
Automatiser l’installation de son poste de dév avec Puppet
A chaque nouvelle mission, à chaque changement de poste, on doit installer le projet sur lequel on sera amené à travailler, ainsi que tous les outils nécessaires. En général, on suit toute une procédure (plus ou moins complète) présente sur un wiki ou dans un document. Et au bout d’un moment, on y arrive… à force de chercher sur internet, de demander à droite à gauche les informations manquantes ou de regarder dans les différents fichiers du projet. Plus tard, on se rend parfois compte qu’on a oublié tel ou tel sous-sous-sous-point de la documentation. Ce qui vous fait perdre du temps et qui vous fait lâcher un “Rhaa ! C’est quoi cette doc ?!” rageur.
Et si on automatisait tout cela ? Et si la doc d’installation ne contenait que cette phrase :
“Récupérez tel script, exécutez-le et codez.”
Je vous propose de rendre ça un peu moins utopique avec Puppet, un outil qui permet notamment de gérer la configuration de machines.
Introduction à Puppet
Principe général
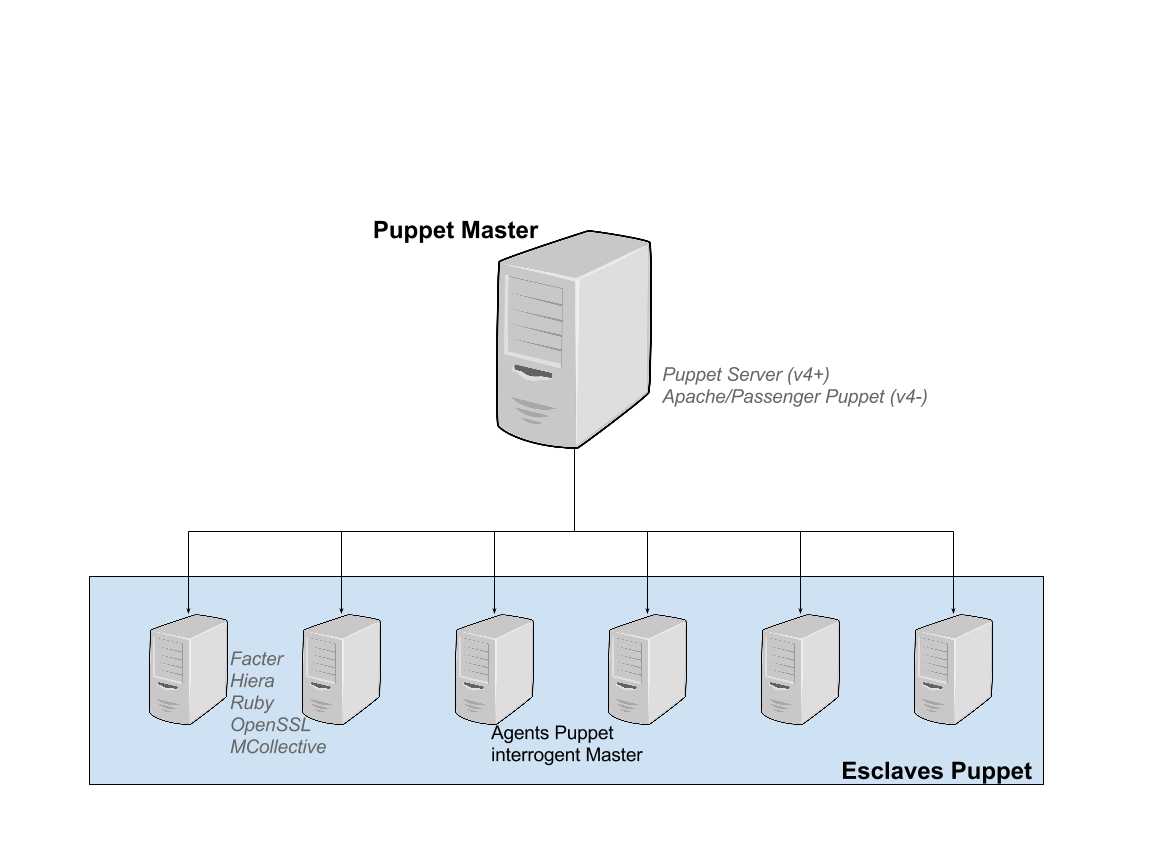
Puppet est un outil de gestion de configuration d’un parc de machines. En général, on l’applique en mode client/serveur : les clients ont un agent Puppet qui vérifie régulièrement auprès du serveur (Puppet Master) s’il y a une nouvelle configuration à appliquer. Si oui, celui-ci répond avec une nouvelle description de la configuration que devrait avoir le client. Car, avec Puppet, on décrit l’état dans lequel doit être telle ou telle catégorie de clients (on ne configure donc pas les clients de manière procédurale, mais de manière descriptive).
