
Liquibase et le versioning de base de données

 De nos jours, il est relativement fréquent d’utiliser une base de données au sein de nos applications. Toutefois, au sein des développeurs, trop peu de monde connait le principe du versioning de base de données et surtout la bonne manière de s’en servir. De mon côté, la première fois que j’ai entendu parler du problème, on m’avait apporté une solution toute prête : “Dbmaintain”.
De nos jours, il est relativement fréquent d’utiliser une base de données au sein de nos applications. Toutefois, au sein des développeurs, trop peu de monde connait le principe du versioning de base de données et surtout la bonne manière de s’en servir. De mon côté, la première fois que j’ai entendu parler du problème, on m’avait apporté une solution toute prête : “Dbmaintain”.
Aujourd’hui, de nombreuses solutions existent avec chacune leurs avantages et leurs inconvénients. De mon côté, je me suis arrêté sur Liquibase car je considère qu’il s’agit d’une bonne solution avec de nombreuses fonctionnalités que l’on ne retrouve pas forcément chez les concurrents.
Pourquoi versionner sa base de données ?
Pour un développeur, versionner son code semble quelque chose d’aujourd’hui naturel. Mais est-ce que tous les développeurs sont sensibilisés au versioning de base de données ?
Le versionning de base de données n’est pas un principe nouveau. En effet, l’article Evolutionary Database Design de Martin Fowler, sorti en 2003, pose les premières bases de cette technique. A l’époque, voici le constat qu’il faisait :
- Le développent d’une application par une conception Waterfall est mauvaise et rend difficile une modification de la base
- La base de données se doit d’évoluer en même temps que le code afin d’avoir une application évolutive
- De la même manière que l’on teste le code, il est important de tester la base de données
A partir de ce constat, une solution afin d’appliquer facilement des modifications sur les bases de données devient nécessaire. Afin que le processus soit correct, un ensemble de préconisations apparaît. Ainsi, pour que le processus se passe correctement, il faut réunir les éléments suivants :
- Au sein du projet, chaque développeur doit posséder sa propre instance de base de données
- Au sein du code, la couche d’accès à la base de données se doit d’être séparée du reste du code
- La base de données doit être testée sur une machine d’intégration continue
Finalement, en utilisant du versioning de base de données, vous allez ainsi rendre votre application beaucoup plus agile. L’utilisation de ce type de solution vous permettra de retirer les bénéfices suivants :
- Tester facilement l’état de la base par rapport à l’état du code
- Intégrer ces tests dans un processus d’intégration continue
- Suivre facilement l’état de la base et faciliter le refactoring
- Améliorer le travail en équipe car les modifications sont visibles et applicables facilement par tous
- Faciliter Les mises en production puisqu’il n’est plus utile d’exécuter manuellement une suite d’instruction SQL
Les solutions existantes
Petit à petit, des outils sont apparus comme Liquibase, Flyway ou DBMaintain, afin d’apporter des solutions au versioning des bases de données. Ceux-ci possèdent des caractéristiques communes comme :
- Destruction et construction d’un schéma
- Identification de la version du schéma
- Connaissance des changements appliqués par le passé
- Vérification de l’intégration des scripts exécutés
- Impossibilité d’appliquer des changements ayant déjà été exécutés
A partir de cela, il est alors possible de recréer un état de la base de données en accord avec le code de manière répétable. Grâce à ces fonctionnalités, on aperçoit déjà le fait de pouvoir inclure des tests unitaires sur la base de données.
Afin d’avoir une meilleure vision des solutions existantes, voici un tableau comparatif entre celles disponibles à ce jour et les fonctionnalités dont chacune de ces solutions disposent :
| Solutions | Clean | Upgrade | Rollback | Checksum | Compare |
|---|---|---|---|---|---|
| Flyway | Yes | Yes | No | Yes | No |
| Liquibase | Yes | Yes | Yes | Yes | Yes |
| DbMaintain | Yes | Yes | No | No | No |
Toutefois, afin d’avoir un meilleur comparatif, rien de tel que de tester les différentes solutions et les avantages inconvénients que chacune offre !
Et Liquibase, comment ça fonctionne ?
