
Le partitionnement avec Redis

 Le partitionnement est un terme général utilisé pour décrire l’acte de répartir et distribuer les données à travers plusieurs instances de Redis.
Le partitionnement est un terme général utilisé pour décrire l’acte de répartir et distribuer les données à travers plusieurs instances de Redis.
Dans Redis nous avons deux types de partitionnement :
Le partitionnement horizontal : Consiste à distribuer les clés à travers les différentes instances de Redis (aussi connu sous le nom de ‘Sharding’).
Le partitionnement vertical : Consiste à distribuer les valeurs des clés à travers les différentes instances de Redis.
Dans cet article, nous allons présenter les différents types de partitionnement horizontal ou sharding, qui est l’approche la plus populaire utilisée avec Redis.
Range Partitioning
Supposons que nous avons 4 instances Redis et que nous voulons stocker des clés qui sont des prénoms de nos clients.
Le principe du “Range Partitioning” est de répartir ces prénoms sur, par exemple, la base de la première lettre.
Dans la première instance, nous stockons les prénoms qui commencent par les lettres allant de ‘A’ à ‘F’, dans la deuxième les noms allant de ‘G’ à ‘L’, dans la troisième les noms allant de ‘M’ à ‘R’, et le reste dans la quatrième instance.
Ce processus va donc partager les données (les prénoms des clients) en quatre différentes rangées, et chacune d’entre elles va être stockée dans une instance différente.
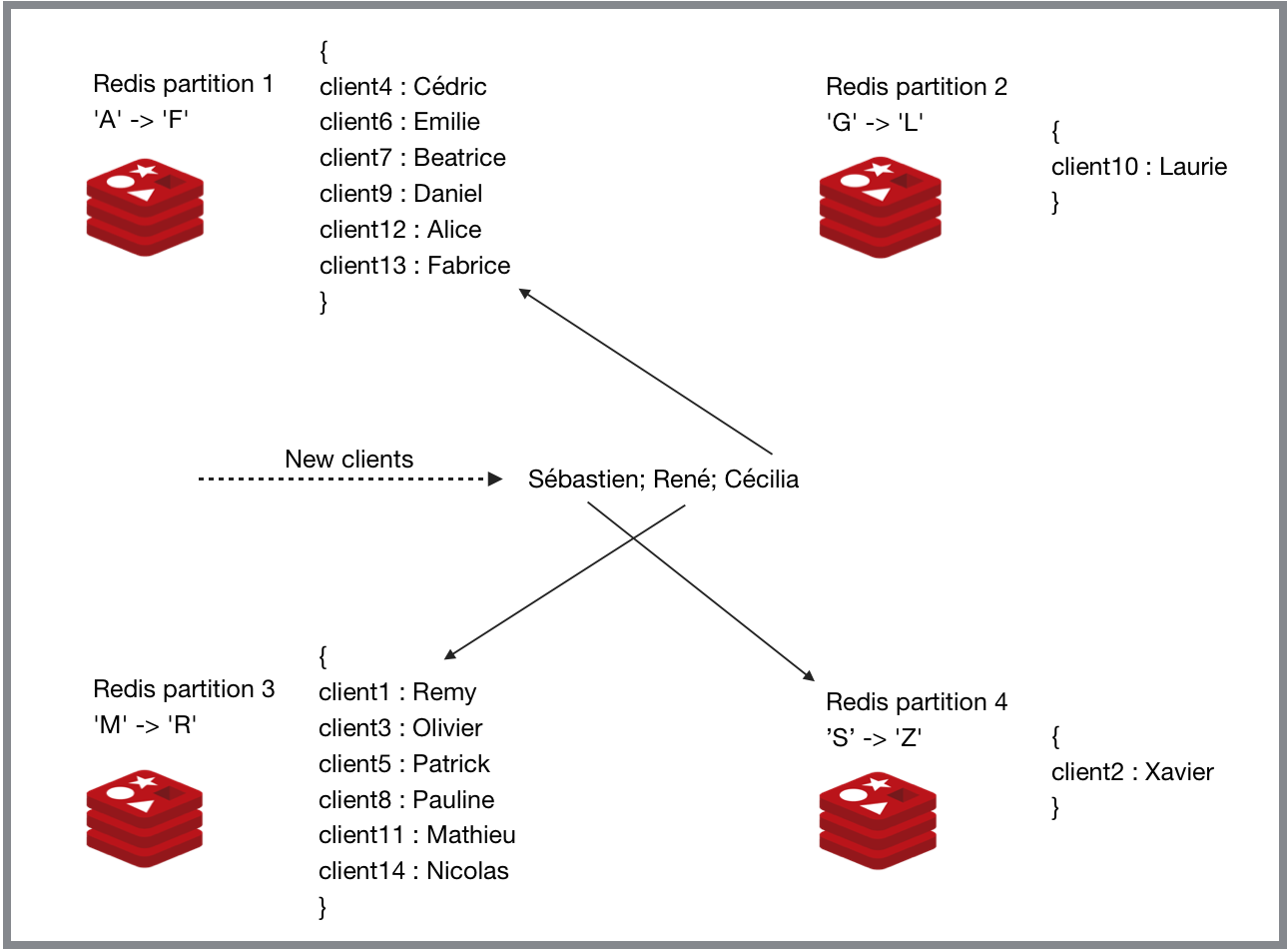
Le principal inconvénient avec cette méthode, est que les différentes instances ne vont pas être équilibrées. Nous risquons d’avoir une ou plusieurs instances qui sont beaucoup plus larges que d’autres.