PuppetLabs, l’entreprise développant Puppet, ne le faisant pas gratuitement pour vos beaux yeux (on a essayé), distribue Puppet sous forme de licence duale : une version libre, gratuite, mais limitée (Open Source Puppet) et une autre avec des fonctionnalités supplémentaires (des outils supplémentaires de gestion de la configuration, des outils pour vérifier que tout se passe bien, ou pas, etc.). Cette dernière version s’appelle Puppet Enterprise. On se contentera ici de la version libre.
Pourquoi utiliser Puppet ?
Dans notre cas, nous pourrions très bien utiliser des scripts shell qui installeront plus ou moins bien les logiciels dont nous aurons besoin ou des machines virtuelles entièrement configurées. Néanmoins, Puppet permet de vérifier nativement la configuration actuelle et d’appliquer la nouvelle configuration seulement si elle est utile (d’où un certain gain de temps lors de l’exécution).
Nous allons également exploiter la possibilité d’utiliser Puppet, non pas en mode client/serveur, mais en mode client tout seul.
Termes et concepts
Maintenant que le contexte est en place, je vais vous expliquer quelques gros mots rencontrés ici ou là dans la documentation, histoire de vous mettre à l’aise lorsque vous la lirez. Néanmoins, si vous souhaitez passer tout de suite à la pratique, allez directement à la deuxième partie et revenez de temps en temps ici quand vous ne comprenez pas certains termes.
Je vous donnerai ici 2-3 exemples pour que vous puissiez tripoter un peu le bestiau (sur Windows, il faudra lancer la console Puppet en tant qu’administrateur). Pour cela, il faut télécharger Puppet (Linux, Windows ou Mac. D’autres versions sont téléchargeables).
Dernier point : dans cette partie, les exemples fonctionnent tels quel sous Linux, car j’ai voulu vous épargner, dans un premier temps, les subtilités de Windows (que vous verrez dans la seconde partie). Néanmoins, en mettant les chemins entre guillemets et en séparant les noms des répertoires avec des “\”, vous devriez pouvoir les exécuter sur Windows (ex: “c:\\temp\\toto.txt“).
Les manifestes
Au commencement était le manifeste. C’est le fichier de configuration de base, celui dans lequel vous décrirez la configuration que vous voudrez pour le client. Si $PUPPET_ROOT est le répertoire de base dans lequel vous mettrez votre code, on aura tendance à mettre le manifeste principal (habituellement appelé site.pp) dans $PUPPET_ROOT/manifests/. Cela est surtout vrai pour une configuration client/serveur, mais quand vous exécuterez Puppet en client seul, vous pourrez le mettre où vous le voudrez.
Pratiquons. Dans votre répertoire $PUPPET_ROOT/manifests/, mettez un fichier site.pp qui aura pour contenu :
file { '/tmp/toto_de_puppet.txt':
ensure => present,
}
On dit dans ce fichier qu’on va utiliser la ressource “file” pour s’assurer que le fichier /tmp/toto_de_puppet.txt existe. Si ce n’est pas le cas, Puppet va le créer.
Et donc si on lance la commande (dans tous nos exemples, on suppose que vous êtes dans $PUPPET_ROOT) :
puppet apply manifests/site.pp
vous verrez que, Ô miracle, le fichier /tmp/toto_de_puppet.txt a été créé. Si vous relancez Puppet, vous verrez qu’il ne fera rien parce que ce fichier est déjà présent (tiens, une fonctionnalité qu’on n’a pas besoin de coder).
Les modules
Dans ce site.pp, vous mettrez toute la configuration de votre poste. Mais comme dans n’importe quel language, si vous mettez tout le code dans la méthode/fonction principale, ça risque d’être un beau fouillis. Alors, PuppetLabs créa les modules pour Puppet.
Les modules, c’est là que vous factoriserez votre code. C’est l’équivalent des paquetages en Java. Puppet organise les modules d’une certaine manière qu’il faut respecter (il faut mettre au minimum le répertoire manifests/). A noter qu’il y a quelques différences dans l’arborescence, selon que vous utilisez Puppet 3 ou Puppet 4. Dans Puppet 3, vous aurez cette arborescence, contenue dans le répertoire $PUPPET_ROOT/modules/ :
<NOM DU MODULE>/
manifests/files/(pour les fichiers statiques)templates/(pour les fichiers paramétrables avec ERB, voire EPP pour Puppet 4+)lib/(pour les fonctions, les “facts” et les “resources” personnalisés)facts.d/tests/(pour montrer comment utiliser votre module)spec/(qui sert pour les tests avec RSpec)
En Puppet 4, vous aurez la même structure, mais le répertoire tests/ est renommé en examples/.