Et bien Liquibase fonctionne sur des fichiers XML appelé changeLogs. Ces fichiers changeLogs contiennent un ou plusieurs changeSets, ce qui correspond à une opération qui sera tracée. Pour mieux comprendre de quoi il est question, nous allons voir un peu à quoi ressemble un changeLog et chercher à comprendre comment ceux-ci fonctionnent.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<databaseChangeLog logicalFilePath="db.changelog-2015-10-09-add-creation-date.xml"
xmlns="https://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://www.liquibase.org/xml/ns/dbchangelog https://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.4.xsd">
<property name="now" value="sysdate" dbms="oracle"/>
<property name="now" value="now()" dbms="postgresql"/>
<changeSet id="0001" author="patouche">
<comment>Add column date_created on table post.</comment>
<addColumn tableName="post">
<column name="date_created" type="DATE" value="${now}"/>
</addColumn>
</changeSet>
<changeSet id="0002" author="patouche">
<comment>Add constraint not null on column date_created for table post.</comment>
<addNotNullConstraint tableName="post" columnName="date_created"/>
</changeSet>
</databaseChangeLog>
Comme vous l’avez peut-être compris, chaque changeSet correspond à une opération sur la base de données. Lors d’une mise à jour de la celle-ci, tous les changeSets seront alors exécutés dans l’ordre où ils ont été définis dans le fichier changelog. Ces changeSets seront alors appliqués de façon atomique sur la base.
Ainsi, si un changeSet ne fonctionne pas, tous les précédents auront déjà été appliqués et il ne vous restera alors plus qu’à corriger le changeSet afin de relancer la migration de votre base. Cela permettra donc d’appliquer tous les changeSets restant !
A ce moment-là, il est logique de se demander comment Liquibase fait pour se souvenir de tous les changeSets déjà exécutés. En fait, pour que Liquibase puisse fonctionner, à son premier lancement, il va automatiquement créer 2 tables sur votre schéma :
DATABASECHANGELOGDATABASECHANGELOGLOCK
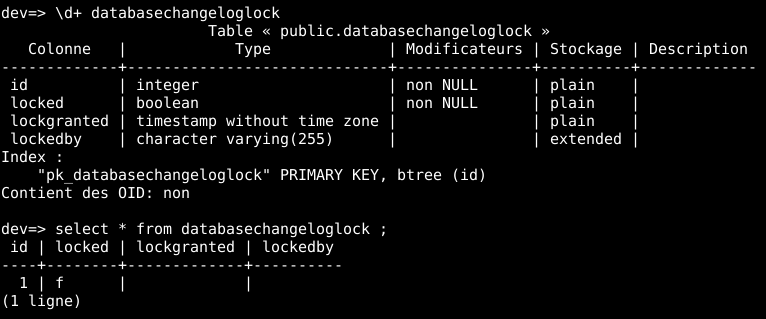
La table DATABASECHANGELOGLOCK va permettre à Liquibase d’assurer que personne ne fait une mise à jour concurrente sur la base en même temps que vous. Voici, par exemple, la description et le contenu de cette table :
La table DATABASECHANGELOG est par contre beaucoup plus intéressante ! Cette table va servir à indiquer à Liquibase quels changeSets ont déjà été exécutés. Voici un exemple de ce à quoi peut ressembler cette table :
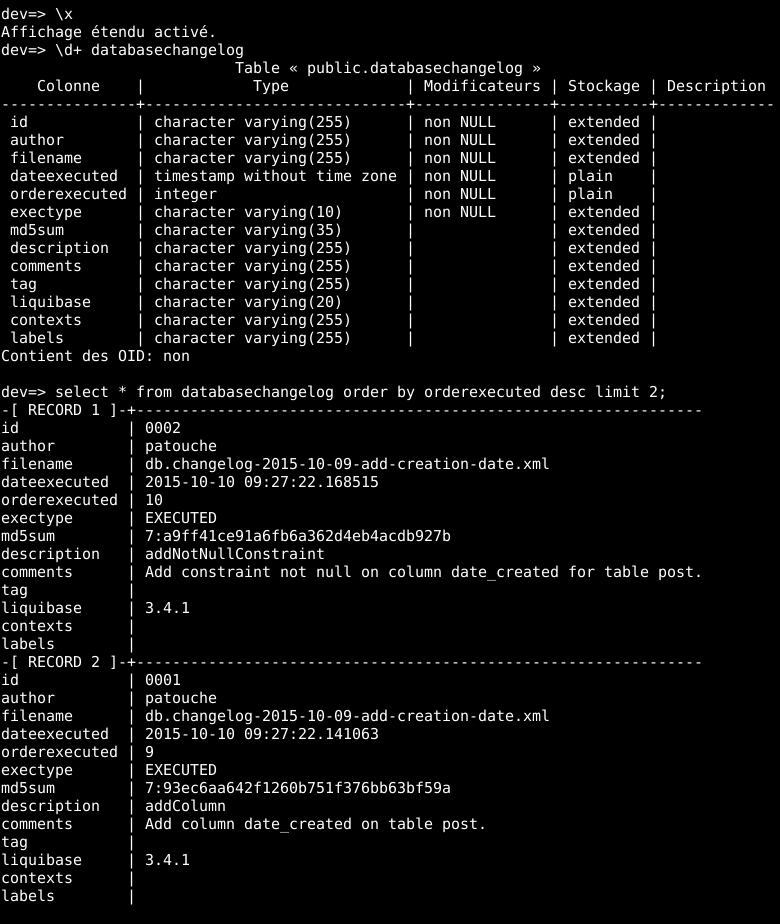
