
Le LoadBalancing
 Il est une chose que partagent à la fois les composants réseaux, les serveurs et à plus bas niveau les composants ou modules applicatifs, c’est qu’au-delà d’une certaine charge, ces éléments ne rendent plus le service attendu.
Il est une chose que partagent à la fois les composants réseaux, les serveurs et à plus bas niveau les composants ou modules applicatifs, c’est qu’au-delà d’une certaine charge, ces éléments ne rendent plus le service attendu.
Les systèmes de monitoring mis en place permettent de lever des alertes avant d’atteindre ce point de rupture, mais ne permettent pas de le résoudre. Sont apparues alors, des solutions comme la spécialisation des composants et la parallélisation des traitements, mais qui ne conduisirent qu’à une sollicitation encore plus importante du système en place. Des réponses en vue d’améliorer la scalabilité, ont alors vu le jour, mais étendre un système n’est pas toujours chose aisée.
Dans cette démarche, la contrainte financière est le premier frein. Elle trouve ses motivations entre autres dans des contraintes liées à l’applicatif qui n’est souvent pas facile à étendre (ancien programme, médiocrité de design …).
Un des moyens auquel on a recourt en général pour résoudre ce type de problèmes est la mise en place de la répartition de charge. Ceci se traduit par un déploiement de l’applicatif ou de ses différents modules sur différentes machines pour absorber le surplus de la charge.
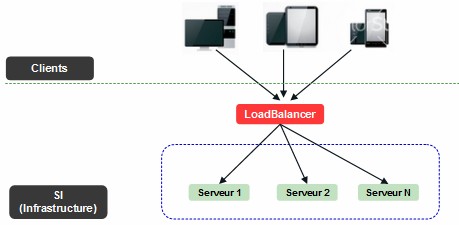
Figure 1.1 : Infrastructure simple sans redondance
La capture d’écran ci-dessous illustre un cas simple de répartition de charge. Pour des raisons de simplicité, elle n’intègre pas le reste des éléments de l’infrastructure (FireWall, Routeurs, Switchs …).
Dans cet article nous allons mettre la lumière sur différents moyens que l’on peut mettre en œuvre pour obtenir cette répartition de charge.
LES ALGORITHMES UTILISES
Aléatoire
La répartition ne considère aucune règle ni spécificité si ce n’est celle d’une distribution complètement aléatoire. Elle conduit théoriquement à un équilibrage de la charge assez satisfaisant pour des plateformes à très haute fréquentation.
Round-Robin
C’est un des algorithmes les plus utilisés en raison de sa simplicité et de sa facilité de mise en œuvre. Il conduit également à un bon équilibrage de la charge. Les instances concernées par la répartition sont présentées dans une liste où les éléments constituants sont permutés en permanence et de façon cyclique. Une liste de 3 éléments S1, S2, S3 sera donc présentée une première fois en tant que (S1, S2, S3), puis (S2, S3, S1), puis (S3, S1, S2) ainsi de suite ….
Round-Robin Pondéré
C’est une variante du round-robin simple, qui prend en compte les différentes capacités des éléments constituant la ferme de serveurs. Ainsi, un serveur deux fois plus puissant pourrait recevoir deux fois plus de requêtes. Cet algorithme répond mieux au besoin des plateformes hétérogènes (différentes machines avec différentes capacités).
Fonction du Nombre de Connexions
La requête est orientée vers le serveur ayant le moins de connexions ouvertes.
Fonction du Nombre de Connexions Pondérés
Il s’agit d’une variante de l’algorithme précédent qui prend en compte les différences de puissances entre éléments constituants la ferme de serveurs. Elle permet donc d’affecter des coefficients de pondération par instance, et de répartir en fonction des différentes capacités.
LES DIFFÉRENTS NIVEAUX DE RÉPARTITION DE CHARGE
Parmi les différents niveaux de répartition de charges, on distingue trois niveaux :
- La répartition niveau TCP : on parle de répartition de niveau L4 ou de niveau transport.
- La répartition niveau HTTP : on parle de répartition de niveau L7 ou de niveau applicatif.
- La répartition niveau DNS : il s’agit également d’une répartition de niveau L7.