Il faut savoir qu’il existe des modules déjà écrits par d’autres, disponibles dans le PuppetForge. Il y en a pour httpd, tomcat, java, etc. Ils s’installent avec la commande :
puppet module install <NOM_DU_MODULE>
Comme tout le monde peut y mettre son module, il existe un système de classification des modules (Puppet Supported et Puppet Approved et les autres).
Les classes
Admettons que vous vouliez créer le code pour installer Eclipse sur votre poste. Pour cela, il faudra créer une classe dans votre module eclipse. Une classe est un bloc de code Puppet que vous mettez dans les modules et qui ne sera utilisé que si on la déclare. Elle utilisera alors des ressources qui décrivent un aspect d’un système (fichier, service, etc.) pour configurer par exemple tout ce dont une application a besoin. Les classes doivent être mises dans le répertoire manifests/ de votre module. Ainsi, pour votre eclipse, il vous faudra créer un fichier init.pp dans $PUPPET_ROOT/modules/eclipse/manifests/. Ce fichier init.pp aura comme contenu (du moins au début) :
class eclipse {
notify { "Installation d'Eclipse en cours...":}
}
Dans ce fichier, vous voyez qu’on a utilisé le mot-clé class. Cette fois, c’est pour définir la ressource et non pour l’utiliser. Vous noterez également la présence de la commande notify, mise ici à titre d’exemple, qui est une ressource de base dans Puppet, qui, exceptionnellement, ne décrit pas vraiment l’état dans lequel doit être la ressource, mais décrit ce qui doit être fait. Dans votre précédent site.pp, vous pourrez utiliser ce module en y ajoutant :
class {'eclipse': }
Pour vérifier que le fichier est correct syntaxiquement, vous avez la commande suivante :
puppet parser validate <MANIFESTE>
Puis pour vérifier que votre code fonctionne bien :
puppet apply site.pp --modulepath=modules/
Ce fichier init.pp est bien pratique, mais comment faire si vous voulez plusieurs classes dans ce module ? En fait, vous pouvez nommer les classes comme vous voulez, mais init.pp est le nom du fichier pour la classe par défaut du module. Donc vous pouvez également vous créer un fichier <NOM_DE_LA_CLASSE>.pp, par exemple mars.pp qui installera Eclipse Mars. Néanmoins, tout cela implique des différences dans la façon de les déclarer ou de les utiliser.
Ainsi, si on utilise init.pp, son contenu sera de la forme :
class <NOM_DU_MODULE> { ... }
et dans le site.pp, on l’appellera ainsi (notez la position des accolades et les apostrophes) :
class { '<NOM_DU_MODULE>': }
Par contre, si on utilise un autre nom que init.pp, le contenu du fichier sera de la forme :
class <NOM_DU_MODULE>::<NOM_DE_LA_CLASSE> { ... }
Et on l’utilisera de la manière suivante dans site.pp :
class {'<NOM_DU_MODULE>::<NOM_DE_LA_CLASSE>':}
Concrètement, dans $PUPPET_ROOT/modules/eclipse/manifests/mars.pp :
class eclipse::mars {
notify{"Installation de Eclipse Mars en cours...":}
}
et dans site.pp :
class { 'eclipse::mars': }
On peut généraliser le nommage. Par exemple, dans le répertoire manifests/ de votre module eclipse, vous avez un répertoire linux/ qui contient une classe params présente dans le fichier params.pp. Dans ce fichier, vous aurez :
class <NOM_DU_MODULE>::...sous-répertoires dans manifests/...::<NOM_DE_LA_CLASSE>{}
concrètement :
class eclipse::linux::params{
notify {"On utilise les paramètres pour Linux": }
}
Et pour la déclarer, même schéma :
class {'eclipse::linux::params':}
Cette façon de faire permet d’ailleurs d’avoir une sorte d'”interface” dans le répertoire manifests/ et d’avoir des implémentations dans les sous-répertoires.
A noter que chaque classe est un singleton (c’est d’ailleurs pour cela que, si le DSL utilisé par Puppet ressemble à du Ruby, ça n’en est pas).
Dernier point : vous aurez remarqué que, selon que vous définissiez ou utilisiez une classe, on n’utilise pas le mot-clé class de la même façon. Quand on définit, on utilise le mot-clé class, alors que quand on utilise une classe, on la déclare avec la pseudo-ressource class (de la même façon qu’on déclarerait une ressource file).
Utilisation des classes avec des paramètres
Bon, c’est mignon les classes sans paramètres, mais ne peut-on vraiment pas les paramétrer ? Ben si !