Comme vous pouvez le constater, pour un changeSets exécuté, Liquibase enregistre pas mal de choses ! En effet, on retrouve l’ordre d’exécution du changeSet par rapport aux autres, la date d’exécution, le nom de fichier où se situe le changeSet, le checksum du changeSet et même … la version de Liquibase avec laquelle le changeSet a été exécuté !
Le checksum est, comme l’indique son nom, une manière de valider que le changeSet n’a pas été modifié entre temps. En effet, une fois partagé, un changeSet ne doit plus jamais être modifié. En effet, si, après avoir appliqué votre changeSet, vous décidez de le modifier, Liquibase ne sera pas d’accord !
Par ailleurs, difficile de parler de changeSet sans évoquer la balise rollback. En effet, dans chaque changeSet, il est possible de définir une balise rollback. Cette balise, en conjonction avec la table DATABASECHANGELOG, vous permettra de revenir à une version précédente de l’application. Enfin, l’avantage de la notation XML permet d’avoir des rollback automatiques. C’est à dire qu’il n’y a nul besoin de définir la balise rollback lorsqu’un changeSet ne contient qu’un addColumn, puisque l’opération inverse est naturellement dropColumn !
Toutefois, il existe des modifications que l’on qualifie de destructives. Par exemple, le tag dropColumn de Liquibase est une modification destructive puisqu’il n’est pas possible de faire un addColumn en récupérant toutes les données. Dans ces cas-là, la balise rollback ne peut pas être automatique. Il sera alors de la responsabilité des développeurs d’ajouter le tag rollback au sein du changeSet afin de pouvoir revenir à une précédente version du code facilement.
Par ailleurs, comme vous avez pu le constater, il est très facile de concevoir des fichiers changeLogs portables d’une base de données à l’autre en définissant des propriétés ou tout simplement en utilisant le tag preConditions mis à disposition par Liquibase.
Afin d’éviter toute erreur, voici les 2 points essentiels à retenir :
- Une balise par changeSet (en plus de preConditions et de comment) afin d’avoir des modifications unitaires (et la possibilité de l’auto rollback)
- Ne jamais modifier un changeSet par solution de facilité une fois qu’il a été exécuté
- Bien penser à définir la balise rollback pour les modifications destructives.
Ici, nous n’avons évoqué que quelques types de modifications. Pour plus de détails sur l’intégralité des tags disponibles avec Liquibase, vous pouvez aller consulter la documentation en ligne.
Mise en place et utilisation de Liquibase
Dans cette partie, je ne présenterai que l’intégration avec Maven. En effet, si l’on souhaite utiliser Liquibase au sein de son application, il me semble préférable d’utiliser en ligne de commande la même version que celle utilisée au sein de son application.
