
Clean Code avec le Kata Video Store » Refacto d’oncle Bob – Les tests


Après notre analyse préliminaire, poursuivons notre exercice de Clean Code autour du kata Video Store. Pour se faire, penchons-nous sur le refacto réalisé par oncle Bob. Étudier comment un maître Craft procède est toujours riche d’enseignements. Quand on est débutant Craft, on peut facilement se retrouver perdu, ne sachant pas trop par où commencer, comment procéder et quand s’arrêter.
Nous verrons donc :
- Où commence oncle Bob,
- Comment il procède pour refactorer le code :
- Son analyse du code, aboutissant à la détection de code smells,
- Son exécution des techniques de refactoring, en s’appuyant sur son IDE de manière poussée,
- Quand il s’arrête, ayant réalisé le but premier du kata : obtenir un code beaucoup plus propre et orienté-objet, dans un délai raisonnable.
Nous garderons un regard critique, comme s’il s’agissait d’une revue de code : des points ont-ils été oubliés ? Peut-on faire mieux ou autrement ?
👉 Code source
– Pour mieux suivre les modifications dans le code, j’ai reproduit les opérations effectuées par oncle Bob pour avoir les commits intermédiaires qui ne sont pas sur son github.
– Venant du monde .NET, il était plus simple pour moi d’écrire le code en C#, avec toutes ses spécificités par rapport au Java : propriétés plutôt qu’accesseurs, nommage des méthodes en PascalCase plutôt que camelCase, typedecimalpour les montants, membres expression-bodied, etc.
– Je ferai référence tantôt au code Java écrit par Oncle Bob, tantôt à son équivalent C# que j’ai reproduit.
🔖 Sommaire:Préambule/Survol rapide/Refacto des tests/Remarques·⏳ 15 min
Préambule
Commençons par un petit rappel sur le terme refactoring, « réusinage » en français strict mais peu employé, abrégé en refacto par la suite : il s’agit de modifications du code qui n’altèrent pas le comportement, les fonctionnalités du logiciel. On peut ensuite raffiner selon le facteur d’échelle :
- À un niveau atomique, cela désigne une petite opération, réalisée de préférence avec la fonction intégrée dans son IDE. La portée de cette opération n’est pas forcément courte. Exemple : le renommage d’une variable est local à une méthode, tandis que le renommage d’une méthode va impacter tous les appelants, et sur une interface ou une classe héritée, toutes les classes dérivées.
- À un niveau logique, cela correspond aux refactorings de plus haut niveau, tels que ceux plus complexes décrits par Martin Fowler. Ils nécessitent en général plusieurs opérations successives dans son IDE.
- À un niveau général, on emploie l’expression « refactorer du code » lorsque l’on modifie du code. Attention à ne bien l’employer que dans le cas où le comportement n’est pas modifié. Alors, cela peut se faire avec différents refactorings des deux niveaux précédents.
Le refacto adresse duplication et autres smells. Le but est d’améliorer le code, son design, pour le rendre plus lisible, explicite, expressif, c’est-à-dire plus maintenable et moins source de bugs en cas de modification.
L’autre axe d’amélioration du code concerne la performance. Refacto et performance correspondent respectivement aux deux dernières phases du principe Make it work, make it right, make it fast.
Les katas de refacto portent surtout sur le make it right. Ils sont assez remarquables pour démontrer la quantité de code que l’on peut modifier sans altérer le comportement du logiciel.
Survol rapide
Oncle Bob commence par un survol rapide des 4 fichiers pour avoir une vision d’ensemble et jauger la qualité du code. Sa première impression, “it’s a mess !”, n’est pas étonnante pour un tel kata :
- Les champs sont déclarés tantôt en haut des classes, selon la convention moderne des langages tels que C# et Java, tantôt en bas comme en « bon vieux C++ ».
- La classe
Movie➚ comporte un ensemble de constantes entières (public const int NEW_RELEASE = 1...), même pas dans uneenum. - La classe
Rental➚ n’a aucune méthode. C’est un simple DTO. En terminologie DDD, une telle classe métier, au cœur du domain model pourtant dépourvu de comportement, est dite anémique. C’est considéré comme un smell voire comme un anti-pattern. - La méthode
Statement()➚ de la classeCustomerest un exemple de programmation impérative où les structures de contrôle (blocsif,switch, boucleswhile…) sont mélangées avec la logique métier. L’indentation hétérogène rajoute de la difficulté pour lire le code.
