
Akka.Net – Soyons résilients !

Résilience, qu’est-ce que c’est ?
Comme nous l’avons vu dans l’article “Les systèmes réactifs et le pattern actor model“, l’une des quatre caractéristiques qu’un système réactif doit posséder est la résilience.
 La résilience d’un système représente sa capacité à assurer sa disponibilité en cas d’erreur au sein d’un de ses composants. Les exceptions sont gérées localement et isolées afin de garantir une continuité de service (éventuellement dégradée) acceptable.
La résilience d’un système représente sa capacité à assurer sa disponibilité en cas d’erreur au sein d’un de ses composants. Les exceptions sont gérées localement et isolées afin de garantir une continuité de service (éventuellement dégradée) acceptable.
Il est primordial de penser cette gestion des exceptions dès le début de la conception de l’architecture du système afin de cloisonner et limiter au mieux les effets de bord d’un impondérable. Le système doit être capable de minimiser ses impacts, et idéalement, de pouvoir retrouver son fonctionnement nominal lors de la résolution du problème.
La mise en place de la résilience dans un système d’acteurs Akka.Net est rendue possible via la notion de supervision.
Dans un actorSystem, tout acteur est le subordonné d’un autre qui le supervise.
Avant de parler de supervision, il est nécessaire de comprendre le cycle de vie d’un acteur, de son instanciation à son arrêt.
Cycle de vie d’un acteur
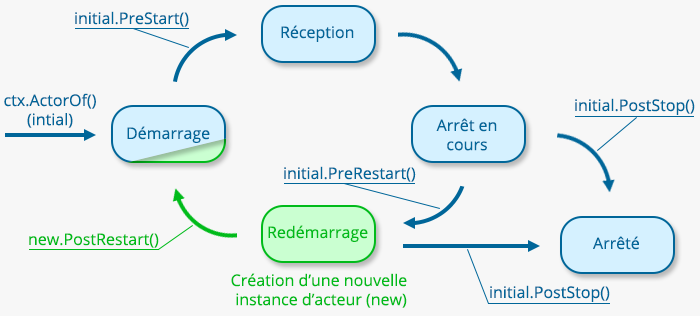
Lors de son fonctionnement, un acteur passe par plusieurs états :
- Démarrage : Après son instanciation ou après un redémarrage.
- Réception et traitement des messages : Il s’agit de l’état principal de l’acteur. C’est dans cet état que l’acteur remplit ses fonctions.
- En cours d’arrêt : À la fin de son fonctionnement, l’acteur passe par cet état transitoire avant d’être arrêté ou redémarré.
- En cours de redémarrage : Avant d’être redémarré, un acteur passe par cet état de transition, il peut être utile pour assurer la transition avec le nouveau cycle de vie.
- Arrêté : L’acteur est arrêté et son cycle de vie est terminé.
Techniquement, ces états ne sont pas implémentés dans Akka.Net et ne sont pas utilisables directement. En revanche, les transitions sont matérialisées par des méthodes invoquées (définies dans la classe ActorBase) lors de l’évolution de l’acteur, et permettent de pouvoir interagir avec l’acteur au cours de son cycle de vie si nécessaire en les surchargeant.
Le redémarrage d’un acteur peut survenir lorsqu’un acteur lève une exception et que la stratégie de supervision détermine que celui-ci doit redémarrer, nous verrons cela dans la suite de cet article.
Il est important de comprendre que lors du redémarrage d’un acteur, c’est une nouvelle instance d’acteur qui est créée. Si des informations doivent être persistées entre l’acteur d’origine et la nouvelle instance, c’est via ces surcharges de méthode que cela doit être fait.
- PreStart : Cette méthode est invoquée juste après la création d’une nouvelle instance de l’acteur.
- PostStop : Cette méthode est appelée juste après l’arrêt de l’acteur. Elle peut notamment être utilisée pour libérer les ressources utilisées par l’instance de l’acteur.
- PreRestart : PreRestart est invoquée sur l’acteur d’origine pour indiquer qu’il va subir un redémarrage (PostStop sera appelée ensuite). Cette méthode reçoit notamment en paramètre le message à l’origine du redémarrage.
- PostRestart : PostRestart est invoquée avant la méthode PreStart afin d’indiquer à un acteur en cours d’initialisation qu’il est instancié à la suite d’un redémarrage.
