
Les Tests U sont-ils for U ?

Cela fait quelques années que les Tests Unitaires sont à l’ordre du jour. C’est la bonne pratique à utiliser partout, l’outil indispensable pour :
1) Eviter les régressions
2) Ecrire un code plus maintenable et se comportant de façon plus prévisible
Ceci dit, on continue à les considérer comme une des tâches les plus ennuyeuses en informatique. On continue à découvrir du code non maintenable dans presque tous les projets et avoir des régressions. Est-ce parce qu’on n’a pas écrit assez de tests unitaires ? Est-ce parce qu’on les a mal écrit ? Ou devons-nous chercher la réponse ailleurs ?
Dans tous les cas, il y a beaucoup de critiques contre les tests unitaires : c’est absolument normal, les informaticiens grognent sur tout ce qui est répétitif et vont essayer de trouver des arguments pour ne pas le faire. Mais regardons ces critiques de plus près. Elles suivent 2 axes :
Un moyen inefficace pour éviter les régressions ?
Il y a 2 lignes de défense dans cet argument :
- Les projets à durée de vie courte
- Les tests non-unitaires
Les projets à durée de vie courte
Les « commandos » du code Excel n’ont pas besoin de tests unitaires pour leurs projets qui seront utilisés une seule fois. Tom Fischer a déjà présenté cet argument : si nous ralentissons le développement pour écrire les tests unitaires pour se protéger contre des régressions futures, nous nous attendons à ce qu’il y ait un retour sur investissement, ie que le temps gagné par les régressions découvertes par les tests unitaires va un jour être supérieur au temps consacré pour les écrire.
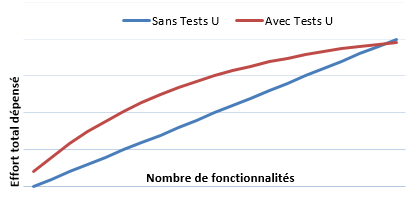
Le problème avec Fischer, est qu’il a essayé de schématiser son argument avec un diagramme d’une façon qui simplifie tellement le problème, qu’on risque de rejeter son argument qui semble pourtant instinctivement correct. Il commence avec une relation linéaire où le coût de la mise en place de tests unitaires est élevé au début, mais au fur et à mesure on gagne du temps.
La vérité est différente : sur un nouveau projet, mettre en place l’infrastructure pour les tests unitaires et écrire les premiers consomme rarement plus que 20% du temps par rapport à la configuration initiale de tous les autres composants. Ce qui est différent c’est que pour CHAQUE nouvelle fonctionnalité et CHAQUE nouveau refactoring, nous consommons du temps pour écrire ou réparer les tests unitaires. Un simple renommage d’une méthode publique (5 secondes sans tests unitaires), en fonction des pratiques et frameworks utilisés pour les tests, peut consommer 5 minutes si nous avons des tests unitaires (n’hésitez pas à me demander des exemples concrets). Donc ce qui augmente avec les tests unitaires, ce n’est pas tellement le coût fixe, mais bien le coût variable par fonctionnalité.
Par contre, avec le temps, les tests commencent à faire découvrir des régressions. Chaque fois qu’on a ça, on a un gain de temps très important : autrement la régression serait partie vers la préproduction ou pire la production et le temps passé pour la découvrir, la remonter et la réparer aurait été élevé. Ces incidents arrivent plus souvent quand l’équipe est changée, la documentation est manquante et les développeurs ne maîtrisent pas cette partie du code. Ceci fait que le coût variable diminue avec le temps. Un schéma plus proche de la réalité serait celui-ci :

Deux questions se posent alors :
- Il semble évident qu’il y ait un t0 (nombre de fonctionnalités) avant lequel avoir des tests unitaires sur le projet ne vaut pas la peine. Quel est ce t0 et comment pouvons-nous connaître en avance la durée de vie d’un projet ? Ces questions n’ont pas de réponses évidentes.
- Et si cette différence d’effort entre la ligne rouge et la ligne bleue avait été investi à autre chose que des tests unitaires, aurions-nous un meilleur retour ? J’essayerai de répondre à cette question pendant le reste de cet article.