Répartition Niveau TCP
Dans le modèle OSI, le protocole TCP est le responsable du transport de l’information échangée entre la partie client et la partie serveur. Une connexion est alors établie entre les deux parties pour permettre l’échange dans les deux sens (requête/réponse). C’est durant cette étape d’établissement de connexion que le routage est réalisé vers une IP plutôt qu’une autre, permettant ainsi une répartition de la charge. A ce niveau, Il s’agit donc d’un simple aiguillage des paquets IP.
Répartition Niveau HTTP
Le protocole HTTP est un protocole sans état. Dans ses premières versions HTTP, chaque couple requête/réponse consommait et partageait une seule et même connexion.
Avec les dernières versions de HTTP, il est possible via la routine « keepAlive » d’améliorer ce comportement en permettant la réutilisation d’une même connexion pour plusieurs requête/réponse. En effet, par défaut, une connexion est ouverte à chaque nouvelle requête reçue, puis immédiatement fermée dès réception de la réponse correspondante.
Un répartiteur de charge niveau L7 acte comme un proxy (on parle parfois de reverse proxy) entre la partie client et la partie serveur. Deux connexions sont alors créées. Les paquets IP venant du client transitent via la première connexion; ils sont ensuite assemblés au niveau du répartiteur pour permettre l’analyse des éléments de la requête permettant de décider du routage, puis envoyés après détermination du routage via la deuxième connexion vers l’IP ou le serveur adéquat.
Les mécanismes d’analyses les plus courants se basent soit sur l’utilisation des cookies (générés par le serveur ou par le répartiteur lui-même) soit sur l’utilisation des patterns URL/URI correspondant aux ressources demandées.
Notons que la répartition niveau L7 est également utilisée pour gérer une certaine affinité de session avec un serveur donné.
Répartition Niveau DNS
Il s’agit d’une répartition qui intervient lors de la résolution DNS. Il est fréquent qu’un nom de domaine soit associé à plusieurs serveurs, donc à plusieurs IP. Le serveur DNS retourne donc, non pas une adresse IP, mais plusieurs sous forme de liste dont les éléments sont permutés de façon continue.
Les serveurs DNS appliquent en général un algorithme de type Round-Robin conduisant à un équilibrage satisfaisant, ceci en orientant à tour de rôle sur les différents éléments constituant la liste.
D’autres algorithmes existent comme le « Geo DNS » permettant de faire une répartition par zone géographique. Un client est alors dirigé vers le serveur le plus proche.
La répartition DNS est utilisée en général pour assurer une distribution de la charge entre « data center ». En effet, elle n’est pas très adaptée pour assurer la répartition entre serveurs d’un même « data center ». Les répartitions de niveau L4 et L7 sont plus adéquates et plus indiquées dans ces cas.
En comparant les mécanismes de répartition de niveau L4 et L7, on constate qu’au niveau L7 les traitements sont un peu plus lourds. Ceci bien évidement a un coût, mais la puissance des équipements actuels tend à réduire l’impact de cette différence. Pour avoir un ordre d’idée, le coût de la répartition niveau L7 reste inférieur à la milliseconde alors que celle de niveau L4 a un coût qui est de l’ordre de la microseconde.
Les différences qui peuvent justifier le choix de l’un par rapport à l’autre, résident dans le fait que les répartiteurs de charges niveau L7 sont moins intrusifs et qu’ils permettent plus facilement d’inspecter et de valider les flux, ce qui est important pour des préoccupations de sécurité. C’est pour cela que les répartiteurs de niveau L7 sont parfois considérés comme des remparts entre le client et le serveur.
En pratique, les deux types de répartiteurs trouvent leur place facilement au sein d’une même infrastructure car ils sont utilisés à des niveaux différents en rapport avec leurs points forts.
LES TYPES DE RÉPARTITEURS
Sur le marché, on distingue deux types de répartiteurs :
- Répartiteur de type logiciel: HAProxy (L4+L7), IPVS (IP Virtual Server, L4), Apache mod_proxy_balancer (L7) …
- Répartiteur de type équipement réseau : Boitier HAProxy, F5, ACE, Altéon …
Notons que certains de ces équipements peuvent être utilisés aussi bien pour la répartition niveau L4 que L7. Il est conseillé quand c’est possible de choisir les solutions matérielles car elles sont plus performantes et sont accompagnées en général de solutions de supervisions (des fois en temps réel aka HAProxy, F5), ce qui est important pour des besoins de suivi et d’analyse.
