
Petite introduction au Web Sémantique : les technologies du Web Sémantique (1)
![]()
Dans l’article précédent, nous avons vu que le Web de Documents ne répond pas complètement aux besoins de qualification et d’organisation de l’information. Reprenons le cas de Bob : pour connaître la programmation culturelle de son quartier, parcourir les avis des internautes puis acheter sa place à un tarif raisonnable, Bob doit toujours parcourir les 4 coins du Web. Il existe cependant des technologies permettant de préserver le temps et la santé mentale de Bob. Ces technologies vont nous aider à effectuer un “saut sémantique” en proposant un cadre dans lequel il est possible de décrire ses données et de les lier entre elles. C’est ce “réseau de données” et (surtout) son exploitation qui vont épargner bien des tracas à Bob et à tous les amateurs de théâtre sans le sou. Dans ce nouvel article, nous allons décrire les différentes briques technologiques utilisées dans le monde du Web Sémantique et nous allons nous attacher à montrer en quoi elles sont utiles pour résoudre le problème de Bob.
Encore un peu d’histoire…
Aux yeux du grand public, la notion de Web Sémantique est apparue en 2001 avec la publication de l’article “The Semantic Web”[1] (une traduction française est disponible ici [2]) dans le magazine “Scientific American” par Tim Berners-Lee, James Hendler et Ora Lassila. Cet article présente des cas d’usage des technologies du Web Sémantique centré sur des situations courantes. Il décrit ainsi le degré d’intrication que le Web Sémantique pourrait avoir avec nos vies quotidiennes dans le futur. Malgré son caractère prospectif (voire carrément science fictionneste), la publication de cet article est une étape importante dans la vie du Web Sémantique. L’acte de naissance officiel, quant à lui, date de la première conférence WWW qui s’est tenue à Genève en 1994 [3]. Durant cette conférence, Tim Berners-Lee propose de dépasser la vision d’un Web uniquement composé d’un ensemble de documents et d’hyperliens. Il suggère de lier les documents à des “ressources” (qui peuvent être des objets du monde réel). Ainsi dans l’univers du Web Sémantique, les notions de personne, de maison (ou de pièce de théâtre) peuvent accéder à une existence en dehors de l’unité de document et être le reflet virtuel d’un objet bien réel. L’idée est ambitieuse et les travaux débutent sous la responsabilité du W3C naissant.
 https://www.w3.org/Talks/WWW94Tim/[/caption]
https://www.w3.org/Talks/WWW94Tim/[/caption]
Le résultat de ces travaux (qui sont toujours en cours) est constitué d’un ensemble de briques technologiques se reposant les unes sur les autres. Le schéma d’ensemble forme ainsi une sorte de pyramide, le fameux “Semantic Web Layer Cake”.
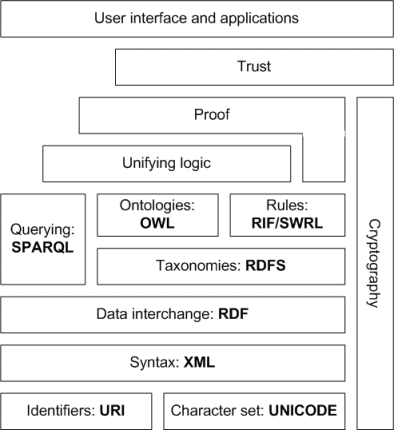 https://en.wikipedia.org/wiki/Semantic_Web_Stack[/caption]
https://en.wikipedia.org/wiki/Semantic_Web_Stack[/caption]
Chaque technologie se base sur les couches inférieures et est utilisée par les couches supérieures et chaque nouvelle couche est plus expressive et plus riche que le substrat sur lequel elle repose. Bon, il est un peu cryptique et pas très digeste ce gros gâteau. Nous allons essayer d’y voir un peu plus clair. Tout d’abord, faisons le point sur ses différentes composantes, nous allons les découper en 3 catégories :
- la catégorie des technologies qui existent indépendamment du Web Sémantique (comme Unicode, XML ou les URI). Il s’agit du “bas” du gâteau.
- la catégorie des technologies liées au Web Sémantique qui existent et qui sont standardisées (RDF, RDFS, OWL, SPARQL) .