Déclaration type ressource
En Puppet, il y a différentes façons de paramétrer une classe. La déclaration d’une classe comme s’il s’agissait d’une ressource ne permet pas de la déclarer plusieurs fois. On déclare une classe de cette façon avec la pseudo-ressource class que nous avons utilisée jusqu’à présent. Ainsi, si nous souhaitons que notre classe soit paramétrée, nous la définirons ainsi (ici, donc, une nouvelle classe params dans le sous-répertoire windows/) :
class eclipse::windows::params($repertoire_install, $version='mars') {
notify { "On installe la version $version dans le répertoire $répertoire_install": }
}
class { 'eclipse::windows::params':
repertoire_install => '/home/grosminet', #<PARAMETRE> => <VALEUR>,
}
A noter que dans Puppet 4, on peut aussi préciser le type du paramètre histoire d’ajouter la vérification des paramètres à la compilation.
Déclaration type inclusion
Une autre façon d’utiliser les classes est de les “inclure” au lieu de les déclarer comme des ressources. Contrairement à précédemment, cela permet de les utiliser plus d’une fois. Par exemple, dans le site.pp, vous aurez un message d’erreur si vous mettez :
class { 'eclipse::linux::params': }
class { 'eclipse::linux::params': }
Par contre, vous n’aurez rien si vous écrivez :
include eclipse::linux::params
include eclipse::linux::params
La différence avec l’inclusion type ressource, c’est qu’on ne pourra pas donner de paramètres comme précédemment. Pour être exact, quel que soit votre façon de déclarer (type inclusion ou type ressource), le paramétrage se fait ainsi :
- Récupération d’une valeur donnée par une ressource externe
- Valeur par défaut
- Erreur
Pour la déclaration type ressource, on prendra d’abord la valeur donnée en paramètre, puis on suivra ces étapes.
Pour l’inclusion, vous avez quatre mots-clé pour préciser la façon que vous voulez utiliser : include (pour utiliser la classe), require (la classe requise doit d’abord être appliquée), contain (sorte de copier/coller) et hiera_include (pour faire appel à une classe récupérée par Hiera, qu’on verra plus loin).
Les ressources
Comme vous avez pu le constater au travers des exemples, Puppet a des ressources prédéfinies. C’est donc avec une grande allégresse que vous en trouverez la liste, fournie. Dans notre cas d’utilisation, les plus utiles sont file, package et exec.
Vous pouvez aussi définir vos propres ressources de deux manières différentes si celles de Puppet ne suffisent pas :
vous définissez votre ressource (avec ou sans paramètres), toujours dans le même répertoire manifests/ de votre module, de la manière suivante :
define maven::settings($path=$title, $trigramme, $uri_bdd='https://localhost:7474') {
notify("settings.xml est dans $path, le trigramme du dév est $trigramme et l'URI de la BDD est $uri_bdd": }
}
et dans le site.pp :
maven::settings {'/home/grosminet/.m2/settings.xml':
trigramme => 'GMI',
}
Chaque ressource est identifiée par son titre et est donc unique. Néanmoins vous pouvez faire de ce titre la valeur d’un des paramètres (comme c’est le cas ci-dessus). On appelle ce paramètre namevar.
L’autre façon est de le faire avec Ruby sur laquelle nous ne nous étendrons pas, car nous ne nous en servirons pas. Sachez au moins qu’il faut définir le type, qui servira un peu comme une interface en Java, ainsi qu’un fournisseur (provider) qui lui implémentera les opérations voulues en fonction du système d’exploitation.
Hiera
Hiera est un outil à part de Puppet mais distribué avec depuis les dernières versions. C’est utile pour définir des données propres à un site. Dans notre cas d’utilisation, on l’utilisera pour définir les données propres au développeur (son trigramme, les informations de connexion à sa base de données, son adresse mail, etc.). Dans le fichier de configuration de Hiera, hiera.yaml (oui, c’est en YAML), on définit hiérarchiquement quelles sont les données à utiliser. Dans cet exemple (il n’y a pas de caractère tabulation dans ce fichier) :
---
:backends:
- yaml
:yaml:
:datadir: /etc/puppet/hieradata
:hierarchy:
- "osfamily/%{osfamily}"
- common
on dit que les données que Hiera doit chercher sont dans /etc/puppet/hieradata et qu’il faut d’abord prendre les données présentes dans le fichier /etc/puppet/hieradata/osfamily/Debian.yaml si le nœud en question a Debian comme famille d’OS (taper la commande facter osfamily pour le savoir sinon). S’il ne trouve pas la donnée, Hiera ira la chercher dans hieradata/common.yaml (on cherche des fichiers yaml, parce que c’est ce qu’on a mis dans backends. Ça aurait très bien pu être du JSON, Puppet ou autre).
Pour utiliser ces données, si une classe a besoin des paramètres définis dans ces fichiers .yaml, il suffit d’un simple include ou class. Comme vu plus haut, le processus de paramétrage va chercher dans hiera.
A noter qu’on peut utiliser les données de Facter, Puppet ou de la ligne de commande.