Mise en place
Dans un premier temps, je vais partir d’une application simpliste existante avec tout plein de défaut (dont – entre autres – celui de ne pas versionner son schéma !). Cette application permet juste de saisir un message et d’y ajouter un commentaire (ce qui change très légèrement de la TODO list mais pas tant que ça). Dans celle-ci, j’ai décidé d’utiliser une base de données PostgreSQL. Voici un peu à quoi elle ressemble :

Pour rajouter correctement le versioning de base de données sur l’application, il convient de créer un nouveau module Maven séparé de la couche Repository (ou DAO). Pour cela, juste à côté du module où vous avez créé vos entités, il suffit d’utiliser la commande suivante :
mvn archetype:generate -DgroupId=fr.patouche.soat -DartifactId=sample-liquibase -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
Ensuite, après avoir généré un squelette de pom.xml, il suffit juste d’ajouter la bonne configuration afin d’avoir une intégration simple avec Liquibase sur Maven. A la fin de cette opération, voici enfin à quoi ressemble le pom.xml de l’intégration de l’intégration Liquibase avec Maven :
<?xml version="1.0"?>
<project xsi:schemaLocation="https://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"
xmlns="https://maven.apache.org/POM/4.0.0" xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance">
<!-- Parent, Artifact, ... -->
<dependencies>
<dependency>
<groupId>org.liquibase</groupId>
<artifactId>liquibase-core</artifactId>
</dependency>
<dependency>
<groupId>postgresql</groupId>
<artifactId>postgresql</artifactId>
</dependency>
</dependencies>
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.liquibase</groupId>
<artifactId>liquibase-maven-plugin</artifactId>
<configuration>
<promptOnNonLocalDatabase>true</promptOnNonLocalDatabase>
<changeLogFile>${project.build.directory}/classes/changelog/db.changelog-master.xml</changeLogFile>
<propertyFile>${project.build.directory}/classes/user/db-${user.name}.properties</propertyFile>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
<profiles>
<profile>
<id>migration-developer</id>
<activation>
<file>
<exists>${user.home}/db-${user.name}.properties</exists>
</file>
</activation>
<build>
<plugins>
<plugin>
<groupId>org.liquibase</groupId>
<artifactId>liquibase-maven-plugin</artifactId>
<configuration>
<propertyFile>${user.home}/db-${user.name}.properties</propertyFile>
</configuration>
</plugin>
</plugins>
</build>
</profile>
</profiles>
</project>
En effet, pour avoir une intégration facile avec Maven, un dossier user a été créé dans le src/main/resources avec les fichiers suivants :
src/main/resources/user/db-username.propertiessrc/main/resource/user/db-patouche.properties
Toutefois, on est bien d’accord que partager ses accès à la base de données sur le repository git n’est pas totalement une bonne pratique. Afin de palier cela, j’ai ajouté un profil qui s’activera automatiquement si le développeur a déposé un fichier db-${user.name}.properties dans son répertoire home.
De ce fait, avec la base de données précédemment créée, il est alors facile de générer un fichier changeLog de départ pour (re)partir sur de bonnes bases. Voici la commande qu’il faudra alors utiliser :
mvn clean resources:resources liquibase:generateChangeLog
A partir du résultat de la commande précédente, il est alors possible de créer un fichier changeLog de départ. Ce fichier servira ensuite pour lister toutes les évolutions sur la base.
Arborescence des changeLogs
Et oui, je parle bien de plusieurs fichiers changeLogs car, en réalité, il ne va pas y avoir qu’un fichier changeLog ! En effet, il vous faudra créer un fichier que l’on appelle généralement le master changeLog, qui agrégera tous vos fichiers changeLogs grâce à la balise include.
Ainsi, pour bien comprendre comment sont organisés vos changeLogs, vous pouvez faire un tree sur le dossier src/main/resources afin de visualiser l’arborescence de ceux-ci. Voyons deux manières de gérer les changeLogs au sein de votre application.
Overkill changeLogs
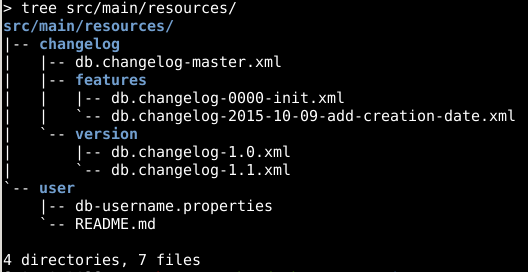
Dans ce cas, le master changeLog fera juste l’inclusion de tous les changeLogs de version, jusqu’à la dernière version. Chaque changeLogs de version fera alors l’inclusion des différentes features de la version. Ci-dessous, vous retrouverez le master changeLog de cette conception :
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<databaseChangeLog logicalFilePath="db.changelog-master.xml" xmlns="https://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://www.liquibase.org/xml/ns/dbchangelog https://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.4.xsd">
<include file="versions/db.changelog.version-1.0.xml" relativeToChangelogFile="true"/>
<include file="versions/db.changelog.version-1.1.xml" relativeToChangelogFile="true"/>
</databaseChangeLog>
Cela semble en effet un peu “compliqué”. Si cela ne vous convient pas de gérer vos changelogs par version, vous pouvez tout à fait adopter une autre stratégie en utilisant la balise includeAll de Liquibase dans votre master changeLogs.
