
Benchmark java : JMH et l’injection de données
 Pour faire suite à mes précédents posts consacrés à JMH, le framework de benchmarking de l’OpenJDK, voici la dernière partie, dans laquelle je m’intéresserai non pas au traitement benchmarké proprement dit, mais à la donnée sur laquelle il s’exécute. Quelle importance cette donnée peut-elle avoir ? En matière de performance, nous allons voir qu’étudier la vitesse d’un programme n’a de sens que dans un contexte précis d’exécution : pour faire un parallèle avec la course à pied, diriez-vous qu’un chrono de 2h02 est une belle performance ? Tout dépend s’il s’agit d’un marathon ou d’un 100m…
Pour faire suite à mes précédents posts consacrés à JMH, le framework de benchmarking de l’OpenJDK, voici la dernière partie, dans laquelle je m’intéresserai non pas au traitement benchmarké proprement dit, mais à la donnée sur laquelle il s’exécute. Quelle importance cette donnée peut-elle avoir ? En matière de performance, nous allons voir qu’étudier la vitesse d’un programme n’a de sens que dans un contexte précis d’exécution : pour faire un parallèle avec la course à pied, diriez-vous qu’un chrono de 2h02 est une belle performance ? Tout dépend s’il s’agit d’un marathon ou d’un 100m…
Injection de données

Lorsque l’on benchmark un morceau de code, on rencontre parfois des problématiques un peu similaires à celles des tests unitaires ; notamment, se pose la question de l’isolation du code cible avec le reste du monde.
Un exemple simple
Prenons le benchmark suivant, qui mesure le coût de l’ajout d’un jour (rolling) à une date donnée :
@Benchmark
public Calendar benchmark_roll_new_Date() {
// create a calendar set to "now"
Calendar c = Calendar.getInstance();
// roll "now" of 1 day
c.roll(Calendar.DAY_OF_YEAR, 1);
return c;
}
Ce benchmark est-il correct ? En un sens oui, il mesure le temps d’exécution de ce morceau de code. Néanmoins, ce n’est pas ce que l’on cherchait à mesurer : certes, on mesure ici le temps de rolling d’une date, mais on y ajoute également le temps de construction d’une instance de Calendar, ainsi que (et surtout) le temps d’un appel OS, pour récupérer la date système ! Cette opération système n’est pas gratuite, et peut même être significativement plus longue que le code que l’on souhaite réellement benchmarker, faussant alors complètement notre benchmark !
L’état géré par JMH
Heureusement, JMH prend en charge l’injection de données : il suffit de déclarer un type contenant un “état” (décoré d’un @State) à injecter au benchmark :
@State(Scope.Benchmark)
public static class DateContainer {
// an object DateContainer will be instanciatedd
// out of benchmark time by JMH Runner
// get system date (long time operation)
Calendar now = Calendar.getInstance();
// get a copy of "now" calendar (quick operation)
Calendar getCalendarSetToNow() {
return (Calendar) now.clone();
}
}
@Benchmark
public Calendar benchmark_roll_date_in_argument(DateContainer d) {
// get calendar for "now", created before benchmark
Calendar c = d.getCalendarSetToNow();
// roll date
c.roll(Calendar.DAY_OF_YEAR, 1);
return c;
}
De cette manière, le Runner JMH instanciera hors benchmark un objet DateContainer et le passera en argument à la méthode benchmark_roll_date_in_argument(). On peut ainsi se rendre compte de l’overhead dû à l’appel système pour récupérer la date, en comparant les résultats des 2 benchmarks ci-dessus :
Benchmark Mode Cnt Score Error Units benchmark_roll_date_in_argument avgt 10 88,728 ± 10,282 ns/op benchmark_roll_new_Date avgt 10 252,941 ± 107,716 ns/op
Près de 60% du temps (158 sur 252 ns) est passé dans l’appel système ! Celui-ci est donc loin d’être anodin.
State scope
 Vous remarquerez par ailleurs que le @State porte un Scope qui définit la visibilité de l’objet. En effet, que se passe-t-il lorsque le benchmark est réalisé en multi-threadé ? Le Scope répond à cette question :
Vous remarquerez par ailleurs que le @State porte un Scope qui définit la visibilité de l’objet. En effet, que se passe-t-il lorsque le benchmark est réalisé en multi-threadé ? Le Scope répond à cette question :
- en Scope.Banchmark, l’objet sera partagé parmi tous les threads gérés par JMH
- en Scope.Thread, chaque thread aura son propre objet non partagé
- en Scope.Group, l’objet sera partagé, mais au sein d’un groupe de threads seulement
Fixtures JMH
 Nous venons de voir que JMH gère pour nous le cycle de vie des objets @State, qui sont injectés en paramètre des méthodes de benchmark. Une question demeure cependant : à quel moment durant les cycles itératifs de JMH, ces objets sont-ils instanciés ?
