblige le développeur à penser stateless ; ce qui peut être un peu perturbant au début pour un développeur Java EE. En retour, le framework garantit une scaliabilité aisée et quasi infinie.
Play! et le session timeout
Parce que Play! est stateless, il n’y a pas de limitation technique à la durée de la session. En effet, dans le cas d’une application Java EE “classique”, le timeout est surtout utilisé pour libérer de la ressource côté serveur.
Lorsqu’on utilise Play!, on n’est plus obligé par le framework de limiter la taille de la session. En pratique la session finit quand l’utilisateur ferme son browser. Dès lors, la durée de session redevient ce qu’elle devrait être : une problématique métier. Il appartient au fonctionnel de définir la durée de la session en fonction de critères qui lui sont propres. Par exemple, le fonctionnel peut souhaiter que pour une application bancaire, la session soit invalidée dès 5 minutes d’inactivité.
Le concept de mémoire Flash et les autres scopes
Dans le développement web, les scopes permettent de définir la durée de vie des variables. En java nous sommes habitués aux scopes “Application”, “Session”, “Request” et “Page”. Play! étant stateless et ne stockant aucune information côté serveur, le scope “Application” n’a pas lieu d’être.
En play! on distingue 4 scopes : “Session”, “Request”, “Flash” et “Response”. Quel que soit le scope concerné, les données sont stockées côté client sous forme de cookies et rien n’est stocké côté serveur.
Le scope “Flash” permet de stocker des données entre deux requêtes. En pratique, il s’agit d’un cookie ordinaire (taille max 4KO) qui est écrasé à chaque réponse HTTP reçue.
Le scope “Flash” est destiné en particulier à stocker les erreurs en attendant la prochaine requête.
L’AOP made by Play!
L’annotation @With placée au-dessus d’une méthode d’un contrôleur permet d’indiquer à Play! qu’un traitement particulier doit être réalisé avant que ladite méthode ne soit exécutée. Cette annotation reçoit un paramètre indiquant l’action à exécuter. Ladite action peut soit effectuer un traitement puis exécuter (ou pas) la méthode initiale du contrôleur ou bien renvoyer une exception.
En utilisant cette annotation, nous allons implémenter un mécanisme de contrôle des droits de l’utilisateur. Nous allons créer une annotation “AdminRoleChecker” qui sera placée au-dessus de toutes les méthodes qui ne devraient être accessibles qu’au rôle ADMIN.
Voici le code de la classe “AdminRoleCheckerAction” qui contient l’intelligence de notre annotation.
public class AdminRoleCheckerAction extends Action<AdminRoleChecker> {
public Result call(Http.Context ctx) {
//on récupère le user courant
User user = currentUser();
//si ce n'est pas un administrateur on
if(user!=null && !user.getRole().equals(Role.ROLE_ADMIN)){
//Lever une exception métier ici
}
//C'est un administrateur, on peut donc exécuter la méthode initiale.
return delegate.call(ctx);
}
private User currentUser(){
//recuperer l'objet User correspondant à l'utilisateur actuel
}
}
Ci-dessous, on définit l’annotation “@AdminRoleChecker” à partir de l’annotation “@With”
@With(AdminRoleCheckerAction.class) // La méthode call de AdminRoleCheckerAction sera appelée
@Target({ElementType.METHOD}) //Cette annotation peut etre placée au dessus d'une méthode
@Retention(RetentionPolicy.RUNTIME)
public @interface AdminRoleChecker {
}
Play! vs les frameworks Web Java EE
La philosophie
Play! veut rompre avec les points faibles de Java EE : périmètre fonctionnel illimité, trop de configurations, trop de couches etc… Play! est un framework web et n’a pas d’autre ambition.
En pratique, dans une webapp Java EE classique (Struts / JSF), on a systématiquement les couches suivantes :
- Struts – tiles / JSF -facelet (une page structurée et modulaire)
- API Servlet (Traiter des requêtes HTTP)
- Servlet Container (Conteneur d’exécution des servlet)
- Serveur HTTP
C’est cet empilement de couches que les concepteurs de Play! appellent « l’architecture lasagne». A contrario, dans Play! toutes les fonctions ci-dessus sont encapsulées dans le framework. Play! est ready-to-use et supporte nativement plusieurs frameworks usuels. Ainsi JPA, Hibernate, EBeans, JUnit, less, CoffeeScript , Selenium… n’ont pas à être intégrés par le développeur.