Un autre inconvénient est que si nous rajoutons ou supprimons une instance Redis, ceci va avoir un impact sur le sharding. Il devient donc compliqué de faire des changements dans la liste des instances sans endommager le partitionnement.
Enfin, le dernier inconvénient à prendre en considération est que le “range partitioning” a besoin d’une table contenant un schéma, qui va diriger les clés vers leurs instances, et ceci doit être fait pour chaque type d’objets.
Hash Partitioning
Le partitionnement par hachage, contrairement au partitionnement par rangée, nous évite d’avoir des problèmes d’équilibre entre les instances.
Le partitionnement par hachage est une méthode très connue et facile à implémenter. Le principe est simple : appliquer la fonction de hachage sur la clé que nous allons stocker, puis diviser le résultat par le nombre d’instances disponibles, ce qui nous donnera l’index de l’instance que nous retrouverons à partir de la liste des instances que nous possédons.
Voici un bout de code en JavaScript qui pourra peut-être expliquer un peu mieux cette méthode :
var index = hashFunction(RedisKey) % redisInstances.length ;
var instance = redisInstancesList(index) ;
Il est recommandé avec cette méthode d’avoir un nombre premier d’instance Redis, pour minimiser les collisions.
Si le nombre d’instance Redis change, nous risquons d’avoir des problèmes de mémoire, ce qui risque de souvent arriver, puisque nous devons nous attendre à des éventuelles pannes.
L’efficacité de cette méthode dépend aussi de la fonction de hachage choisi. Si elle est bien choisie, ceci créera des instances équilibrées. C’est très commun pour les gens d’utiliser des fonctions de hachage comme ‘MD5’ ou ‘SHA1’.