Si vous voulez tester Hiera avant de l’utiliser avec Puppet, vous avez une ligne de commande pour ça (hiera, tout simplement). Avec l’exemple précédent, on pourrait écrire :
hiera trigramme osfamily=Debian --config=hiera.yaml -d
Si dans hieradata/osfamily/Debian.yaml on a :
---
trigramme: GMI
et dans hieradata/common.yaml on a :
---
trigramme: IAB
la précédente commande affichera “GMI”. Si vous mettez autre chose que osfamily=Debian, vous aurez “IAB”.
Si on a une classe msg ayant ce contenu :
class msg($trigramme) {
notify {"le trigramme est : $trigramme ": }
}
et qu’on a un site.pp ayant ce contenu :
include msg
et qu’on préfixe les trigramme par msg:: dans Debian.yaml et common.yaml et qu’on applique cette commande-là :
puppet apply site.pp --modulepath=modules/ --hiera_config=hiera.yaml
Puppet nous affiche “GMI” si on est sur un OS dont la famille est Debian (Ubuntu par exemple) et “IAB” sinon.
Facter
Facter est un outil, fourni avec Puppet, qui se charge de collecter tout un ensemble de faits sur un nœud, comme l’adresse IP, le type de système d’exploitation, etc. Ces données sont utilisables directement dans Puppet comme de simples variables (essayez donc notify {"$operatingsystem":} dans votre site.pp, $operatingsystem étant une des données récupérées par Facter).
Autre point intéressant de Facter est sa possibilité d’extension. Par exemple, si vous écrivez un module, vous pourrez également ajouter un “fact” à la déjà longue liste donnée par Facter.
Pour afficher la liste de toutes les variables, utilisez la commande facter (et facter <NOM DE LA VARIABLE>, pour vérifier que ladite variable est définie).
Automatiser l’installation du poste
Maintenant que nous avons vu quelques concepts et exemples sur Puppet, nous allons à présent vous donner quelques pistes pour installer votre poste avec Puppet.
Procédure
Préambule
Si ce n’est déjà fait, commencez par installer un agent Puppet (Linux, Windows ou Mac. D’autres versions sont téléchargeables).
Admettons que nous ayions un projet relativement complexe qui nécessite Java, Maven et Eclipse et qui affiche “Hello World!” (oui, c’est du lourd. On sait, ça impressionne). Et on fait ça sous Windows (parce qu’on est souvent sur Windows en mission).
Nous mettrons notre projet dans un répertoire que nous appellerons PUPPET_ROOT. Sachez ensuite, si vous en souhaitez un, qu’il existe un IDE nommé Gepetto, que je n’ai pas testé en profondeur.
Dans ce qui suit, je vous montrerai l’éventail des possibilités qui s’offrent à vous. Il se peut que les solutions vous paraissent trop complexes.
Début
Nous installerons d’abord Java, car sans lui, nous ne ferons rien. Dans le répertoire %PUPPET_ROOT%, nous créerons un fichier manifests\site.pp.
Sur Windows, une fois que vous aurez installé Puppet, vous aurez droit à une invite de commande spéciale Puppet. Il faut l’exécuter en mode Administrateur. Taper ensuite la commande (si vous avez des problèmes de certificats, consultez cette page) :
puppet module install cyberious-windows_java
Ceci installera un module java (les logs indiquent qu’il est installé dans C:\ProgramData\PuppetLabs\puppet\etc\modules\) que vous pourrez utiliser ensuite dans votre site.pp. Pour installer la dernière version de java, il suffira ensuite de mettre ceci dans votre site.pp :
class { 'windows_java': } (on aurait aussi pu mettre "include windows_java")
Entrer la commande suivante :
puppet apply manifests\site.pp --modulepath=C:\ProgramData\PuppetLabs\puppet\etc\modules\
Attendez un peu, et voilà ! java, javac et les autres sont installés dans C:\Program Files (x86)\Java, si vous êtes en 64 bits, et les variables d’environnement %PATH% et %JAVA_HOME% sont initialisées avec les bonnes valeurs.
Sur la page de cyberious-windows_java, on remarque un onglet “Dependencies“. Lors de l’installation du module, vous aurez probablement remarqué que ces dépendances sont automatiquement installées, et ce, de manière transitive. C’est ainsi que vous trouverez dans le répertoire des modules, entre autres les modules puppetlabs-powershell (un “provider” de la ressource de base de exec, c’est-à-dire que exec va pouvoir exécuter du powershell) et badgerious-windows_env (un module pour les variables d’environnement sous Windows). Vous trouverez ces dépendances dans le fichier metadata.json du module (...\modules\windows_java). C’est un fichier qu’il faut fournir si vous publiez votre module sur PuppetForge (oui, car il faut respecter un certain nombre de conventions si vous voulez publier votre module).