Refacto des tests
Dans ce kata, il y a des tests. Un autre kata de refacto bien connu est le Gilded rose. À l’origine, il ne comportait même pas de test, comme du vrai code legacy ! Tout kata de refacto bien réalisé commence par les tests, qu’il s’agisse de les écrire ou des refactorer.
Oncle Bob commence ainsi le kata par la classe VideoStoreTest➚. Il ne le montre pas tout de suite mais les tests sont bien tous verts. Par contre, il ne vérifie pas la couverture du code par les tests. Or, nous avons vu précédemment qu’il y a justement un cas non couvert passant entre les mailles du filet, notre suite de tests.
⚠️ Attention
La confiance en une suite de tests s’acquiert. Il s’agit d’un vrai filet de sécurité lorsque tous les cas et toutes les branches sont couverts. Sinon, on peut s’embarquer dans des refactos, parfois risqués car à la main plutôt que via l’IDE, se pensant à l’abri, et finir par créer une régression constatée bien plus tard.
Plusieurs choses ne lui conviennent pas dans le code de ces tests :
Scroll vertical
Plusieurs lignes sont trop longues (jusqu’à 190 caractères) et obligent à faire défiler à droite pour tout lire. Oncle Bob y remédie facilement en reformatant les lignes, ceci en insérant judicieusement des retours chariots juste après les \n dans les chaînes de caractères.
Remarques :
- L’IDE d’oncle Bob, IntelliJ, lui facilite la vie en séparant la string en deux :
"abc\n‸def"→"abc\n" +↵"def". - En C#, je préfère utiliser une verbatim string (
@"...") pour voir les retours chariots directement dans la chaîne façon WYSIWYG plutôt que les\n.
→ Cf. commit Suite du refacto des tests… - En revanche, cela oblige à utiliser les retours chariots système (
Environment.NewLine) dans le code de production pour ne pas avoir de tests en rouge pour des différences au niveau des retours chariots (\r\nWindows vs\nUnix).
→ Cf. commit Fix typo and NewLine issue - En TypeScript, l’équivalent peut être réalisé avec une template string`…`.
Assertions
Les assertions dans les tests sont de ce type :
public void testSingleNewReleaseStatement() {
customer.addRental(new Rental(new Movie("The cell", Movie.NEW_RELEASE), 3));
assertEquals(
"Rental Record for Fred\n" +
"\tThe cell\t9.0\n" +
"You owed 9.0\n" +
"You earned 2 frequent renter points \n",
customer.statement());
}
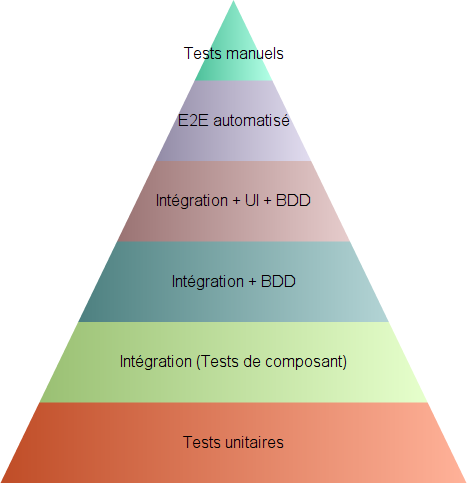 Les tests vérifient que le rapport est bien formaté et au travers de cela les valeurs attendues. Il s’agit donc de tests d’UI, de présentation. Ils sont très fragiles car sensibles aux moindres variations dans la présentation. Les tests d’intégration sont aussi fragiles, un peu moins que les tests d’UI, car ils traversent plusieurs couches applicatives et sont donc sensibles aux variations dans ces couches. C’est pour cela qu’il est préférable d’avoir une répartition des tests en pyramide(image ci-contre) plutôt qu’en « cône glacé », la pyramide à l’envers.
Les tests vérifient que le rapport est bien formaté et au travers de cela les valeurs attendues. Il s’agit donc de tests d’UI, de présentation. Ils sont très fragiles car sensibles aux moindres variations dans la présentation. Les tests d’intégration sont aussi fragiles, un peu moins que les tests d’UI, car ils traversent plusieurs couches applicatives et sont donc sensibles aux variations dans ces couches. C’est pour cela qu’il est préférable d’avoir une répartition des tests en pyramide(image ci-contre) plutôt qu’en « cône glacé », la pyramide à l’envers.
Oncle Bob applique ce principe ainsi :
- Il transforme ces quatre tests pour qu’ils deviennent des tests unitaires : leurs assertions porteront non pas sur le rapport formaté mais sur les valeurs contenues dans ce rapport.