Lors d’un redémarrage, l’instance d’origine recevra donc les appels aux méthodes PreRestart puis PostStop avant d’être détruite. Alors que la nouvelle instance recevra PostRestart puis PreStart.
Pour pouvoir se greffer dans le cycle de vie d’un acteur, il est nécessaire de surcharger ces méthodes :
public class TransitionActor: UntypedActor
{
protected override void PreStart()
{
// Implémenter ici les actions preStart
base.PreStart();
}
protected override void PostStop()
{
// Implémenter ici les actions postStop
base.PostStop();
}
protected override void PreRestart(Exception reason, object message)
{
// Implémenter ici les actions preRestart
base.PreRestart(reason, message);
}
protected override void PostRestart(Exception reason)
{
// Implémenter ici les actions postRestart
base.PostRestart(reason);
}
}
Une fois ces surcharges mises en place (surcharger uniquement les méthodes nécessaires), il est alors possible de contrôler finement l’état d’un acteur et pouvoir persister des états en cas d’exceptions.
Nous venons de voir le cycle de vie d’un acteur, nous savons instancier un acteur et lui envoyer des messages, voyons maintenant comment l’arrêter explicitement.
Comment arrêter explicitement un acteur ?
Lors du traitement des messages, un acteur peut décider d’arrêter un ou plusieurs de ses enfants, voire s’arrêter lui-même.
Il y a principalement trois méthodes pour arrêter un acteur et il est important de bien comprendre chacune d’elles, ainsi que leurs spécificités, pour adapter leur utilisation à votre besoin.
Context.Stop
Il est possible d’appeler la méthode Stop sur le Context courant :
Context.Stop(actorToStop);
Lors de cet appel, actorToStop termine le traitement du message en cours (s’il y en a) puis s’arrête (PostStop()).
Messages PoisonPill et Kill
Il est également possible d’envoyer un message demandant à l’acteur de s’arrêter. Celui-ci s’arrêtera donc lors du traitement de ce message. L’acteur finira ainsi de traiter l’ensemble des messages empilés avant la demande, puis s’arrêtera (en interne, Akka.Net utilise la méthode Stop() vue précédemment).
Il existe deux types de messages de demande d’arrêt :
- PoisonPill
- Kill
Pour demander l’arrêt à actorToStop il suffit donc de lui envoyer un message PoisonPill ou Kill :
actorToStop.Tell(PoisonPill.Instance);
actorToStop.Tell(Kill.Instance);
Ces messages provoquent donc, tous les deux, l’arrêt de actorToStop (après avoir purgé sa file de messages en attente), cependant Kill génère une exception de type ActorKilledException. Cette exception peut être intéressante dans le cadre de la supervision. Nous verrons la supervision dans la suite de cet article.
La méthode d’extension GracefulStop
Les deux méthodes évoquées ci-dessus sont du type fire and forget, c’est-à-dire que l’on demande un arrêt, mais aucun retour ne nous renseigne sur le résultat de cette demande. Pour pouvoir être informé lors de l’arrêt d’un acteur, il existe la méthode d’extension GracefulStop. Il s’agit d’une méthode asynchrone qui permet d’attendre le résultat de la demande d’arrêt. Elle reçoit en paramètre une propriété timeout qui permet de définir une limite de temps d’attente avant de considérer la demande en échec.
GracefulStop est très utile lorsque l’on souhaite contrôler de manière spécifique l’arrêt d’acteurs (pour les ordonnancer par exemple).
Le résultat de cette méthode asynchrone est de type bool et permet de savoir si l’arrêt a réellement eu lieu.
// public static Task<bool> GracefulStop(this IActorRef target, TimeSpan timeout)
var hasStopped = await actorToStop.GracefulStop(TimeSpan.FromMilliseconds(2000));
En interne, GracefulStop utilise l’envoi d’un message PoisonPill, l’acteur finira donc de traiter les messages empilés avant la demande, puis s’arrêtera.
Surveiller l’arrêt d’un acteur
Nous avons vu comment se greffer dans le cycle de vie d’un acteur afin de pouvoir, entre autres, intervenir en cas d’arrêt de celui-ci. Mais cela se limite au scope de l’acteur lui-même. Dans le cas de la méthode PostStop, par exemple, c’est l’implémentation de l’acteur en cours d’arrêt qui détermine le comportement à adopter.
C’est là qu’intervient le DeathWatch ; un acteur peut en effet demander à surveiller spécifiquement l’arrêt d’un ou de plusieurs autres acteurs. Pour ce faire, il existe les méthodes Watch et Unwatch invoquables sur le Context courant.