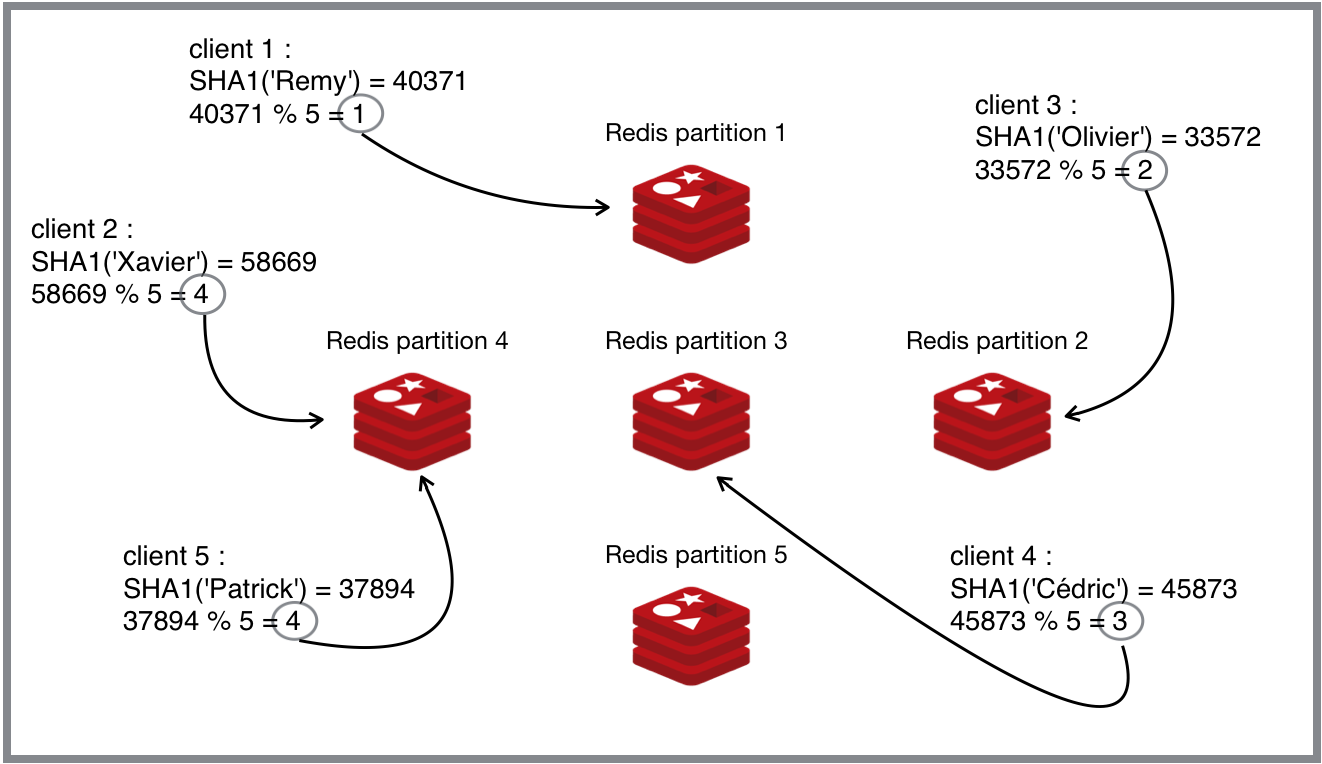
Consistent Hashing
Le principal inconvénient des deux méthodes de partitionnement que nous avons vues précédemment est que l’ajout ou la suppression de noeuds peut avoir un impact négatif sur la distribution des clés, ou provoquer des problèmes de mémoire pour le partitionnement par hachage.
Et c’est dans ce contexte qu’intervient le hachage cohérent (aussi connu sous le nom de hachage en anneau) avec une nouvelle technique de distribution de clés, qui affectera seulement une petite portion des données quand la taille de la liste des instances est modifiée (seulement K/n des clés sont réaffectés, où K représente le nombre total de clés et n le nombre total de serveurs).
Par exemple, dans un cluster de 30 clés et 3 serveurs, le rajout d’un quatrième serveur va réaffecter seulement 10 clés.
La technique consiste à créer plusieurs points, avec une fonction de hachage comme ‘MD5’ ou ‘SHA1’, dans un cercle pour chaque clé et serveur de Redis. Le serveur le plus approprié pour une clé est celui qui est le plus proche de celle-ci dans le cercle.
Prenons cet exemple, avec trois serveurs redis et quatre clés à stocker avec un point par serveur.