- Il conserve l’un des anciens tests en tant que test d’UI.
- La proportion 1 / 4 est alors en accord avec une pyramide de tests équilibrée.
Oncle Bob procède en pur TDD, en commençant par les tests pour les faire piloter le design du SUT :
- Transformation des asserts pour vérifier les valeurs :
assertEquals(9.0, customer.getTotal()),assertEquals(2, customer.getFrequentRenterPoints()).
- À ce moment, les méthodes
getTotal()etgetFrequentRenterPoints()n’existent pas encore dans la classeCustomer. Son IDE lui permet alors de les créer en une seule action appelée quick fix, avec (presque) la bonne signature. - Oncle Bob fournit une implémentation fausse,
return -1, et joue les tests pour vérifier que ceux modifiés sont bien rouges. - Pour fournir une bonne implémentation, il se sert des variables existantes
totalAmountetfrequentRenterPointsdans la méthode testéestatement().- Il promeut les champs de la classe, privés et initialisés dans la méthode, grâce au refacto Introduce Field.
🕵 On remarque au passage que son IDE signale ce changement en utilisant une couleur différente pour distinguer les variables locales (en noir) des champs (en violet), ce qui est pratique en Java et C# où le préfixethis.n’est nécessaire qu’en cas de conflit de noms, contrairement au TypeScript 😢. - Ne reste plus qu’à s’en servir pour l’implémentation des getters :
public double getTotal() { return totalAmount; } - Et enfin rejouer les tests pour vérifier qu’ils sont repassés en vert.
- Il promeut les champs de la classe, privés et initialisés dans la méthode, grâce au refacto Introduce Field.
Anonymisation
L’anonymisation est un aspect important dans l’écriture de tests unitaires pour les rendre compréhensibles et maintenables. L’exécution d’un test unitaire nécessite un ensemble de données en entrée. Certaines sont porteuses du cas de test tandis que d’autres ne le sont pas, tout en devant être valides parfois. Il s’agit de pouvoir lire le test unitaire et identifier aisément la catégorie de chaque donnée. On va chercher à réduire le bruit des données annexes pour que le cas de test soit clair.
On retrouve cette distinction dans les doublures de tests (Test Doubles), entre un Dummy, dont les données ne sont pas importantes pour le test, et les autres types de doublures. Pour approfondir ces notions, vous pouvez lire la référence en la matière pour moi : l’article Mocks Aren’t Stubs écrit par Martin Fowler en 2007.
⚠️ Attention
Ne pas confondre l’anonymisation des données de test avec :
– Les classes anonymes en Java,
– Les fonctions anonymes présentes dès C# 3.0 et Java 8,
– Les types anonymes en C# 3.0.
Oncle Bob adresse cette problématique en identifiant des données trop spécifiques, ce qui trompe sur leur importance :
- Le nom du client est initialement
"Fred"➚. Or, les cas de tests ne portent pas sur un client en particulier. Oncle Bob modifie ce nom pour le rendre plus anonyme, plus quelconque, mais pas totalement aléatoire non plus :"Customer"représente bien un client quelconque. Sauf que l’on perd le fait qu’il s’agisse du nom du client."CustomerName"conviendrait mieux à mon avis. - Le titre des films n’a pas d’influence. Comme le nom du client, il apparaît dans le rapport final mais n’impacte pas les calculs. En revanche, on peut s’en servir pour identifier le cas de test. C’est ce que fait oncle Bob en passant de
"The Cell"➚ à"New Release 1"et"New Release 2"➚. Cela donne dans mon code"NEW_RELEASE_1 ... 2"car je me suis épargné de retaper ces chaînes en copiant simplement le nom de la constanteMovie.NEW_RELEASEqui convient également.
Idem concernant le nom des variables : newReleaseMovie1 est un meilleur nom que theCell ou movie1. En fait, on n’a même pas besoin de spécifier le type, Movie : newRelease1 est suffisamment parlant. D’ailleurs, on voit oncle Bob mettre tantôt Movie à la fin des noms, tantôt rien. Lui qui aime bien les symétries dans le code, c’est juste un oubli.
👉 Préconisation
Quelle que soit la convention de nommage utilisée (ici, avec ou sansMovieà la fin), il est important de la suivre partout au sein d’un fichier. Cela donne un code plus homogène et donc plus facile à lire.