- la catégorie des technologies qui sont en cours de développement. Il s’agit du “haut” du gâteau et nous ne nous étendrons pas sur cette partie. De toute façon, il y a déjà pas mal de chose à raconter sur les couches antérieures.
Certes, ça fait déjà beaucoup d’acronymes et ce gâteau ressemble plus à un pudding au bitume qu’à une délicieuse pâtisserie de grand mère mais ne partez surtout pas : c’est ce pudding qui va sauver Bob! Et ce sauvetage passe par les 3 étapes suivantes :
- comment nommer et trouver des ressources ? Pour Bob, il s’agit de trouver des pièces de théâtre, des tarifs, des salles de spectacles, des avis postés par les internautes, etc. Cette étape correspond à la couche URI (Uniform Resource Identifier) du gâteau.
- comment lier ces ressources ? Pour Bob, il s’agit de savoir comment est liée une pièce de théâtre avec la salle dans laquelle elle est jouée, de savoir comment est liée cette salle avec la rue, la ville et pays qui constituent son adresse, etc. Cette étape correspond à la couche RDF (Resource Description Framework) du gâteau.
- quelle est la nature de ces ressources et ces liens ? Pour Bob, il s’agit de savoir que la ressource A est une pièce de théâtre, la ressource B est une salle de spectacle et la ressource C, le lien sémantique liant une pièce de théâtre et une salle de spectacle. En d’autres termes, il s’agit de décrire et de comprendre l’univers dans lequel évoluent nos pièces de théâtre, nos salles de spectacles, nos spectateurs, nos adresses, etc. Cette étape correspond à la couche OWL (Web Ontology Language) du gâteau.
Comment nommer et trouver des ressources ?
Nous avons vu que le Web Sémantique n’est pas uniquement constitué de documents mais également de ressources qui sont le reflet virtuel d’objets de la vie réelle. La question qui se pose alors est de savoir comment nommer ces ressources et sous quelle forme les récupérer.
Du côté du Web de Document, les hyperliens permettant d’identifier les documents sont associés à des URL (Uniform Resource Locator) qui indiquent leur localisation. Ces URL répondent à une syntaxe précise qui spécifie les éléments suivants :
- le scheme qui indique le contexte dans lequel l’URL doit être interprétée. Il s’agit par exemple du protocole à utiliser pour accéder à la ressource. Pour un document web, la valeur du scheme est “http”. Un navigateur pourra ainsi déréférencer l’URL et récupérer le document en effectuant la requête appropriée (HTTP GET sur le port 80).
- l’authority qui indique l’organisation en charge d’interpréter l’URL. Cette organisation a tout d’abord obtenu délégation pour un nom auprès de l’ICANN (Internet Corporations for Assigned Names and Numbers).
- le path qui permet d’indiquer la position hiérarchique de la ressource (sur le même modèle qu’un système de gestion de fichier).
- la query qui permet de fournir des informations de nature non hiérarchique. Il s’agit généralement d’une liste de couples clé valeur.
- le fragment qui ne fait pas partie du nom de la ressource à atteindre mais permet d’accéder à un élément secondaire. Pour une page HTML par exemple, il peut s’agir de l’identifiant d’une ancre.
Ainsi, si Bob souhaite des informations au sujet de Shakspeare, il adressera sa demande à l’auhorityfr.wikipedia.org, en spécifiant le pathwiki/William_Shakespeare dans le contexthttp.
Le Web Sémantique repose sur les URI (Uniform Resource Identifier), qui sont une extension du concept d’URL. Conceptuellement, URI et URL permettent de distinguer une ressource (l’URI) d’une représentation possible (l’URL). En réalité, les deux concepts sont souvent confondus : les URL sont des URI mais certaines URI ne donnent pas d’information relative à la localisation de la ressource. Par exemple, le numéro ISBN d’un livre permet de l’identifier de façon univoque (et d’être ainsi utilisé pour construire son URI) mais n’indique pas comment l’obtenir.
Dans le monde du Web Sémantique, si Bob souhaite des informations au sujet de Shakespeare, il peut adresser la ressource https://dbpedia.org/resource/William_Shakespeare[4], qui correspond à une URI identifiant le dramaturge William Shakespeare. Deux situations se présentent alors :
- Bob dispose d’un outil ignorant comment évoluer dans le monde du Web Sémantique (un navigateur web classique). L’autorité dbpedia l’oriente alors vers l’URL https://dbpedia.org/page/William_Shakespeare contenant une représentation HTML de la ressource demandée. Cette représentation contient de nombreuses informations utiles mais Bob doit parcourir la page lui-même afin de les exploiter. Il s’agit donc de la représentation Web de Document.