En regardant un peu dans les sources du module (plus spécifiquement dans manifests/init.pp), on retrouve les notions de classe et de paramètres décrites plus tôt. C’est d’ailleurs dans la classe windows_java::jdk que l’on voit où sera installée la JDK et dans windows_java::java_home que vous verrez qu’il utilise windows_env pour modifier les variables d’environnement %PATH% et %JAVA_HOME%. Vous y remarquerez que vous pouvez aussi utiliser des structures de contrôle que je n’avais pas mentionnées dans la première partie.
À travers cet exemple, vous comprendrez certainement l’intérêt des modules et de leur partage.
7zip
Avant d’installer les autres outils, nous aurons besoin d’un décompresseur de fichiers. Nous allons donc voir comment installer 7zip (et comment créer des modules).
On va présupposer que le fichier d’installation est sur un répertoire partagé (cas rencontré en mission puisqu’on n’avait pas le droit de télécharger des fichiers .msi d’internet) et que nous avons voulu la version avec un .msi.
Nous allons utiliser la ressource package qui permet d’installer/désinstaller des applications. Cette ressource fait appel à un adaptateur pour faire la liaison entre Puppet et le système d’exploitation sous-jacent. Par exemple selon qu’on est sur Ubuntu ou Gentoo, Puppet utilisera le “provider” adapté à Ubuntu ou à Gentoo et qui utilisera donc les gestionnaires de paquets apt-get ou Portage.
Pour cela, nous allons créer un module pour 7zip et notre %PUPPET_ROOT%\modules\7zip\manifests\init.pp (la classe principale donc) contiendra :
class 7zip {
file { 'c:\puppet\tmp\7z920-x64.msi':
source => 'x:\Applications\7z920-x64.msi',
source_permissions => ignore,
}
package { '7-Zip 9.20 (x64 edition)':
source => 'c:\puppet\tmp\7z920-x64.msi',
provider => 'windows',
ensure => 'present',
}
}
Et si dans votre %PUPPET_ROOT%\manifests\site.pp, vous ajoutez cela :
class { '7zip': }
Et que vous exécutez la commande :
puppet apply manifests\site.pp --modulepath=modules;"%HOMEPATH%"\modules\
vous verrez que 7Zip sera installé.
Si vous aviez mis absent à la place de present dans le paramétrage de package, 7Zip aurait été désinstallé. A noter aussi que le titre de package est celui que connait le gestionnaire de paquets. Sur Windows, vous pouvez le trouver dans le Panneau de Configuration, plus particulièrement dans la partie Ajout/Suppression de programmes. Cette façon de faire fonctionne aussi avec les fichiers .exe auto-extractables.
Nous avons mis la ressource file. Elle n’est pas indispensable, mais elle nous permet de vous montrer comment on peut s’assurer qu’un fichier est présent.
Eclipse
L’installation d’Eclipse est un peu particulière. Vous pouvez certes télécharger Eclipse, trifouiller dans les différents fichiers de configuration, mais c’est compliqué. Le mieux que nous ayons trouvé est de télécharger un Eclipse basique, le configurer entièrement (sans le projet s’entend), de le zipper puis de le mettre quelque part dans un répertoire partagé. Après, il n’y aura plus qu’à le récupérer et le décompresser dans un répertoire voulu.
Nous allons donc créer un fichier %PUPPET_ROOT%\modules\eclipse\manifests\install.pp (on aurait aussi pu l’appeler init.pp) qui contiendra donc :
class eclipse::install($source, $target='c:\\dev\\eclipse\\') {
require 7zip
exec { "7z.exe x -o$target $source":
cwd => 'c:\\Program Files\\7-Zip\\',
creates => "$target",
path => 'c:\\Program Files\\7-Zip\\',
}
}
Et dans site.pp, nous aurions :
class {'eclipse::install':
source => 'x:\\Applications\\eclipse.zip',
target => 'c:\\eclipse\\',
}
Dans la classe install, vous aurez remarqué que nous avons utilisé la ressource exec pour décompresser notre Eclipse de base. Quand on commence à développer avec Puppet, si on est trop habitué au raisonnement procédural, on a tendance à vouloir utiliser systématiquement cette ressource. Il y a cependant des conditions à respecter pour utiliser cette ressource. Notamment la commande exécutée doit être idempotente (si on l’exécute 30 fois, elle donnera toujours la même chose). Pour la rendre idempotente (ou presque), nous avions plusieurs choix, comme englober le exec dans un onlyif ou un unless. Néanmoins, dans un souci de concision, nous avons choisi d’utiliser le paramètre creates : si Puppet détecte le fichier donné dans le creates, il n’exécute pas la commande. Cela évite de décompresser des fichiers, et donc de perdre du temps inutilement. Et le require ? Quand Puppet va exécuter votre site.pp, il va construire un graphe des dépendances pour savoir ce qu’il faut exécuter en premier. Ici, on dit qu’il faut 7zip pour avoir Eclipse.