Overkill includeAll
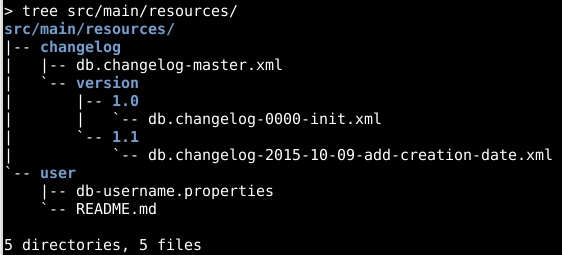
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<databaseChangeLog logicalFilePath="db.changelog-master.xml" xmlns="https://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://www.liquibase.org/xml/ns/dbchangelog https://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.4.xsd">
<includeAll path="changelog/versions/1.0/" />
<includeAll path="changelog/versions/1.1/" />
</databaseChangeLog>
Les includeAll reviennent définir les changeLogs à la mode Flyway. Grâce à cela, Liquibase va rechercher dans le dossier tous les changeLogs à exécuter puis les exécuter un à un. Toutefois, cette méthode est à utiliser avec beaucoup de prudence car Liquibase va exécuter les fichiers changeLogs par ordre alphabétique. Au sein de l’équipe, il convient donc de définir au préalable une convention de nommage des fichiers changeLogs afin d’éviter d’avoir des fichiers chargé dans un ordre erratique…
Dans tous les cas, cela relève d’un choix de conception de votre application et, bien qu’il soit possible à tout moment de changer de stratégie grâce au master changeLog, cela peut être difficile de revenir en arrière, car il s’agit d’un choix assez structurant de votre application.
Pour plus d’information, je vous recommande vivement de lire la page sur les best practices afin de vous faire une idée de comment travailler avec Liquibase. Cette page vous suggérera une autre manière de faire à mi-chemin des 2 précédentes.
Intégration via la ligne de commande
Afin d’obtenir une meilleur intégration en ligne de commande, vous pourrez trouver un petit script dans le projet le script liquibase.sh qui vous permettra d’intégrer facilement Liquibase avec Maven au sein de votre application. Vous trouverez le fichier sur le repository Github : liquibase.sh. Pour l’utiliser chez vous, il vous faudra juste copier le contenu et changer la commande cd (change directory) afin de l’adapter à vos besoins
Désormais, vous pourrez facilement utiliser le plugin Maven depuis la ligne de commande ! Et bien sûr, à travers quelques modifications, l’intégrer dans votre processus d’intégration continue. Pour les explications, il ne me semble pas que cela soit nécessaire.
Intégration avec Spring-boot ou un autre système
Spring-boot
Avec Spring-boot, la bonne nouvelle, c’est que l’intégration est extrêmement simple puisqu’il suffit de configurer correctement les propriétés suivantes afin d’intégrer Liquibase au sein de votre application et de mettre ainsi la base à jour automatiquement :
# LIQUIBASE
liquibase.change-log=classpath:/db/changelog/db.changelog-master.yaml
liquibase.check-change-log-location=true # check the change log location exists
liquibase.contexts= # runtime contexts to use
liquibase.default-schema= # default database schema to use
liquibase.drop-first=false
liquibase.enabled=true
liquibase.url= # specific JDBC url (if not set the default datasource is used)
liquibase.user= # user name for liquibase.url
liquibase.password= # password for liquibase.url
Pour plus de détails sur la configuration de Spring-boot, vous pouvez consulter la page suivante : Common application properties
Ainsi, avec Spring-boot, il est tout à fait possible de jouer sur les profils afin d’avoir plusieurs fichiers de configurations. Par exemple, si vous démarrer votre application avec le profil patouche, le fichier de configuration application-patouche.properties pourra être chargé en plus du fichier properties.
