
Comprendre mapReduce


Depuis plusieurs années, nous entendons les termes BigData, noSql et mapReduce. L’évolution considérable du volume de données disponibles a changé notre façon de les stocker et de les traiter. Nous en avons de plus en plus et voulons les traiter de plus en plus vite. Mais comment traiter ces données rapidement et surtout avant qu’elles ne deviennent obsolètes ?
En 2004, Google publiait le résultat de ses recherches pour résoudre son problème d’indexation.
MapReduce était alors la solution pour répondre à la question : comment analyser 60 billions de pages uniques et en déduire un index de plus de 100 millions de gigaoctets permettant d’apporter le meilleur résultat aux recherches utilisateurs, tout cela en un temps le plus réduit possible ?
Cette solution a ensuite été reprise pour répondre à des problématiques rencontrées dans des domaines différents (média, santé, voyage, réseaux sociaux, etc.). Mais qu’il s’agisse de l’indexation de Google, de l’analyse de logs, du traitement de données du génome humain ou même de l’analyse d’images satellites, ces problématiques ont des similitudes. En d’autres termes, il existe des conditions à remplir avant de pouvoir appliquer mapReduce :
- avoir des calculs parallélisables (les résultats de calculs sur une partie de vos données doivent pouvoir être agrégés ensemble) ;
- traiter un gros volume de données (il faut qu’il soit assez volumineux pour que son morcellement lors des calculs ne nuise pas à la performance globale, on parle généralement en Teras) ;
- avoir un résultat final plus petit que le dataset en entrée ;
- les données traitées peuvent être converties en structures clé/valeur
De nombreuses entreprises se sont orientées vers une solution mapReduce car leurs problèmes avaient ces points communs. Et il est important de noter que tous les problèmes ne peuvent être résolus par mapReduce, sous peine d’avoir une solution moins performante et plus complexe à mettre en place.
Qu’est ce que mapReduce ?
MapReduce est un paradigme qui permet d’effectuer des calculs parallélisables sur un énorme volume de données (dataset stocké sur un filesystem ou dans une base de données) en utilisant un grand nombre de machines (cluster ou grid).
On définit une fonction map qui permettra de générer des tuples (clé/valeur) à partir du dataset. Ainsi qu’une fonction reduce pour déduire le résultat attendu à partir de ces tuples.

Pour illustrer le procédé mapReduce, nous allons prendre un exemple assez simple. L’idée est d’analyser la multitude de personnages de My Little Pony et de déterminer quel est le meilleur poney via un algorithme très complexe de scoring.
La fonction Map
A partir d’un ensemble de données, la fonction map va générer un autre ensemble de données sous forme de tuples (paire de clé/valeur).
Pour notre exemple, le dataset est l’ensemble des personnages de My Little Pony. Nous allons associer chaque poney (valeur) à un univers My Little Pony (clé).
Exemple de code java pour implémenter la fonction map avec le framework Hadoop MapReduce
public class MyLittlePonyMapper extends MapReduceBase
implements Mapper<LongWritable, MyLittlePonyCharacter,
PonyUniverse, Pony> {
@Override
public void map(final LongWritable key, final MyLittlePonyCharacter character,
final OutputCollector<PonyUniverse, Pony> output)
throws IOException {
// s’il s’agit d’un poney (tous les personnages ne sont pas des poneys)
if (isPony(character)) {
// on l’associe à Equestria (le royaume où vivent les personnages)
output.collect(PonyUniverse.Equestria, new Pony(character));
}
}
}
Ici nous avons un Mapper (MyLittlePonyMapper) qui implémente la fonction map. Le mapper est défini avec un tuple d’entrée LongWritable/MyLittlePonyCharacter et un tuple de sortie PonyUniverse/Pony. Ce que l’on pourrait également exprimer sous la forme du lambda : (LongWritable key, MyLittlePonyCharacter character) -> (PonyUniverse.Equestria, new Pony(character))
La fonction map va parcourir chaque MyLittlePonyCharacter du dataset et, s’il s’agit d’un poney (tous les personnages ne sont pas des poneys), on l’associe à Equestria (le royaume où vivent les personnages). Cette fonction nous permet ici de filtrer les données et de les associer à une clé.