Maven
A présent que nous avons Java, 7zip et Eclipse d’installés, nous allons installer Maven. Là où Maven est intéressant, c’est qu’il a besoin d’un fichier de configuration adapté à l’utilisateur. Et cela est une bonne excuse pour vous montrer Hiera et comment écrire nos propres “facts”.
Pour Maven, nous allons donc créer une classe (dans un init.pp) qui prendra en paramètre le .zip avec tous les binaires, le répertoire dans lequel il faut l’installer ainsi que le répertoire qui servira de MAVEN_HOME. Pour un début, cette classe se contentera de dézipper le fichier .zip :
class maven ($source, $target='c:\\dev\\maven', $maven_home) {
require 7zip
exec { "7z.exe x -o$target $source":
cwd => 'c:\\Program Files\\7-Zip\\',
creates => "$target",
path => 'c:\\Program Files\\7-Zip\\',
}
}
On utilise à nouveau le require 7zip pour dire que la classe 7zip doit être utilisée avant.
Ensuite, il faut initialiser ou modifier les variables d’environnement %MAVEN_HOME% et %PATH%. Pour cela, on utilise le module windows_env (déjà téléchargé grâce au module windows_java) :
exec {
...
}
windows_env { 'MAVEN_HOME' :
ensure => present,
value => "$maven_home",
mergemode => clobber,
}
windows_env {"PATH=%MAVEN_HOME\\bin": }
Dans le premier cas, on lui dit : “initialise la variable %MAVEN_HOME%. Si elle est déjà présente, remplace-la”. Alors qu’avec %PATH%, il faut lui ajouter %MAVEN_HOME%\bin\ (sinon, on ne démarre plus grand chose). D’où le clobber.
Une fois qu’on a initialisé les variables d’environnement, nous allons personnaliser le settings.xml. Mais pour cela, il faut que le répertoire .m2/ de l’utilisateur soit créé :
windows_env {"PATH...}
file { "C:\\Users\\grosminet\\.m2\\":
ensure => directory,
source_permissions => ignore,
}
Le ensure => directory s’assure que le répertoire est créé (et est bien un répertoire).
En voyant ce répertoire, avec ce chemin en dur, vous vous dites que ça serait pas mal de paramétrer ce chemin. Créons donc un “fact”. Si vous vous souvenez de l’arborescence d’un module de la première partie, il y a un répertoire lib/facter/. C’est là-dedans que nous allons mettre notre script Ruby ultra-complexe que la concurrence nous jalouse. Nous l’appellerons username.rb (vous pouvez l’appelez mongrodoudou.rb si ça vous chante aussi). Et dedans, nous allons juste compléter une lambda qui doit retourner la valeur de notre “fact” ‘username’. Nous avons donc :
Facter.add(:username) do
setcode do
ENV['USERNAME'] # le mot-clé 'return' est implicite en Ruby, donc on ne le met pas
end
end
C’est du lourd… (bon, c’est vrai, ça peut être plus complexe, mais le principe est de faire quelque chose à l’intérieur du setcode)
Et c’est tout.
Maintenant, nous pouvons utiliser la variable $username (qu’on écrira ${::username} pour ne pas la confondre avec une variable locale). Donc on réécrit notre ‘file’ :
windows_env {"PATH...}
file { "C:\\Users\\${::username}\\.m2\\":
ensure => directory,
source_permissions => ignore,
}
En créant ce “fact”, il devient disponible à la fois dans notre code Puppet, mais aussi dans hiera. Ça tombe bien, nous voulons paramétrer notre settings.xml en fonction de l’utilisateur. Et ceci peut se faire avec hiera. Nous allons donc créer un fichier hiera.yaml dans %PUPPET_ROOT% :
---
:backends:
- yaml
:yaml:
:datadir: hieradata
:hierarchy:
- users/%{username}
- common
Dans la partie hierarchy, on dit à hiera de d’abord chercher dans le fichier hieradata/users/.yaml, et s’il ne trouve pas la donnée, de regarder dans hieradata/common.yaml. Comme notre utilisateur s’appelle grosminet, on va créer un fichier hieradata/users/grosminet.yaml qui contiendra :
---
maven::trigramme: GMI
Au cas où, on crée le fichier common.yaml :
---
maven::trigramme: IAB
Le maven:: permet de dire à Puppet que cette donnée sera utilisée dans le module maven.
Quel intérêt d’avoir un fichier .yaml par utilisateur ? Admettons que vous gériez votre code source sur git, toutes les données de l’utilisateur contenues dans ce fichier seront alors dans git. Quand il changera de poste ou quand son poste ne marchera plus, il n’aura pas perdu ses données.