Rappelons simplement que les critères de performance ne suffisent pas toujours pour justifier le choix d’un répartiteur plutôt qu’un autre. Ceci doit être guidé par un ensemble de critères comme la pertinence de(s) l’algorithme(s) implémenté(s), par les aspects sécurité (besoin HTTPS, SSL ou pas), la possibilité de configuration à chaud …
LA TOLÉRANCE AUX PANNES
La répartition de charge est utilisée comme un moyen d’amélioration de la qualité de service. Elle permet une nette amélioration des temps de réponses tout en garantissant une haute disponibilité du système. Or, les répartiteurs de charges comme le reste des éléments d’une infrastructure entreprise, ont leurs limites et peuvent constituer un point de rupture (SPOF ou Single Point Of Failure).
Au sein d’une architecture haute disponibilité, ces équipements sont installés en redondance. Un premier équipement assure la répartition, il est dit actif. Le second dit passif assurera le relai en cas de défaillance du premier. A ce titre, il vérifie de façon périodique, l’état de fonctionnement de son homologue/jumeau.
Les équipements les plus évolués partagent certaines informations liées à leur contexte de fonctionnement comme la table d’allocation de connexions. Le but est d’assurer la continuité du service sans perte de connexion, donc de façon complètement transparente vis à vis du client.
Cette surveillance d’un équipement par son homologue, surtout si elle est accompagnée d’une certaine synchronisation de configuration, finit par avoir un coût. Pour ne pas faire supporter ceci au réseau global/local, les équipements redondants sont liés en général par un dispositif dédié (simple câble Ethernet, Switch ou autre).
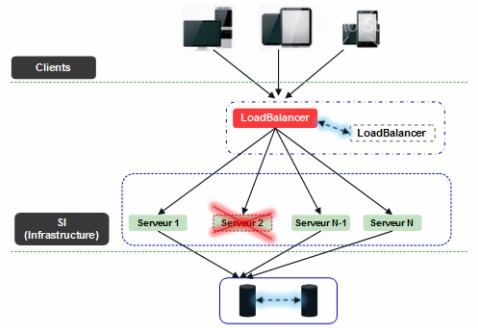
Figure 5.1 : Infrastructure avec redondance
La capture d’écran ci-dessous illustre la mise en place de cette redondance. Elle illustre aussi un cas réel que les répartiteurs de charges doivent gérer. Si le répartiteur ne détecte pas que le « serveur 2 » est défaillant, il continuera à lui servir des requêtes. La tolérance aux pannes, cible du dispositif, ne sera, alors plus assurée. On comprend facilement l’importance d’exclure de la liste de répartition les éléments défaillants.
Il existe différents moyens permettant de vérifier l’état d’un serveur. Les plus utilisés se basent sur les niveaux L4 et L7. A titre d’exemple HAProxy permet via son fichier de configuration de définir une stratégie de validation via :
- Routine check: Il s’agit d’un test de niveau L4, durant lequel, il est réalisé un test d’ouverture de socket vers le serveur à tester.
- Routine httpchk: Il s’agit d’un test de niveau L7, durant lequel une requête HTTP est envoyée vers le serveur à tester.
Les deux stratégies ont des utilisations différentes. Dans le cas de serveur d’applications web, il est préférable d’utiliser la routine « httpchk», car la requête permet de valider à la fois la disponibilité du serveur et l’état de l’application. Le choix de la ressource demandée par la requête peut varier de la simple demande d’une ressource images au plus complexe comme l’invocation d’un service. Le code retour « HTTP Status » permet, alors, de valider ou pas l’état du serveur (et de l’application).
Conclusion
Dans cet article nous avons abordé quelques types de répartition de charge ainsi que certains algorithmes parmi les plus utilisés. Nous avons vu également que la répartition de charge est un pilier important des architectures hautes disponibilités. Nous avons aussi énuméré quelques critères permettant de choisir parmi les offres du marché.