Supposons que notre fonction de hachage (MD5) nous retourne ces résultats :
MD5("serveur-1") = 3
MD5("serveur-2") = 7
MD5("serveur-3") = 11
MD5("clé-1") = 3
MD5("clé-2") = 4
MD5("clé-3") = 8
MD5("clé-4") = 12
Le diagramme suivant nous montre le cercle obtenu :
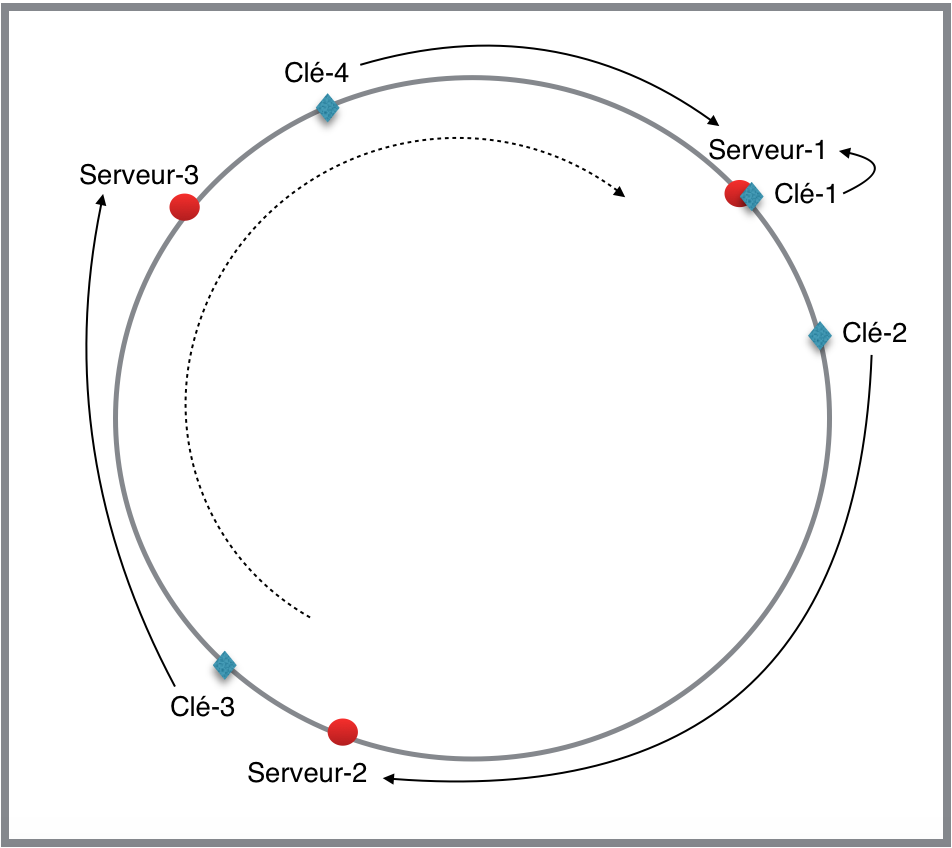
Dans cet exemple, la réaffectation se passe comme suit :
- La clé-1 sera réaffectée au serveur-1 : ils ont la même valeur de 3
-
La clé-2 sera réaffectée au serveur-2 : c’est le prochain serveur qui a une valeur égale ou supérieure à 4
-
La clé-3 sera réaffectée au serveur-3 : c’est le prochain serveur qui a une valeur égale ou supérieure à 8
-
La clé-4 sera réaffectée au serveur-1 : il n’y a pas de serveur qui ait une valeur égale ou supérieure à 12, donc la clé-4 sera affectée au premier serveur
Dans la vie réelle, il est recommandé d’utiliser plusieurs points par serveur, ce qui facilite la distribution des clés et garder les serveurs équilibrés.
Pour conclure
Le “range partitioning” marche très bien et est actuellement utilisé en production, mais vu les problèmes correspondant à l’équilibre des clés entre les instances et les tables de schémas, celui-ci reste moins efficace que les autres solutions alternatives.
Le “consistent haching” est, quant à lui, le partionnement le plus efficace et le plus utilisé avec Redis, mais actuellement il n’est supporté que par quelques clients de Redis.
© SOAT
Toute reproduction interdite sans autorisation de la société SOAT