// Être notifié de l’arrêt de l’acteur watchedActor
Context.Watch(watchedActor);
// Ne plus être notifié de l’arrêt de l’acteur watchedActor
Context.Unwatch(watchedActor);
Dans le cas de l’arrêt d’un acteur surveillé, l’acteur recevra alors un message de type Terminated, lui permettant d’identifier l’acteur arrêté.
Pour gérer ces messages, la déclaration est la même que pour un message classique :
Receive<Terminated>(msg =>
{
var terminatedActor = msg.ActorRef;
});
Il est important de noter que le message Terminated ne sera émis que lors de l’arrêt définitif de l’acteur.
Cet arrêt définitif peut survenir suite à une demande explicite (comme vu ci-dessus) ou lors de l’application d’une stratégie de supervision spécifique, suite à la levée d’une exception lors du traitement d’un message par l’acteur surveillé. Avec la stratégie de supervision par défaut, une exception ne déclenchera pas le DeathWatch.
Bien cloisonner les erreurs et les gérer localement – La supervision à la rescousse
L’un des principes fondamentaux du pattern Actor Model est qu’un acteur ne partage pas son état avec les autres, il n’est en effet pas possible pour un acteur d’accéder aux propriétés d’un autre.
Comment réagir lorsqu’un acteur lève une exception ? Comment en être informé ? Et surtout, comment gérer localement ces exceptions sans faire tomber le système entier ? La définition d’une stratégie de supervision doit être pensée au moment de la conception d’un système d’acteurs pour permettre d’appréhender sereinement toutes ces problématiques.
Qu’est-ce qu’une stratégie de supervision ?
Comme nous l’avons vu, tout acteur est le subordonné d’un autre qui le supervise. La supervision va permettre de définir le comportement à adopter lorsqu’un subordonné rencontre un problème.
En effet en cas d’erreur, le superviseur est notifié et peut alors agir en conséquence. Il va pouvoir décider comment gérer l’exception levée et ainsi cloisonner ce défaut de comportement sans impacter le reste du système.
Le superviseur va pouvoir agir sur tout ou partie de ses subordonnés (selon la stratégie adoptée) et pourra définir comment ses subordonnés doivent réagir (selon la directive choisie) en cas d’erreur.
Nous allons maintenant voir comment définir une stratégie.
Directives de supervision
La directive de supervision représente l’ordre que le superviseur donne à ses subordonnés suite à la remontée d’une exception.
Il existe 4 types de directives de supervision (listées dans l’enum Directive):
- Resume : Cette directive indique aux subordonnés de continuer leurs traitements sans s’arrêter. Le superviseur est donc notifié d’une exception et les subordonnés peuvent continuer de fonctionner sans altération.
- Restart : Le superviseur prend la décision de demander aux subordonnés de redémarrer. Les instances supervisées s’arrêteront donc et de nouvelles instances seront instanciées. Les méthodes PreRestart et PostStop seront invoquées sur les instances d’origine puis les méthodes PostRestart et PreStart seront invoquées sur les instances nouvellement créées. Les informations nécessaires peuvent être persistées via ces méthodes. Durant ce processus, tous les enfants des supervisés concernés seront arrêtés via un appel à Context.Stop. Un acteur ne partageant aucune information directement avec l’extérieur, une stratégie de redémarrage constitue souvent une bonne option en cas d’échec.
- Stop : Le superviseur appellera la méthode Context.Stop sur les supervisés concernés. Les enfants des supervisés concernés seront également arrêtés (via un appel à Context.Stop).
- Escalate : Le superviseur n’est pas en mesure de prendre une décision et délègue celle-ci à son propre superviseur. L’exception est donc remontée un cran plus haut dans la chaîne de supervision.
Les modes de supervision
Le mode de supervision représente le périmètre sur lequel un superviseur va appliquer ses directives suite à la remontée d’une exception.
Deux types de supervision sont possibles :
- OneForOneStrategy : Le superviseur décide d’appliquer la directive uniquement au supervisé ayant levé l’exception.
- AllForOneStrategy : Le superviseur décide d’appliquer la directive à l’ensemble des subordonnés dont il a la charge.