- Bob dispose d’un outil sachant évoluer dans le monde du Web Sémantique. L’autorité dbpedia l’oriente alors vers l’URL https://dbpedia.org/data/William_Shakespeare contenant la description formelle (en langage RDF) de William Shakespeare. Il est alors possible d’accéder automatiquement à des données biographiques. Ces informations sont exploitables par une machine et permettent d’établir des relations avec d’autres sources de données. Il s’agit donc de la représentation Web Sémantique.
Le mécanisme permettant de choisir quelle représentation renvoyer se nomme “négociation de contenu” et se base sur les informations du header HTTP Accept. Si le client attend une réponse sous forme de HTML (Accept: text/http), le serveur renvoi une page web. Si le client attend une réponse sous forme de RDF (Accept: application/rdf+xml), le serveur fourni une représentation formalisée dans le langage RDF. Ce mécanisme permet de publier simplement des informations dans un formalisme compréhensible par la machine et ainsi d’étendre le Web de Document pour en faire un endroit accessible à tous (hommes et machines).
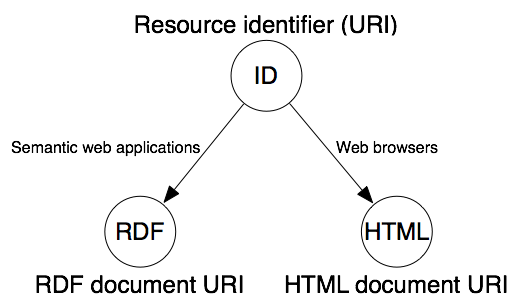 https://www.w3.org/TR/cooluris/[/caption]
https://www.w3.org/TR/cooluris/[/caption]
Comment décrire ses ressources avec RDF ?
Désormais, Bob sait de quelle manière adresser des ressources et comment récupérer leur description dans le langage RDF. Le RDF est un langage permettant de représenter l’information et la rendre accessible à une machine (de la même manière que le langage HTML le fait pour un humain). Dans cette partie, nous allons voir comment l’information est représentée en RDF et comment il est possible d’exploiter ce langage pour établir des liens entre les ressources du Web Sémantique.
Le RDF est un langage proposant une grammaire simple de description des données. Cette grammaire est composée des 3 éléments suivants :
- le sujet : il s’agit de la ressource à décrire.
- le prédicat : il s’agit du type de propriété utilisée pour décrire la ressource. Cette propriété est orientée.
- l’objet : il s’agit de la valeur de la propriété, il peut également s’agir d’une ressource.
Cette grammaire est similaire à la structure d’une phrase simple sujet-verbe-complément. Ainsi, en RDF, la phrase “Shakespeare est un artiste” est représentée de la façon suivante :

Nous avons vu que les ressources du Web Sémantique étaient représentées par des URI. En remplaçant chacun des éléments de la proposition, nous obtenons alors :
| sujet | prédicat | objet |
|---|---|---|
| <https://dbpedia.org/data/William_Shakespeare> | <https://www.w3.org/1999/02/22-rdf-syntax-nf#type> | <https://dbpedia.org/data/Artist> |
La combinaison de ces 3 éléments se nomme un triplet. Dans la mesure où les sujets et les objets qui composent un triplet sont des ressources, plusieurs triplets forment un graphe orienté. Cette structure de graphe permet d’enrichir simplement la masse d’informations représentées par le RDF. En reprenant l’exemple précédent, il est possible d’ajouter la proposition “Shakespeare a écrit Roméo et Juliette” en ajoutant le triplet correspondant :

Le graphe ainsi formé permet de formaliser les informations relatives à William Shakespeare. La machine dispose ainsi d’une représentation de l’information qu’elle est en mesure de comprendre et d’exploiter. Ce modèle de graphe permet d’agréger les données provenant de différentes sources et de présenter à Bob les éléments pertinents. Ainsi, si le site A contient des informations relatives à l’art et le site B contient des informations relatives à la programmation culturelle du pays de Bob, il est possible de dire à Bob : “une représentation de la pièce Roméo et Juliette est programmée dans le théâtre du coin de ta ville le 12 juillet 2058”.