Les tests non-unitaires
D’expérience personnelle, un développeur expérimenté risque très peu de faire une faute dans une seule méthode quand le code a une belle architecture. Par contre il est facile de se perdre dans les interactions entre classes, d’avoir considéré qu’un cas ne va jamais arriver ou d’avoir une mauvaise surprise dans le comportement d’un navigateur. La plupart de ces erreurs ne seront pas découverts par les tests unitaires.
Heureusement, les tests unitaires ne sont pas la seule ligne de défense contre la régression. A part écrire du bon code maintainable (un sujet sur lequel je vais vite revenir), il y a 2 types de tests non-unitaires :
Les tests de bout en bout.
Ici une personne vérifie le résultat final, la réaction du logiciel aux actions externes. Ces tests sont indispensables, particulièrement quand il y a une IHM. Ils seront faits dans tous les cas. Aucun test unitaire ne peut remplacer une bonne équipe d’assurance qualité. C’est la seule façon de valider l’ergonomie d’une IHM, de vérifier que la solution fonctionne sur l’environnement de production (réseau, comportements des navigateurs etc…) ou de valider un livrable. Ce n’est qu’ici que l’on peut découvrir une grande majorité des problèmes. Dans ce cas, pourquoi retester ce qui va être déjà testé ? Pourquoi payer des jours-hommes d’informaticien (ie plus chers que ceux de gens dans la QA) pour écrire des tests qui ne vont trouver qu’une petite partie des problèmes ? Il y a deux raisons :
1) C’est souvent difficile de trouver la cause d’un problème détecté au niveau d’un test d’interface. En plus, dans un cas sur deux, la solution est au niveau d’une seule méthode ou même d’une seule ligne dans le code. Si les tests unitaires avaient trouvé le problème ils auraient remonté le problème plus tôt et auraient pointé directement sur la méthode fautive.
2) Dans certains cas c’est très cher et lent de re-tester tout un système pour la régression. Il faut donc automatiser. Quand nous avons une application XAML ou JavaFX c’est faisable d’automatiser plusieurs scénarii, mais les applications en HTML, avec les comportements des navigateurs, leurs mises à jour qui peuvent changer le comportement et la configuration frameworks (type Selenium) est un gros casse-tête. On ne sait pas au final si la remontée d’erreur est à cause d’une vraie régression ou d’un nouveau problème de configuration de serveur. Et si on ajoute le problème des bases de données de démo (qu’on va revoir dans les tests fonctionnels), on voit que c’est un investissement en temps qui peut dépasser celui qu’on accorde aux tests unitaires.
On pourrait penser que ce type de tests est plus approprié quand nous n’avons pas la main sur le code et nous devons valider des systèmes externes. Malheureusement c’est ne pas le cas. Pour faire des tests robustes sur une IHM qui ne dépendent pas de l’arborescence (dom ou XAML) des contrôles dans l’affichage nous devons pouvoir identifier de façon unique les éléments que nous voulons tester, sans avoir besoin de dire « je veux le 2ème lien dans le premier tableau de ce div ». Il faut donc que l’application soit codée avec les tests en tête, ie les gens doivent avoir ajouté des identifiants (qui rendent le code moche) JUSTE pour nos tests.
Les tests fonctionnels
Situés entre les tests unitaires et les tests de bout en bout, les tests fonctionnels testent une fonctionnalité d’un niveau un peu arbitraire, en ayant le droit de tester plusieurs méthodes ou bien même une méthode en appelant une autre qui à son tour appelera un web service qui fera une requête en base de données etc… Pour chaque application et besoin, nous essayons de trouver le bon compromis de niveau pour avoir un test qui pourra nous dire quel critère d’acceptation ne passe pas et que l’on pourra suivre appel-par-appel pour trouver la cause du problème.
Ces tests sont particulièrement intéressants quand nous publions des APIs, où l’utilisateur est une autre machine, sans passer par une IHM. Quand nous pouvons nous passer de l’IHM (et ce n’est pas toujours le cas, ça dépend du problème), nous arrivons à éviter une grande partie des problèmes de configuration et de maintenabilité des tests. Nous pouvons utiliser directement ou indirectement les outils déjà existants pour les tests unitaires (voir tests ordonnées de MS Test etc…).