Nous venons de voir que JMH gère pour nous le cycle de vie des objets @State, qui sont injectés en paramètre des méthodes de benchmark. Une question demeure cependant : à quel moment durant les cycles itératifs de JMH, ces objets sont-ils instanciés ?
En théorie
A la manière de JUnit, il existe dans JMH des « fixtures » pour initialiser et nettoyer ce contexte d’exécution avant et après le benchmark. Ainsi nous pouvons dire à JMH comment initialiser/détruire nos objets @State, en implémentant des méthodes annotées par un @Setup et @TearDown. Par ailleurs, on précisera un Level sur ces annotations, qui définira à quel moment elles doivent être appelées par le Runner :
- Level.Trial, déclenchera une exécution au début / à la fin du benchmark (i.e. la séquence d’itérations)
- Level.Iteration, déclenchera une exécution avant/après chaque itération
- Level.Invocation, déclenchera une exécution avant/après chaque invocation. (Attention, comme indiqué dans la javadoc, ce level peut aboutir à des résultats totalement biaisés sur des opérations < 1 ms ! Pour utilisateur averti.)

… Et en pratique
Dans l’exemple qui suit, on souhaite benchmarker le tri d’un tableau ; on utilisera alors les « fixtures » pour :
- créer un tableau d’entiers non trié au début du benchmark
- recopier ce tableau non trié avant chaque invocation, afin de le trier (on triera ainsi toujours les mêmes données à chaque invocation)
@State(Scope.Benchmark)
public static class ArrayContainer {
// initial unsorted array
int [] suffledArray = new int[10000000];
// system date copy
int [] arrayToSort = new int[10000000];
@Setup(Level.Trial)
public void initArray() {
// create a shuffled array of int
// ...
}
@Setup(Level.Invocation)
public void makeArrayCopy() {
// copy shuffled array to reinit the array to sort
arrayToSort = suffledArray.clone();
}
int[] getArrayToSort() {
return arrayToSort;
}
}
@Benchmark
public int[] benchmark_array_sort(ArrayContainer d) {
// sort copy of shuffled array
Arrays.sort(d.getArrayToSort());
// array is now sorted !
return d.getArrayToSort();
}
Le niveau Level.invocation étant susceptible de fausser le benchmak sur des invocations courtes (< 1 ms), on s’assurera que le coût des « fixtures » est négligeable face au tri, en benchmarkant un code “vide” :
@Benchmark
public int[] baseline(ArrayContainer d) {
// empty benchmark check the Level.Invocation setup fixture
// does not impact significativly the measures on benchmark_array_sort()
return null;
}
Les résultats obtenus nous confirmeront que l’appel des « fixtures » est bien indolore (0.001 << 10.222 ms) pour notre benchmark du tri :
Benchmark Mode Cnt Score Error Units baseline avgt 10 0,001 ± 0,000 ms/op benchmark_array_sort avgt 10 10,222 ± 0,065 ms/op
Benchmark paramétré
 Enfin, last but not least, il existe une annotation @Param grâce à laquelle il est possible de paramétrer un objet @State, comme pour les tests JUnit paramétrés. Le benchmark sera alors exécuté consécutivement avec chacune des valeurs du paramètre !
Enfin, last but not least, il existe une annotation @Param grâce à laquelle il est possible de paramétrer un objet @State, comme pour les tests JUnit paramétrés. Le benchmark sera alors exécuté consécutivement avec chacune des valeurs du paramètre !
Un premier exemple
Prenons le code du benchmark suivant :
@State(Scope.Benchmark)
public static class ArrayContainer {
@Param({ "10000", "100000", "1000000", "10000000", "100000000"})
int arraySize;
// initial unsorted array
int [] suffledArray;
// system date copy
int [] arrayToSort;
@Setup(Level.Trial)
public void initArray() {
// create a shuffled array of int
suffledArray = new int[arraySize];
// ...
}
// ...