La fonction Reduce
A partir des résultats issus de la fonction map, les tuples sont combinés pour être réduits en un plus petit ensemble de tuples.
Exemple de code java implémentant la fonction reduce avec le framework Hadoop MapReduce
public class TopPonyReducer extends MapReduceBase
implements Reducer<PonyUniverse, Pony, PonyUniverse, TopPony> {
@Override
public void reduce(PonyUniverse key, Iterator<Pony> values,
OutputCollector<PonyUniverse, TopPony> output)
throws IOException {
TopPony topPony = new TopPony();
while (values.hasNext()) {
Pony pony = values.next();
// la classe TopPony ne conserve que le Pony ayant
// le meilleur score
topPony.add(pony, computePonyScore(pony));
}
output.collect(key, topPony);
}
private double computePonyScore(Pony pony){
double score = 0.0;
//algorithme secret et très complexe de scoring des poneys
return score;
}
}
Ici, nous avons un Reducer (TopPonyReducer) qui implémente la fonction reduce. Le reducer est défini avec un tuple d’entrée PonyUniverse/Pony (qui est le tuple de sortie du map) et un tuple de sortie PonyUniverse/TopPony. On suppose que TopPony ne garde que le poney ayant le meilleur score.
En amont de la fonction reduce, le framework va agréger les résultats issus de la fonction map. C’est pourquoi la fonction reduce prend en paramètres PonyUniverse key, Iterator<Pony> values et non PonyUniverse key, Pony value. La fonction reduce va ainsi pouvoir parcourir une collection de valeurs associées à une clé. Ici, pour chaque Pony, nous allons calculer son score ce qui va permettre de le classer.
Comme nous n’avons créé qu’une seule clé lors du map (PonyUniverse.Equestria), le reduce a été effectué sur une seule clé.
En sortie du reduce, nous avons donc notre résultat final : le meilleur poney d’Equestria.

Comment fonctionne Hadoop MapReduce?
Une fois nos fonctions map et reduce définies, il faut spécifier leur enchaînement et leur configuration au framework Hadoop. Pour cela, nous créons un job qui s’occupera également de lancer l’exécution des fonctions.
NB : Hadoop permet d’enchaîner les jobs map et reduce, en utilisant les classes ChainMapper et ChainReducer. On peut composer des jobs Map/Reduce jobs respectant l’expression [MAP+ / REDUCE MAP*]
Exemple code java pour lancer un job mapReduce avec le framework Hadoop MapReduce
private static void runBestPony(final Configuration conf, final Path in, final Path out) {
JobConf jobConf = new JobConf(conf);
jobConf.setJarByClass(PonyRunner.class);
jobConf.setJobName("WHO_IS_BEST_PONY");
// formats d'entrée et de sortie
jobConf.setInputFormat(SequenceFileInputFormat.class);
jobConf.setOutputFormat(SequenceFileOutputFormat.class);
jobConf.setOutputKeyClass(PonyUniverse.class);
jobConf.setOutputValueClass(TopPony.class);
LOG.info("Job 1 pony mapper.");
// 1er job filtre et map les poneys
JobConf ponyMapperConf = new JobConf(false);
copyConfigurationProperties(conf, ponyMapperConf , HDFS_INPUT_PONY_FILE);
ChainMapper.addMapper(jobConf, MyLittlePonyMapper.class, LongWritable.class,
MyLittlePonyCharacter.class, PonyUniverse.class, Pony.class, true, ponyMapperConf);
LOG.info("Job 2 top pony reducer.");
// 2ème job classement des poneys pour déterminer le meilleur
JobConf topPonyReducerConf = new JobConf(false);
copyConfigurationProperties(conf, topPonyReducerConf);
ChainReducer.setReducer(jobConf, TopPonyReducer.class, PonyUniverse.class,
Pony.class, PonyUniverse.class, TopPony.class, true, topPonyReducerConf );
// chemins d'entrée et de sortie
FileInputFormat.setInputPaths(jobConf, in);
FileOutputFormat.setOutputPath(jobConf, out);
try {
LOG.info("Running Job");
// lancement du job
RunningJob runningJob = JobClient.runJob(jobConf);
runningJob.waitForCompletion();
} catch (IOException e) {
String erreur = "Erreur lors de l'accès au HDFS";
LOG.error(erreur, e);
LOG.info("in : " + in.toString());
LOG.info("out : " + out.toString());
throw new ApplicationException(erreur, ReturnCode.HDFS_ERROR);
}
}
Nous avons maintenant notre job mais comment fonctionne la parallélisation et l’enchaînement des fonctions ?