A présent, retournons dans le init.pp du module maven pour y ajouter la configuration du settings.xml :
file { "C:\\Users\\${::username}\\.m2\\settings.xml":
content => template('maven/settings.xml.erb'),
}
On dit ici à Puppet que le settings.xml a un contenu dont le modèle (“template”) est settings.xml.erb. ERB est un moteur de template en Ruby. Les modèles sont mis dans le répertoire template/ dans l’arborescence du module. Dans notre cas, nous avons pris le settings.xml par défaut de Maven, et nous avons juste inséré la ligne suivante dans le fichier %REPERTOIRE_MODULE_MAVEN%\templates\settings.xml.erb :
<trigramme><%=@trigramme %></trigramme>
Comme la variable trigramme a été ajoutée dans hiera et qu’il est donc à présent disponible pour Puppet, celui-ci va demander à ERB de remplacer @trigramme par la valeur contenue dans le fichier grosminet.yaml.
template() est une des fonctions disponibles de base. Vous pouvez également en ajouter (ou utiliser celles disponibles dans PuppetForge, comme stdlib).
Comment tester ?
A la vue de tout ça, vous vous demandez probablement comment nous pouvons tester tout cela. Effectivement, en développant sur notre poste, tout semble fonctionner, puis, lorsqu’on exécute le script chez le collègue, plus rien ne marche (parce que vous avez oublié les require ou parce que les répertoires sont déjà créés, ou parce que vous avez mis des noms de fichiers en dur dans les classes par exemple).
Tests de base
Tout d’abord, rappelons que vous avez la commande suivante pour valider la syntaxe d’un manifeste :
puppet parser validate
Ensuite, pour valider les conventions d’écriture de Puppet, vous avez puppet lint :
puppet-lint
Tests unitaires
Lorsque vos manifestes commencent à être un peu complexes (prise en charge de multiples cas, variables dont les valeurs sont connues à l’exécution, etc.), vous pouvez utiliser rspec-puppet. C’est basé sur RSpec (outil servant à faire du BDD avec Ruby).
Tests avec Vagrant
Vous pouvez tester vos manifestes sur des machines virtuelles que vous pouvez créer/démarrer/éteindre facilement avec Vagrant.
Vagrant permet de gérer des machines virtuelles, mais on peut lui dire d’appliquer tel script ou tel manifeste Puppet au démarrage de la VM via le “provisioning“. Une simple modification dans le Vagrantfile permet de se lancer rapidement dans l’utilisation croisée de Vagrant et Puppet (à condition que la box gérée par Vagrant ait Puppet) :
config.vm.provision "puppet"
Cela exécutera automatiquera le manifeste /vagrant/manifests/default.pp. Bien sûr, vous pouvez personnaliser un peu plus. Plus d’informations ici.
Aller plus loin
Script d’installation
Une fois que vous avez votre configuration codée avec Puppet, vous pouvez fignoler en écrivant un script (allez ! on vous le fait en batch ! Il faut l’exécuter en Administrateur) qui copiera le fichier d’installation de Puppet et qui lancera son installation. Ça pourrait ressembler à ça (pour un début) :
@echo off
setlocal
dir <répertoire où se trouve l’installeur de Puppet(REP_SRC)>\puppet-x.x.x.msi
if errorlevel 1 (
copy REP_SRC\puppet-x.x.x.msi REP_DEST\puppet-x.x.x.msi
msiexec /i REP_DEST\puppet-x.x.x.msi
)
cd <répertoire où se trouvent les sources Puppet>
cmd /C "C:\Program Files\Puppet Labs\Puppet\bin\environment.bat" && "c:\Program Files\Puppet Labs\Puppet\bin\puppet" "apply" "site.pp" "--modulepath=modules;c:\ProgramData\PuppetLabs\puppet\etc\modules" "--hiera_config=hiera.yaml"
endlocal
Partager
Pour partager ces sources, vous pouvez utiliser les sous-modules dans Git.
Alternativement, vous pouvez aussi, si votre configuration a du succès, utiliser l’architecture client/serveur classique de Puppet. DigitalOcean avait fait un article intéressant pour mettre en place l’architecture client/serveur si des fois la documentation Puppet ne suffisait pas. Attention néanmoins car les esclaves (les postes de dév donc) se mettront régulièrement à jour. Même si le développeur ne veut pas parce qu’il est en train de développer quelque chose qui modifiera la configuration de son poste (changement de version de java par exemple). Vous avez la possibilité, dans la configuration des agents Puppet de désactiver la mise à jour automatique. Auquel cas, le développeur devra exécuter la commande puppet agent --test pour mettre à jour son poste quand il sera prêt (d’autres façons semblent possibles cependant).
Conclusion
Je vous ai donc montré plusieurs concepts et exemples qui, je l’espère, vous ont bien familiarisés avec Puppet, au point qu’ils vous permettront d’aller plus loin. Puppet n’a pas été spécialement conçu pour installer des postes de développement mais, en en détournant l’usage, on peut faire des choses intéressantes avec.
Prochaine étape : configurer un parc entier de machines !
P.S. : Les sources sont ici.