Nous avons toujours besoin de gérer une base de tests et de faire attention à nettoyer les bourdes que nous avons laissées dans la base après nos tests. Le problème est qu’un full backup-restore est trop lent, donc au final nous procédons souvent aux scripts de nettoyage de données. Vous imaginez déjà le souci : quand notre code ne marche pas comme anticipé, il risque de modifier ou créer des données que nous n’avons pas anticipé de nettoyer, et les laisser trainer dans la base de données, risquant de faire échouer d’AUTRES tests. La solution à ce problème n’est pas évidente (mais vous pouvez toujours commencer par activer les ON DELETE CASCADE dans vos bases – ça fera plus de bien que de mal).
Quand ils sont bien faits, les tests fonctionnels peuvent remplacer les tests unitaires. Quand ils sont mal faits, « ils s’écroulent sous leur propre poid », remplissant les logs avec des fausses alertes : ils ne justifient alors pas le temps passé dessus.
Un moyen inadéquat pour écrire du bon code ?
Nous avons vu qu’il y a 2 alternatives aux tests unitaires : une que nous allons avoir dans tous les cas (tests manuels), et une autre qui a aussi ses propres problèmes (tests fonctionnels). Les supporters des tests unitaires répondent : ok, ce n’est pas grave si nos tests trouvent juste une petite partie des problèmes, leur avantage est qu’ils reduisent aussi les autres problèmes, en nous incitant à écrire du bon code !
Le bon code, le code qui est facile à maintenir, qui fait ce qu’on a besoin de façon concise, qui est beau, c’est le signe d’un vrai passionné du développement et professionnel en même temps.
Comment les tests unitaires aident-il à écrire du bon code ? En forçant le développeur à séparer des responsabilités (separation of concerns), à créer des méthodes plus petites, en l’aidant à éviter les effets de bord, en le poussant à réfléchir sur ce que la méthode doit faire avant de l’écrire, en réduisant le des dépendances entre les objets etc… Avec quelques semaines de tests unitaires, c’est vrai que nous apprenons à penser notre code différemment, nous devenons de meilleurs développeurs. Mais après ces semaines, avons-nous besoin de continuer à écrire des tests unitaires ?
Les tests unitaires ont-ils un effet positif sur la durée ?
Chaque fois que je vois un setter ajouté, une méthode rendue interne ou virtuelle (au lieu de privée) ou une propriété du type DateTimeProvider ajoutée dans le code de production à l’usage des tests unitaires je n’ai qu’une réaction :

Les tests unitaires sont là pour rendre le code de production meilleur. Dépenser du temps pour ajouter des lignes de code et augmenter la probabilité d’erreur parce que quelqu’un a confondu les moyens et les buts est un mauvais signe. Ça signifie qu’on préfère suivre les procédures et ne pas prendre de risque au lieu de vraiment regarder au-delà et ajouter de la valeur.
Les métriques formelles, comme forcer 80% de couverture de code par les tests unitaires, rendent le problème encore pire. Ce 80% est à mon sens la métrique la plus dénuée de sens juste après celle de la productivité comptée en nombre de lignes de code. Dans la plupart des cas nous pouvons arriver à 80% en ne testant QUE le cas nominal. Qui plus est dans ce cas, ne pas écrire de code pour gérer les cas exceptionnels… augmente la couverture !
Même si nous codons correctement, l’effet de la testabilité sur la qualité du code n’est pas forcement important.
Le problème apparaît sous un nouveau jour lorsque on porte TOUT vers le code orienté objet pour le rendre testable de façon unitaire. Les procédures stockées ? Les champs calculés dans la base ? On supprime, tout sera fait en code. Nous voyons ce problème plus fréquemment dans le monde Java que dans le monde .Net où il est plus fréquent d’avoir des développeurs avec une double casquette .Net – SQL Server. Il y a des avantages : l’équipe a des capacités uniformes et le déploiement est plus simple. Nous n’avons pas besoin de passer 1 semaine à apprendre chaque nouvel outil.
Les désavantages sont bien sûr évidents : quand nous avons le marteau qui s’appelle Java (ou C#) tout rassemble à un clou. Nous n’utilisons pas le bon outil pour chaque tâche. Les performances en souffrent et nous ne réduisons pas vraiment le risque. Pourquoi ? Parce qu’en faisant chaque chose avec un outil inapproprié à la tâche, nous écrivons plus de code (plus de possibilités d’erreur) et nous sommes moins protégés de la classe d’erreurs la plus fréquente pour cette tâche. En gros, nous arrivons au point 2 :
Il y a plusieurs chemins vers un code propre
Il y a d’autres pratiques ou paradigmes qui peuvent nous aider à écrire du bon code. Mon avis est qu’il faut presque tout essayer, parce que chaque approche nous apprend des nouvelles techniques utilisables même quand nous reviendrons vers notre langage de préférence.