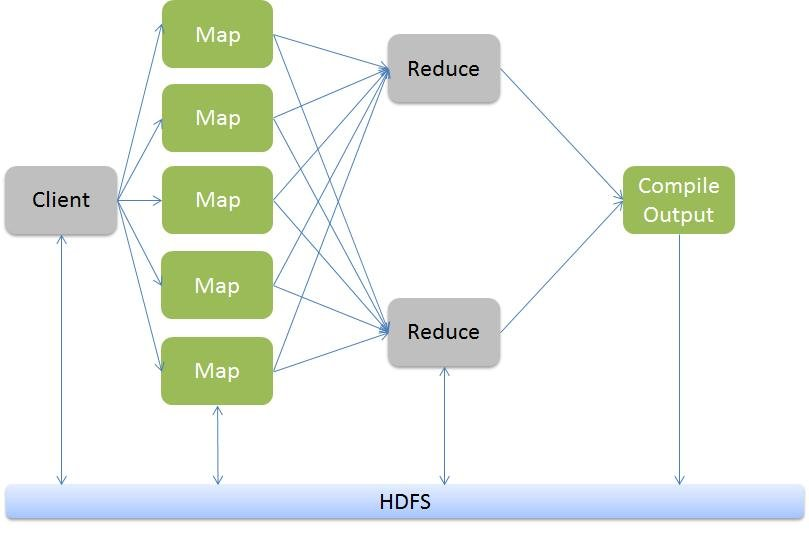
Avec Hadoop, il existe un job tracker. Il va diviser les traitements et les attribuer aux différents task trackers en fonction de leurs capacités. Sur chaque machine du cluster (une machine est également appelée un noeud) pouvant effectuer des opérations, il existe un task tracker. Celui-ci reçoit les opérations à traiter par le job tracker et l’informe de l’issue de l’opération. Nous avons maintenant notre job mais comment fonctionne la parallélisation et l’enchaînement des fonctions?
Pour chaque map terminée avec succès, le résultat est récupéré et copié localement sur les nœuds qui effectueront un reduce (cette opération est appelée shuffle). Une fois les données récupérées, le framework fusionne les résultats en se basant sur les clés (cette opération est appelée sort). Lorsque les opérations de shuffle et sort sont terminées pour les données à traiter, la fonction reduce est lancée.
Le résultat des reduces est ensuite compilé et copié sur le HDFS (Hadoop Distributed File System).
Concrètement par rapport à notre exemple cela donnerait :
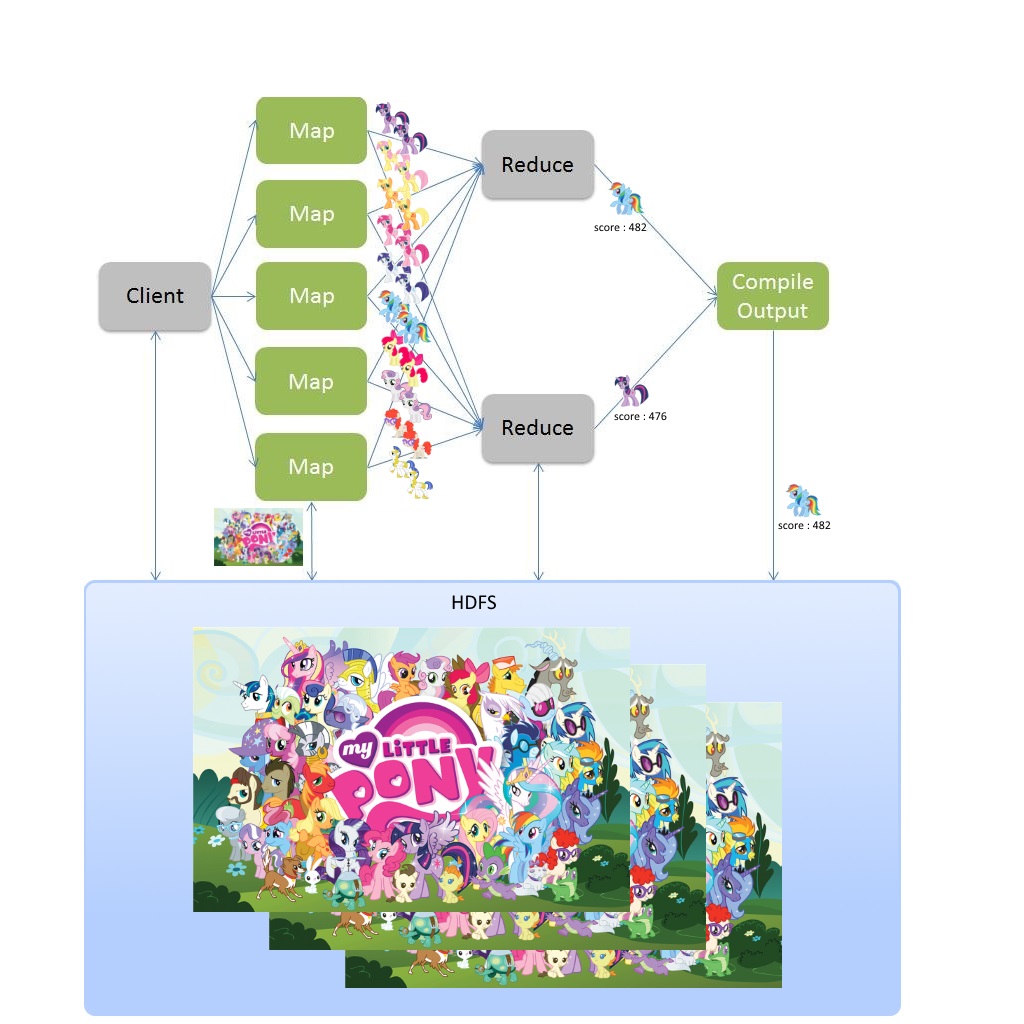
Les personnages de My Little Pony sont stockés et dupliqués sur le HDFS (par défaut il y a 3 réplications de chaque donnée). Les personnages sont transférés à la fonction map dont les exécutions sont réparties sur les nœuds du cluster. Chaque fonction map sera exécutée avec les données disponibles sur son nœud. Les résultats des fonctions map sont transmis à la fonction reduce, elle aussi répartie sur les nœuds du cluster. Le nombre de fonctions map et reduce à exécuter est calculé en fonction du volume