Duplication
On note qu’oncle Bob promeut en champs de la classe de tests le SUTstatement et les films newRelease1, ... servant de données de tests. Ces champs sont initialisés dans la méthode setUp()➚ (définie dans la classe de base TestCase ou avec l’annotation @BeforeAll selon la version de jUnit). L’avantage est de pouvoir raccourcir la phase Arrange du pattern AAA et de réduire la duplication. Cela ne nuit pas à la lisibilité car le nom des champs est d’une part suffisamment court, d’autre part assez précis pour que l’on n’ait pas besoin de regarder leur valeur. L’inconvénient est que chaque test n’utilise qu’une partie de ces champs. Les autres ont été créés pour rien. Si cela posait un problème de performance (durée de création trop longue, occupation mémoire excessive…), il ne pourrait pas procéder ainsi.
☝️ Côté C#
J’ai utilisé le framework de test xUnit.net. Contrairement à jUnit, nUnit, MsTest entre autres, l’initialisation des champs ne se fait pas dans une méthode “setUp” mais a lieu soit dans le constructeur, soit avec leur déclaration comme dans mon cas. Dans les deux cas, l’avantage est de pouvoir marquer ces champs comme readonly. Cependant, xUnit créant une nouvelle instance de la classeVideoStoreTestsà chaque test, on pourrait les placer dans une class fixture pour ne les créer qu’une seule fois et partager les mêmes instances entre tous les tests.
Pour la promotion de variables en champs, oncle Bob utilise le refacto Extract Field, également appelé Introduce Field, qui permet de remplacer plusieurs occurrences d’un seul coup : c’est à la fois un gain de temps et cela permet de repérer et traiter de la duplication de code.
Contrairement au refacto que j’ai vu, dans son repo oncle Bob se sert d’une méthode helperassertAmountAndPointsForReport()➚. Cela permet de mutualiser les phases Act et Assert entre plusieurs tests. De plus, traiter la duplication, cela fait des méthodes de test courtes, ce qui va dans le sens des small functions du clean code, ses principes s’appliquant partout, tant dans le code de production que dans les tests. On peut aussi avoir des méthodes helpers utilisées lors du Arrange, par exemple du type createSut() ou createNewReleaseMovie(), en alternative à leur création dans le set up vu précédemment.
Equilibre DRY-DAMP
Dans une perspective BDD et de l’écriture de tests d’acceptation (acceptance tests), on pourrait pousser l’utilisation de méthodes helpers encore plus loin et écrire un véritable petit DSL suivant le format Given, When, Then :
public void SingleNewRelease()
{
GivenRental(movie: newRelease1, daysRented: 3);
WhenGenerateStatement();
ThenAmountIs(9.0m);
AndPointsAre(2);
}
Cet exemple présente des qualités : fonction courte (4 lignes), phases AAA visibles, code expressif, niveau d’abstraction uniforme. En revanche, comme il cache plus les détails techniques, cela peut être plus difficile à déboguer et on perd le côté documentation de bas niveau.
Je vous déconseille de pousser loin la complexité d’un tel DSL. On pourrait en effet traiter le couplage temporel en forçant au niveau compilation l’ordre d’exécution Given puis When puis Then, ceci en chaînant les méthodes et en restreignant lesquelles sont possibles par l’emploi d’interfaces à la manière des fluent builders les plus perfectionnés. Cela donnerait dans le test :
public void SingleNewRelease()
{
Given
.Rental(movie: newRelease1, daysRented: 3)
.When
.GenerateStatement()
.Then
.AmountIs(9.0m)
.And.PointsAre(2);
}
Je trouve cela « classe ». Par contre, un tel DSL est coûteux à écrire et cela rajoute de la complexité dans le code de tests. Or, on cherche à ce que l’analyse d’un test qui échoue soit facile. Mieux vaut avoir du code de test simple, facile à comprendre et donc à maintenir, où l’on comprend comment est utilisé le SUT, ceci pour servir également de documentation de bas niveau. De même, la simplicité passe par une complexité cyclomatique basse : 1 est idéal, parfois 2 avec un forEach pour faire des tests paramétrés sans l’aide du framework de test, ce qui est le cas en JavaScript/TypeScript avec Jasmine, Jest…
On peut donc se permettre un peu de duplication dans les tests si cela favorise la simplicité tout en conservant la lisibilité et la maintenabilité. Il s’agit de chercher un équilibre entre les deux principes DRY et DAMP comme l’explique cette réponse sur Stack Overflow, avec le jeu de mots en anglais (dry-sec / damp-humide) comme moyen mnémotechnique.