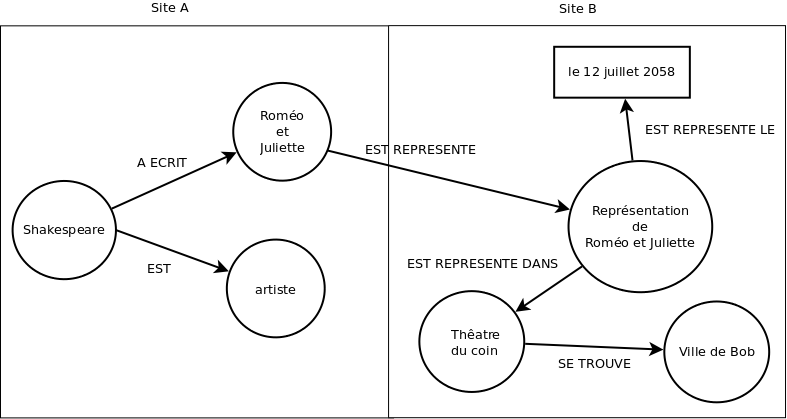
Les possibilités offertes sont immenses : il est possible de compléter le graphe avec des informations sur le prix des représentations, avec les données de géolocalisation du théâtre, avec les autres oeuvres de Shakespeare, avec les avis des internautes, etc. Ainsi, un agent sémantique de réservation de pièces de théâtre peut récupérer les informations en RDF issues de différentes sources et les traiter selon les critères de Bob (auteur, prix des places, éloignement du théâtre, etc.).
Comment formater les triplets RDF ?
Le RDF étant un langage de description des données, un document formalisé dans ce langage est destiné à être lu et échangé. Il est donc indispensable de définir un format dans lequel sérialiser les triplets qui composent les graphes. Le RDF admet les formats de sérialisation suivants :
- le XML : il s’agit du format de sérialisation usuel pour le RDF. Il est verbeux et difficile à lire.
- le N-Triples : il s’agit simplement de la liste des triplets (chaque triplet occupe une ligne). Ce format est facile à parser et à générer mais difficile à interpréter pour les humains.
- le Turtle (Terse RDF Triple Language) : il s’agit d’une forme de sérialisation plus compacte et plus facile à lire que le XML. Il s’approche du format N-triples dans lequel les triplets sont regroupés et factorisés par sujet.
- le Notation3 (ou N3) : ce format est très proche du Turtle mais il permet également d’exprimer des éléments supplémentaires (non RDF) permettant d’augmenter l’expressivité du document.
Il est important de noter que le XML n’est qu’un format de sérialisation parmi d’autres (même s’il est souvent privilégié). Le RDF n’est donc pas un simple vocabulaire XML. Il s’agit d’une manière de représenter les données basée sur le paradigme “sujet-prédicat-objet”. C’est ce paradigme qui autorise la construction de graphes, qui sont des constructions souples et extensibles pour exprimer des informations.
Conclusion
Bob est soulagé. Il dispose d’un formalisme permettant d’aggréger les informations, ce qui le dispense d’effectuer ce travail lui-même. Reste un problème majeur pour Bob : comment interpréter les données acquises ? Dans l’article, nous avons assumé que l’assertion RDF “Shakespeare EST artiste” signifie qu’il existe un lien sémantique de subsomption (ou d’instanciation) entre Shakespeare et artiste. Nous avons tous fait cette assertion parce que nous savons ce que le prédicat “EST” signifie. Mais comment la machine le sait-elle ? Par exemple, comment peut-elle fournir la liste des artistes anglais du 16ème siècle si elle ignore comment qualifier la relation “EST” ? Dans le prochain épisode, nous verrons comment les langages RDFS et OWL permettent de répondre à cette question.
Références
https://www.scientificamerican.com/article.cfm?id=the-semantic-web
https://www.urfist.cict.fr/archive/lettres/lettre28/lettre28-22.html
https://www94.web.cern.ch/WWW94/
https://dbpedia.org/About
Sources
https://www.w3.org/Talks/WWW94Tim
https://www.w3.org/TR/cooluris/
https://www.w3.org/RDF/
https://www.lespetitescases.net/les-technologies-du-web-semantique