Différence d’application des deux stratégies avec l’exemple de la directive Restart :
Déclaration d’une stratégie de supervision
Pour déclarer une logique de supervision, il faut surcharger la méthode SupervisorStrategy() dans l’acteur en charge de la supervision :
protected override SupervisorStrategy SupervisorStrategy()
{
return new OneForOneStrategy(Decider.From(Directive.Stop));
}
Cette surcharge permettra de définir un mode de supervision OneForOne qui retournera toujours la directive Stop au subordonné qui lèvera une exception.
Il est possible d’aller bien plus loin dans la gestion des exceptions. Regardons l’exemple suivant :
protected override SupervisorStrategy SupervisorStrategy()
{
return new AllForOneStrategy(
maxNrOfRetries: 5, // par défaut : -1 pour un nombre de tentatives infini
withinTimeMilliseconds: 2000, // par défaut : -1 pour une fenêtre de temps infinie
localOnlyDecider: Decide);
}
private Directive Decide(Exception exception)
{
switch (exception)
{
case MyCustomException myException:
return Directive.Restart;
default: return Directive.Escalate;
}
}
Avec cette déclaration, nous définissons une stratégie de type AllForOne qui peut gérer spécifiquement le type d’exception MyCustomException et déléguer la gestion des autres erreurs à son superviseur (Directive.Escalate).
Dans le cas d’une exception de type MyCustomException, il décide de demander à ses subordonnés de redémarrer (Directive.Restart) mais si jamais les subordonnés ont levé plus de 5 exceptions (maxNrOfRetries) durant les 2 dernières secondes (withinTimeMilliseconds), il arrête ses enfants.
Il est intéressant de remarquer que dans la méthode SupervisorStrategy, vous êtes dans le contexte du superviseur, vous avez donc accès à l’ensemble de ses propriétés (enfants, parent, logger injecté…) et vous pouvez définir le comportement précis que vous souhaitez lors de l’application de votre stratégie de supervision.
Mais alors, quelle stratégie est appliquée quand aucune surcharge n’est définie ?
Par défaut, il s’agit d’une stratégie OneForOne retournant toujours la directive Restart sauf dans le cas des erreurs internes de type ActorInitializationException, ActorKilledException et DeathPactException où l’arrêt du subordonné est demandé.
Son implémentation est (notez au passage, le mode de déclaration des directives) :
protected override SupervisorStrategy SupervisorStrategy()
{
var decider = Decider.From(Directive.Restart,
Directive.Stop.When<ActorInitializationException>(),
Directive.Stop.When<ActorKilledException>(),
Directive.Stop.When<DeathPactException>());
return new OneForOneStrategy(decider);
}
Le cas des acteurs principaux (situés directement sous /user)
Il faut se rappeler que tout acteur instancié par nos soins vit sous un autre acteur dont il dépend. Dans le cas des acteurs principaux (instanciés via actorSystem.ActorOf), leur superviseur est le User Guardian (voir l’article “Akka.Net – les fondamentaux“).
La supervision de ces acteurs est donc définie dans l’acteur User Guardian instancié par le framework. Cette supervision peut être appliquée pour deux raisons : dans le cas d’une exception levée directement dans un acteur principal, ou lorsqu’un acteur principal décide d’appliquer une directive Escalate dans le cadre de la supervision de l’un de ses surbordonnés.
Le User Guardian applique la stratégie par défaut vue précédemment, il tentera donc de redémarrer l’acteur en échec à chaque exception.
Il est bon de savoir qu’il est possible de modifier la stratégie de supervision du User Guardian si cela ne convient pas à vos besoins, via un fichier de configuration (guardian-supervisor-strategy).
Mise en pratique
Le code source d’un projet illustrant tous ces principes est disponible à l’adresse suivante : Repository Github AkkaLifecycleAndSupervision
Conclusion
Le pattern actor model incite fortement la création d’instances d’acteurs pour décomposer les traitements et alléger au maximum la responsabilité de chaque entité. Cela a un coût en matière de maîtrise du cycle de vie des acteurs et de la supervision du système d’acteur.
Un système d’acteurs dont la supervision n’a pas été pensée dès le début de la conception devient vite ingérable et difficilement debuggable.
Akka.Net fournit les outils permettant de monitorer et de gérer au plus tôt les exceptions.
N’oubliez pas qu’il n’existe qu’un seul superviseur du système dans le cas où celui-ci s’écroule : vous. Simplifiez-vous la tâche, déléguez cette supervision au système lui-même en y pensant au début de votre projet 😉
© SOAT
Toute reproduction interdite sans autorisation de l’auteur