des données. Comme nous avons moins de données en sortie du map qu’il y en avait en entrée, il y a moins de fonctions reduce que de fonctions map à traiter. Une fois que nous avons les résultats de toutes les exécutions de la fonction reduce, ceux-ci sont agrégés et écrits sur le HDFS. Comme vous l’aurez compris grâce au schéma, le meilleur poney est donc : Rainbow Dash.

En quelques mots
MapReduce est une solution permettant de traiter des problématiques spécifiques nécessitant des calculs sur un gros volume de données. Le problème va être découpé en sous-problèmes dont les calculs vont être distribués sur plusieurs machines (ce qui permet une distribution du temps de traitement et des données à traiter). Les résultats seront ensuite agrégés.
A noter qu’il est possible de faire des tests unitaires de vos fonctions grâce à des librairies comme MRUnit.
D’autre part, de nouveaux design patterns ont émergés. Ils ont pour vocation d’apporter la meilleure façon d’implémenter mapReduce sur différents types de problématiques.
L’avenir de mapReduce
L’innovation dans ce domaine n’ayant pas cessé, un nouveau produit est en train d’émerger : cloud dataflow. Cette solution Google basée principalement sur Flume et MillWheel est le successeur des implémentations mapReduce dans leurs bureaux. Il permettrait de s’affranchir de certaines limitations de mapReduce notamment en termes de scaling et de traitement de stream de données, tout en étant encore plus performant.
“Cloud Dataflow is the result of over a decade of experience in analytics,” Hölzle said. “It will run faster and scale better than pretty much any other system out there.”