Enfin, il y a dans la conception de Play! une volonté de rupture avec l’existant. Cette volonté explique le choix de ne pas utiliser la convention com.enterprise_name.app_name pour le nommage des packages. En effet, il n’y a aucune raison de réutiliser un package de la webapp Play! hors de la webapp. Ainsi, on a un package play.mvc par exemple. Ceci est sans doute discutable mais c’est assumé.
Une Webapp Play! n’est pas une webapp Java EE
Play! ne se base pas sur l’API servlet. Les servlets datent des premières versions de Java et ont toujours constitué le socle du développement web en Java. Tous les frameworks Web full Java de ces dernières années Wicket, Struts, JSF… sont basés sur l’API servlet.
La raison principale invoquée à la non-utilisation de l’API Servlet est qu’elle est (serait) trop complexe et induirait trop de couches. Une réponse a été donnée sur Stackoverflow ici
Play! embarque un serveur HTTP en interne et est autonome. On ne devrait donc pas avoir besoin d’un serveur d’application Java EE pour faire tourner son application. Cependant, il est possible de déployer une webapp Play! pour qu’elle tourne en mode servlet et puisse donc être déployée dans un serveur d’appli Java EE. En Play! 1, celà pouvait être effectué via la commande “play war”. La procédure complète est décrite dans la documentation de Play! 1 . Par contre, en Play! 2, il faudra utiliser un plugin disponible sur Github.
Le web n’est pas juste une couche en plus
Du point de vue du développeur Java EE, le web est une couche de présentation au-dessus d’autres couches (service, business, dao) et interchangeable avec une autre couche de présentation (client lourd swing par exemple).
Ce point de vue peut être remis en cause. En effet, le web est un système à part entière avec ses propres règles. A force de vouloir adapter le web à Java EE (et non l’inverse), on a rendu le développement de webapp Java EE plutôt complexe par rapport aux PHP, Ruby on Rails et autres.
Voici quelques critiques triviales:
- URLs imposées par le framework et non par le market
Sur nombre de sites de e-commerce, on continue de voir des URLs en .do ou .jsf. L’URL est un moyen de communication avec le client humain et il devrait avoir une nomenclature claire et non barbare.
Bémol : Il existe des frameworks pour gérer des URLs business, notamment PrettyFaces pour JSF
- Impossible de constater nos modifications en temps réel
On est obligé de redémarrer le serveur et de redéployer l’application (et d’aller prendre un café 🙂 ).
Bémol : Il est possible en utilisant JRebel de pallier à ce problème.
Comme on peut le voir à travers ces deux exemples, ce qui gêne dans les frameworks web Java EE n’est pas tant ce qu’il ne peuvent pas faire mais la manière dont ils résolvent les problèmes : en rajoutant un autre framework. Par contre Play! dès sa conception prend en compte ces uses cases du web et le développeur n’a pas besoin de mettre en oeuvre un framework supplémentaire.
La productivité avec Play!
L’objectif affiché, c’est d’atteindre le niveau des PHP et Ruby on Rails ou Grails. Pour y parvenir Play! a plusieurs atouts.
Interprétation du .java
L’un des plus importants est que le framework se base sur le .java et non le byte code. Ceci signifie que chaque fois qu’on modifie une classe, nos modifications sont effectives simplement en faisant un F5 dans le browser. Il n’est donc plus nécessaire d’aller prendre un café (ou un thé 🙂 ) le temps que son serveur d’application redémarre avant de voir l’effet de nos modifications.
Débogage aisé
Les templates (fichiers *.scala.html) et le fichier des routes sont compilés en classes Scala. L’usage de Scala qui est “type safe” permet de constater les erreurs dans les routes et les vues dès la compilation plutôt qu’attendre l’exécution. Dans l’exemple ci-dessous, j’ai fait une faute de saisie dans le fichier des routes : j’ai saisi defaultttQuery() au lieu de defaultQuery().