Avez-vous fait de la programmation fonctionnelle, où nous pensons forcément pour chaque méthode avec une notion d’entrée-sortie, sans effets de bord et où nous avons rarement des nulls ? (je conseille Real-World Functional Programming pour les expérimentés en C#).
Et si vous remplaciez le code avec quelque chose de plus déclaratif, où l’ordre d’exécution est moins importante ? (swing vers JavaFx, WinForms vers XAML, itérations vers LINQ etc)
Si vous convertissiez les importations et exportations de fichiers en SSIS ou un autre ETL équivalent (Informatica can apply, Talend trouvera la porte fermée :P) pour suivre le déroulement de façon visuelle et gagner en performances grâce au pipeline (data-flow) ? Lorsque le code le plus compliqué est une expression isolée de 80 caractères et que nous pouvons tester avec des flux de vrais fichiers, le débogage est simple et immédiat.
A mon avis il ne faut pas éviter les solutions élégantes et fiables juste parce qu’elles ne sont pas testables de façon unitaire (comment teste t’on une expression lambda passée en paramètre ?).
Bien sûr il y aura toujours des éléments procéduraux dans le code, qui ne peuvent pas être améliorés en changeant de paradigme. Mais même là, il y a d’autres approches qui peuvent accompagner les tests unitaires dans la quête vers un bon code (code contracts, revues de code, programmation en binôme). Chaque approche a ses avantages, mais le plus important est que chaque personne a ses préférences pour l’une ou l’autre des approches. Il y a des gens qui détestent devoir lire le code d’une autre personne pour une revue de code et préfèrent travailler en binôme, il y en a d’autres qui ne seraient pas devenus développeurs si c’était pour travailler la plupart de temps avec un binôme.
Alors c’est de la merde ou de la bombe ?
Mon avis est que les tests unitaires ne sont pas une religion : c’est juste un outil comme les autres. Ça me rappelle quand on me disait qu’il faut toujours utiliser la programmation orientée objet (et ça m’a pris quelques années pour accepter les alternatives) ou que les design patterns c’est génial.
Contexte
Programmez-vous un API ou une IHM ? S’il y a une faute, est-elle visible rapidement par un testeur ou utilisateur interne ?
Quels sont les coûts et risques associés à l’erreur ? (y compris le cout horaire de la QA ;))
Quelle est la complexité du système et quelle est son espérance de vie ?
Quelle est la probabilité qu’il y ait une demande de modification ?
Pouvez-vous le faire d’une façon qui implique moins de code itératif et plus de déclaratif ou de « magie » fiable (exemple : SSAS) qui fera ce qu’il faut faire ?
Attention : les réponses seront différentes par composant de code. Certains vont bénéficier de façon importante des tests unitaires et d’autres devraient être testés à un niveau plus global.
Humains
C’est important d’avoir des gens motivés qui arrivent à s’exprimer dans leur travail.
Les « best practices » sont parfois une auto-flagellation pour les fautes du passé. « Je sais que c’est chiant, mais tout le monde dit que c’est bien de le faire donc je le fais. Même si la productivité baisse, on ne va pas m’accuser de ne pas avoir fait tout ce que je pouvais pour limiter les régressions »
Et là, je veux proposer quelque chose de révolutionnaire (ok, j’exagère avec une petite dose de sarcasme) : laisser des marges à l’équipe pour que chacun choisisse son chemin vers le code propre. Par exemple dire que « vous avez droit de ne pas faire de tests unitaires pour une méthode, mais cette méthode fera l’objet d’une revue de code et vous serez obligé de revoir 2 méthodes d’autres personnes » ou « les jours où vous jugez que vous n’avez pas besoin de faire des tests unitaires, vous devrez passer une heure à réfactorer et simplifier le vieux code qui est couvert au moins par un type de test (fonctionnel, IHM etc) ».
Au final, il faut penser plus en termes de valeurs que des méthodes 😉