Si l’idée de pousser vos mots de passe en clair dans un fichier .properties vous horrifie, vous pouvez très bien définir ceux-ci comme des variables d’environnement ou des paramètres au lancement de votre application.
Et sans Spring-boot
Sans utiliser Spring-boot, il reste toujours possible d’utiliser Liquibase. En effet, cela demande juste un peu de code, mais rien ne vous empêche de l’utiliser. Donc plus de prétexte !
Afin de nous simplifier la tâche, voici une petite classe que j’ai écrite afin de réaliser une mise à jour de la base ou une vérification que l’intégralité des changeSets ont été appliqués sur celle-ci : LiquibaseHelper
Ainsi, au sein de votre application, lors de la création de votre dataSource, il vous sera alors tout à fait possible de demander à Liquibase d’effectuer l’une des actions :
- Vérifier que tous les changeSets sont bien passés
- Mettre à jour votre base de données (par exemple, si vous utilisez une base de données embarquée)
Voici un exemple d’une manière de mettre à jour la base de données dans le cadre de l’application Spring :
@Configuration
public class DataSourceConfiguration {
/**
* Create a data source base on H2 database and initialize the schema.
*
* @return the h2 dataSource
*/
@Bean
public DataSource dataSource() {
LOGGER.info("Create a H2 DataSource");
return new LiquibaseHelper(new EmbeddedDatabaseBuilder().setType(EmbeddedDatabaseType.H2).build())
.update()
.getDataSource();
}
}
Grâce à cela, la base embarquée H2 aura automatiquement son schéma de créé au démarrage de l’application !
Liquibase & les tests unitaires
Bien sûr, Liquibase est un outil de versioning de base de données. Toutefois, pourquoi ne pas l’utiliser dans les tests unitaires ? En effet, comme désormais on peut reconstruire un schéma de la base from scratch, il semble tout à fait normal de l’utiliser pour les tests unitaires !
Tester son code est quelque chose de nécessaire afin d’en valider le bon fonctionnement. Toutefois, bien tester n’est pas toujours facile à mettre en place. Surtout quand on combine tests et base de données, ça peut vite devenir assez pénible !
Donc, pour utiliser Liquibase dans les tests unitaires de vos DAO, il existe plusieurs solutions que nous allons tenter de voir. En l’occurrence, nous nous baserons sur le framework Spring & Spring-Data pour voir comment manipuler correctement Liquibase !
Un nouveau changeLog ?
Il serait possible de demander à Liquibase de charger les données de test, pour ensuite écrire nos tests du repository. Toutefois, je ne présenterai pas cette solution ici, parce qu’il me semble que ce soit la pire parmi celles à notre disposition !
En effet, Liquibase sert à nous simplifier la vie ! Pour expliquer le principe de cette solution, cela revient à faire un nouveau master changeLog qui charge le master changeLog avec le schéma de la base plus d’autres changeLogs avec les données de tests dedans. A chaque modification de la base, vous allez donc devoir reprendre des SQL dans des XML avec des données de tests.
Bref, comme vous l’avez compris, avec cette solution, cela peut très vite devenir impossible à maintenir !
Utiliser les annotations Spring ?
Oui, cela est une solution tout à fait acceptable et tout à fait maintenable !
Spring apporte beaucoup d’annotations pour nous simplifier la vie afin de tester notre code. Toutefois, il y en a tellement que ça ne nous simplifie pas toujours la vie. Parmi les annotations à disposition, il en existe certaines pour la base de données comme :
Pour rester simple, il suffit d’utiliser la précédente classe lors de la construction de la dataSource. En procédant de la sorte, cela ira très vite. Ensuite, à l’aide des annotations Spring, il sera tout à fait possible de charger des données et de réinitialiser la base afin d’avoir des tests indépendants les uns des autres.
Voici un exemple de la manière d’effectuer un test unitaire en déclarant le schéma à l’aide de Liquibase.