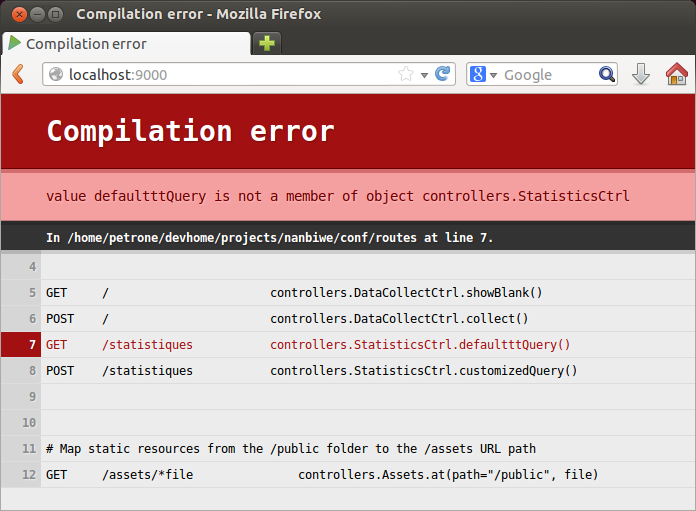
On peut constater deux choses :
- Quand on actualise une page, c’est l’ensemble du fichier des routes qui est compilé. C’est pour cette raison que quelque soit l’URL exécutée, l’erreur sera constatée.
- Nous avons un message d’erreur clair et compréhensible au premier coup d’œil qui nous permet de savoir quel fichier et quelle ligne est en cause.
Ce type d’erreur est également détectable en exécutant directement un “play compile”; c’est d’ailleurs ce que fait Play! en interne lorsque nous actualisons notre page. Cette fonctionnalité constitue un vrai avantage de Play! car elle évite la désagréable surprise de découvrir les erreurs au runtime.
La non-utilisation du modèle anémique
Le modèle anémique a fait l’objet de plusieurs critiques, notamment ici et là. Je ne vais donc pas reprendre la discussion. Je vais juste faire un rappel sur l’usage du modèle anémique en Java.
En java, nous avons l’habitude de définir des objets métiers qui sont anémiques et de définir des DAO qui, à l’inverse, ne définissent aucune donnée membre. Notons que le modèle anémique va à l’encontre des fondements de l’orienté objet qui suppose qu’un objet est un ensemble de données et de comportements.
Dans Play! même si ce n’est pas imposé, on est encouragé à enrichir nos objets métiers avec des comportements notamment des méthodes de persistance Concrètement, l’intérêt est que pour une classe “Commande” et un objet “commande”, on peut faire un “commande.save” et pas “CommandeDao.getInstance().save()”.
Encapsulation des champs marqués “public” par le Framework
Lorsque nous écrivons un bean Java, nous avons pris l’habitude de mettre tous les champs en private et de définir des accesseurs. Nos IDEs sont configurés pour nous générer ces méthodes en un clic. L’objectif est d’encapsuler les données membres de la classe et au besoin de définir un comportement particulier dans l’accesseur. Cependant, force est de constater que dans la majorité des cas, nous ne modifions jamais les méthodes générées par l’IDE. Dans la pratique, tout se passe “comme si” nos champs avaient été publics. Sauf que, les méthodes ayant quand même été écrites, elles “encombrent” la classe pour rien.
Play! propose une solution simple à ce problème: par défaut le framework considère que tout champ non static doit être encapsulé. Quand un champ est déclaré avec une visibilité public, à la compilation, Play! le déclare private et génère les getter/setter. Ainsi, le bruit, généré par les getter/setter est supprimé et la classe est plus aisée à lire.
Cependant, il peut être perturbant pour le développeur d’accepter qu’un framework va modifier ses sources. Play! laisse donc le choix au développeur qui peut toujours continuer à implémenter “à la main” ses getter/setter. Il lui appartient dans ce cas de déclarer la donnée private.
Les tests
Grace à l’intégration de JUnit les tests unitaires peuvent être réalisés aisément. Par ailleurs, le fait que les templates et le fichier des routes soient compilés en Scala les rend testables. Il est donc possible de tester tous les éléments du modèle MVC via des tests unitaires.
Au delà des tests unitaires, Play! permet de réaliser des tests fonctionnels plus poussés grâce au démarrage d’un serveur de tests depuis la classe de tests. L’intégration native de Selenium permet aussi de simuler l’interaction Homme – Machine.