}
Nous pouvons grâce à cela, jouer sur la taille du tableau à trier, et montrer ainsi la corrélation taille du tableau/temps de traitement :
Benchmark (arraySize) Mode Cnt Score Error Units baseline 10000 avgt 10 0,000 ± 0,000 ms/op baseline 100000 avgt 10 0,000 ± 0,000 ms/op baseline 1000000 avgt 10 0,001 ± 0,000 ms/op baseline 10000000 avgt 10 0,001 ± 0,000 ms/op baseline 100000000 avgt 10 0,003 ± 0,000 ms/op benchmark_array_sort 10000 avgt 10 0,466 ± 0,028 ms/op benchmark_array_sort 100000 avgt 10 4,208 ± 0,136 ms/op benchmark_array_sort 1000000 avgt 10 39,313 ± 0,569 ms/op benchmark_array_sort 10000000 avgt 10 395,908 ± 4,964 ms/op benchmark_array_sort 100000000 avgt 10 4042,115 ± 42,876 ms/op
Ces résultats nous montrent :
- que les mesures réalisées dans le contexte de ce benchmark ne sont pas biaisées par la fixture de niveau Level.invocation : en effet, les temps « baseline » (< 3 µs) sont très inférieurs aux temps des benchmark_array_sot() (> 486 µs)
- que ce tri a une complexité de type n.log(n)), comme le montre la courbe ci-dessous (échelle logarithmique) :
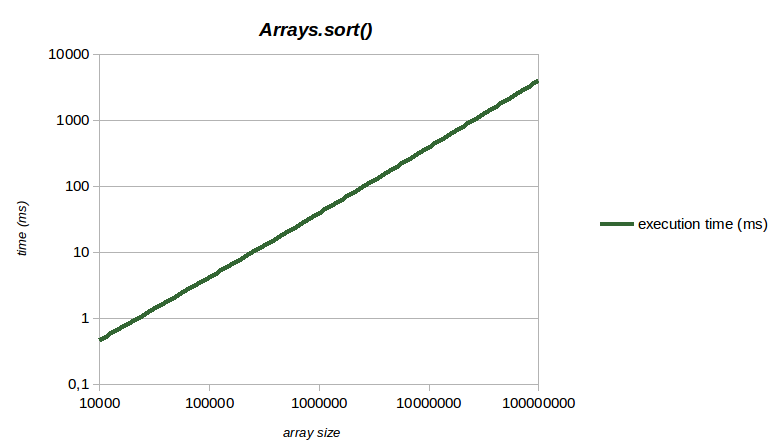
Deuxième exemple
Nous allons à présent comparer le tri “parallélisé” disponible depuis le jdk 8 via l’API stream avec le tri “classique”, à travers ce benchmark :
@State(Scope.Benchmark)
public static class ArrayContainer {
@Param({ "10", "15", "20", "25", "30", "40", "60", "80", "100", "200", "400", "800", "1000", "10000", "100000", "1000000", "10000000" })
int arraySize;
// …
}
@Benchmark
public int[] benchmark_array_sort(ArrayContainer d) {
// parallel sort
return Arrays.stream(d.getArrayToSort())
.parallel()
.sorted()
.toArray();
}
@Benchmark
public int[] baseline(ArrayContainer d) {
// sort
return Arrays.stream(d.getArrayToSort())
.sorted()
.toArray();
}
Bien évidemment, les processeurs actuels tout comme Rodrigue, ont beaucoup de cœurs, on s’attend donc à en bénéficier dans le tri parallèle ! Néanmoins, les résultats que nous obtenons sont plus subtils que cela (échelle logarithmique) :
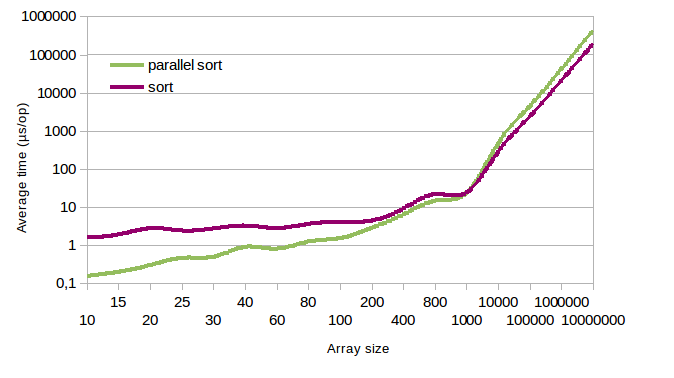
Nous pouvons constater que le tri parallèle est effectivement plus rapide (jusqu’à 2 fois), mais seulement à partir d’une taille critique (quelques milliers d’entiers) : en dessous de cette taille, le tri parallèle est jusqu’à 10 fois plus lent, le coup de la parallélisation étant supérieur au gain qu’elle apporte !
Conclusion
A travers ces quelques exemples, nous avons vu tout d’abord qu’un benchmark ne fait de sens que si l’on précise le contexte dans lequel il a été réalisé. On peut bien sûr y trouver une multitude de paramètres : configuration hardware, OS, architecture… mais surtout les données d’entrée, qui jouent un rôle très important ! En effet, les temps de traitement y sont la plupart du temps corrélés (leur volume bien sûr, mais aussi leur type, ou leur valeur). Heureusement, JMH fournit la boîte à outils pour paramétrer ses benchmarks, et ainsi :
- établir le type de corrélation qui peut exister (proportionnelle ? quadratique ? exponentielle ?) et la quantifier grâce aux mesures réalisées.
- déterminer des points d’inflexion ou des points de rupture (volume maximal de données qu’un algorithme peut traiter avant saturation)
- et même identifier des plages sur lesquelles le comportement peut changer.
Pour terminer enfin sur le sujet des benchmarks, je rappellerai une des leçons tirées de la physique quantique qui, malgré son « bilan mitigé », nous aura démontré que l’observation influence le phénomène observé, y compris quand il s’agit d’un benchmark : attention donc à la cohérence de nos résultats !