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes = { CommentRepositoryTest.TestConfig.class, SpringDataJpaConfiguration.class })
public class CommentRepositoryTest {
@Autowired
private CommentRepository commentRepository;
@Configuration
static class TestConfig {
@Bean
public DataSource dataSource() {
final EmbeddedDatabase dataSource = new EmbeddedDatabaseBuilder().setType(EmbeddedDatabaseType.H2).build();
return new LiquibaseHelper(dataSource).update().getDataSource();
}
}
@Test
@Sql(scripts = { "classpath:/repository/clean.sql", "classpath:/repository/comment/checkPredicates.sql" })
public void checkPredicates() throws Exception {
// ACT
Iterable<Comment> byPostId = this.commentRepository.findAll(CommentRepository.Predicates.byPostId(2L));
assertThat(byPostId).as("byPostId predicates").isNotNull().hasSize(1);
assertThat(byPostId).extracting("content").as("byPostId predicates").containsOnly("content-3");
}
}
Grâce à ces deux scripts, vous pourrez garder vos tests indépendants les uns des autres, tout en conservant des tests simples et maintenables. De plus, avec un bon IDE, vos scripts SQL seront facilement lisibles et totalement dé-corrélé de vos fichiers changeLogs.
Pour plus d’information sur le sujet, je vous conseille vivement d’aller consulter la documentation sur l’intégration JDBC avec Spring
Do it yourself !
L’autre solution revient finalement à ne pas du tout utiliser les annotations Spring et à charger utiliser Liquibase pour charger le schéma avant de lancer des tests unitaires sur un repository spring-data. Voici comment procéder :
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes = { CommentRepositoryTest.TestConfig.class, SpringDataJpaConfiguration.class })
public class CommentRepositoryTest {
@Autowired
private CommentRepository commentRepository;
@Autowired
private PostRepository postRepository;
@Configuration
static class TestConfig {
@Bean
public DataSource dataSource() {
final EmbeddedDatabase dataSource = new EmbeddedDatabaseBuilder().setType(EmbeddedDatabaseType.H2).build();
return new LiquibaseHelper(dataSource).update().getDataSource();
}
}
@Before
public void setUp() {
this.commentRepository.deleteAll();
this.postRepository.deleteAll();
}
@Test
public void checkPredicates() throws Exception {
// ARRANGE
final Post post1 = this.postRepository.save(new Post("author", "post-1", "content-1"));
final Post post2 = this.postRepository.save(new Post("author", "post-2", "content-2"));
final Comment comment1 = this.commentRepository.save(new Comment(post1, "author", "content-1"));
final Comment comment2 = this.commentRepository.save(new Comment(post1, "author", "content-2"));
final Comment comment3 = this.commentRepository.save(new Comment(post1, "author", "content-3"));
final Comment comment4 = this.commentRepository.save(new Comment(post2, "author", "content-4"));
final Comment comment5 = this.commentRepository.save(new Comment(post2, "author", "content-5"));
final Comment comment6 = this.commentRepository.save(new Comment(post2, "author", "content-6"));
// ACT
Iterable<Comment> byPostId = this.commentRepository.findAll(CommentRepository.Predicates.byPostId(post1.getId()));
// ASSERT
assertThat(byPostId).as("byPostId predicates").isNotNull().hasSize(3);
assertThat(byPostId).extracting("id").as("byPostId predicates")
.containsOnly(comment1.getId(), comment2.getId(), comment3.getId());
}
}
Cette méthode, bien qu’étant plus verbeuse, présente, à mon humble avis, le plus d’avantages. D’une part, c’est la plus simple à lire, puisqu’il n’est pas nécessaire d’aller chercher dans des fichiers séparés le contenu des données de tests. D’autre part, c’est également la plus simple à entretenir car toute modification de votre modèle vous sera directement signalée lors d’une phase de compilation des tests (sans avoir besoin de les lancer).
Enfin, je vous recommande fortement d’avoir des test sur votre couche d’accès aux données. Cela permettra de valider vos fichiers changeLogs tout en vous assurant la validité de votre modèle de données. Par ailleurs, le refactor n’en sera que plus aisé !
Conclusion
Finalement, Liquibase est un outil performant pour maintenir une synchronisation parfaite entre votre code et vos bases de données au sein d’une équipe. Pour bien comprendre tout l’intérêt et toute la puissance de l’outil, je vous recommande fortement de l’utiliser sur un de vos projets. Surtout que, désormais, vous avec une manière simple de l’intégrer très facilement donc pas d’excuse !