Critiques
Hégémonie du langage Scala
Même si dans la version actuelle de Play! on a toujours deux API Java et Scala, il faut reconnaître que la tendance est plutôt de développer en Scala. Quand on regarde la communauté Play! sur le web, on peut constater également cette tendance.
En tant que développer Java, on peut donc se sentir un peu frustré. En effet, on est passé de Play! 1.0, un framework Java proposant un support optionnel de Scala à Play! 2.0 qui est un framework Scala proposant une API Java. On ne peut s’empêcher de se demander pendant combien de versions encore une API Java va être proposée.
L’immaturité du framework
En cette période où l’agilité est plus qu’une tendance, c’est positif de voir que les concepteurs du framework n’hésitent pas à effacer ce qui ne fonctionne pas (ou qui n’est pas optimal) en le réécrivant. Ça a été le cas notamment lorsque Scala a été préféré à Groovy comme langage de templating. Cependant, ceci a un coût pour le développeur.
Le fondateur de Zenexity (la société derrière Play!) a dit qu’il fallait “développer aujourd’hui nos webapp avec les technologies de demain afin que nos applications ne soient pas obsolètes dans deux ans “. Dans ce cas, comment se fier à un framework qui ne me permet pas une compatibilité sur deux / trois ans ? Aujourd’hui, ceux qui ont développé avec Play! 1.0 en 2011 sont coincés.
Le second problème lié à la dynamique de Play! est que la documentation même quand elle bonne au départ est souvent obsolète. Ce n’est pas rédhibitoire mais cela peut se révéler assez chronophage.
Fonctionnalités absentes
Pour gérer l’authentification/autorisation en Play!, on est obligé d’utiliser (ou de perdre du temps à les réinventer) des modules externes : Play! Authentificate et Deadbolt. Malgré la qualité de ces modules mis à disposition gratuitement par leurs auteurs, on ne peut s’empêcher de regretter que ces problématiques, centrales dans le développement d’une webapp, ne soit gérées nativement par le framework. Mais peut-être que ça sera le cas prochainement.
Conclusion
Les alternatives
Play! n’est pas le seul framework JVM compatible qui promette d’améliorer la productivité en proposant une rupture avec l’existant. Je pense que les frameworks ci-dessous valent également le détour en particulier Grails. J’ai volontairement écarté les “anciens” : Struts, JSF et Wicket pour ne m’intéresser qu’aux “nouveaux”. Evidemment cette liste ci-dessous n’est pas exhaustive et j’espère l’enrichir grâce a vos retours.
- Grails
Grails est un framework web basé sur le langage Groovy qui est lui-même un langage de scripting tournant sur la JVM. Je pense que Grails mérite une attention particulière de la part des développeurs Java.
Un comparatif très complet entre Grails et Play! a été réalisé ici .
- Lift
Lift est un framework web basé sur le langage scala.
- Spring Webflow
Spring Web Flow est un sous-projet de Spring Framework.
Play! : Une remise en cause de l’existant
Au-delà des critiques qu’on pourrait formuler sur Play!, son architecture et les divers choix effectués par ses concepteurs, on ne peut nier ce qui me semble le principal apport de Play! : une remise en cause de l’existant.
Play! nous amène à nous interroger sur la pertinence d’un dialogue statefull dans le cadre d’une webapp, sur notre compréhension du web et de ses contraintes, sur l’intérêt à générer des méthodes qui, dans 98% des cas (j’exagère intentionnellement) ne feront qu’un “passe-plat” : les accesseurs des Java beans etc…
Notre environnement et nos méthodes de travail évoluent. La décennie d’évangélisation a eu son effet et même si l’Agile n’est pas encore LA norme, nombre d’utilisateurs s’attendent de plus en plus à avoir une première livraison très en amont suivie de livraisons régulières. De même, à l’heure de Facebook, plus personne n’accepterait qu’une application tombe dès le millier d’utilisateurs. Pour faire face à ces défis, entre autres, nous avons besoin d’outils performants et il me semble qu’un framework tel que Play! en est un.
Documentation
- Play for Java
Nicolas Leroux and Sietse de Kaper
Un très bon livre sur Play! disponible chez Manning Publications en version numérique et/ou papier. Il existe un second livre pour les développeurs Scala.
Le site officiel du framework
Un excellent comparatif tres complet entre Play! et Grails
Des articles et discussions sur le modèle anémique
Un article sur les avantages de Ruby On Rails