Quand on développe une nouvelle fonctionnalité en TDD, le respect de la décomposition des phases Red, Green, Refactor implique de passer le plus rapidement possible de Red à Green, incluant la possibilité de faire des copier-coller, y compris dans les tests. Ce n’est qu’en phase Refactor que l’on traite les duplications et donc de l’équilibre DRY / DAMP.
Fin
Oncle Bob termine le refacto des tests lorsqu’il constate que “The tests say what they test in a pretty clear term”. Il n’est plus nécessaire d’aller plus loin. Le code des tests est suffisamment clair, clean. Il y a passé vingt minutes sur l’heure que prend tout l’exercice. C’est dire l’importance accordée aux tests, en particulier pour qu’ils soient en clean code.
Remarques
Encapsulation
Lors du refacto des asserts, oncle Bob a transformé les variables totalAmount et frequentRenterPoints en champs et les a exposés au moyen de getters pour pouvoir valider l’effet de la méthode testée. En faisant cela, on conserve un niveau d’encapsulation : les champs restent privés et exposés uniquement en lecture seule.
Malgré tout, on expose l’état interne d’un objet. Cela peut déranger d’un point de vue purement OOP dont l’encapsulation est l’un des piliers, avec le polymorphisme et l’héritage. Depuis la perspective clean code, ça l’est moins : la testabilité prime sur l’encapsulation. Oncle Bob utilise l’expression Tests trump Encapsulation et l’explique dans son article The Little Singleton.
Ceci est sujet à débat. Il existe d’ailleurs d’autres techniques plus ou moins propres pour contourner l’encapsulation dans les tests. Julien Fiaffé en présente quelques unes, plutôt pour les développeurs .NET, dans son article Unit tests and protected methods.
Test qui « pique les yeux »
Si l’on revient à notre cas, le problème est apparu dans les tests. Or, lorsque l’on tombe sur un test qui « pique les yeux », cela révèle souvent un problème dans le design du code de production. En effet, on constate que notre objet statement fait 2 choses : il calcule l’état pour un client et génère un rapport. Répartir ces responsabilités dans deux classes amène naturellement à la séparation opérée par oncle Bob dans les tests, ceci directement dans 2 classes de tests distinctes respectivement à ces 2 classes de prod.
Malgré tout, comme on est dans du refacto de legacy, les opérations réalisées par oncle Bob constituent une étape intermédiaire avant la séparation en deux classes.
Couplage temporel
Avec le design proposé à ce moment par oncle Bob, les champs totalAmount et frequentRenterPoints (et leur getter associé) n’ont de sens qu’après avoir appelé la méthode statement() qui les initialise. Oncle Bob est confronté au problème lors du refacto du test mais ne semble pas y voir un problème autre qu’une mauvaise manipulation temporaire, vite vue en jouant les tests qui échouent alors et aussi vite corrigée en remettant l’appel à statement() avant les asserts.
D’ailleurs, si l’on en revient aux trois phases AAA, on s’en rend compte rapidement : il manque la phase Act ! Soit dit en passant, si le test n’était pas passé rouge en dépit de cela, c’eût été signe de son inutilité.
Pourtant, il s’agit bien d’un problème dans le design : un couplage temporel. Il faut appeler generate() avant de pouvoir appeler getTotal(). De plus, ce n’est pas du tout explicite : il faut lire le code pour le comprendre. Enfin, heureusement que l’on appelle la méthode clearTotals() à chaque appel à generate(). Sinon, les totaux seraient doublés à chaque appel ! La séparation en 2 classes selon leur responsabilité (calcul et formatage) évoquée plus haut permet de résoudre ces problématiques.
Conclusion
Rien qu’en étudiant le refacto des tests, nous avons abordé beaucoup d’éléments de clean code :
- Améliorer la lisibilité en limitant le scroll vertical,
- Supprimer la duplication :
- En utilisant des données de test initialisées dans le set up,
- En anonymisant celles qui ne sont pas déterminantes pour les tests,
- En ne gardant qu’un test d’UI, en transformant les autres en vrais tests unitaires vérifiant des données brutes, ce qui les rend moins fragiles.
Tout ceci rend les tests plus expressifs et permet de détecter des problèmes dans le design du code de production : la brèche dans l’encapsulation, le couplage temporel révélant une possible violation du SRP.
Pour ne pas faire trop d’un coup, nous verrons dans un prochain article la suite du refacto, celle du code de production. C’est là que l’on sera confronté à divers smells, à traiter par des refactos bien ciblés et en faisant un usage poussé de notre IDE.
© SOAT
Toute reproduction interdite sans autorisation de l’auteur