
JVM Hardcore – Part 18 – Convertir une expression logique en bytecode


Java a 42 opérateurs différents répartis dans 14 niveaux de priorités. Pour certains langages comme Smalltalk, tous les opérateurs ont le même niveau de priorité, et seules les parenthèses permettent de le changer. Ce concept intéressant pour l’écriture d’un compilateur donne toutefois des résultats étonnants.
Par exemple, le résultat de l’expression arithmétique 3 + 5 * 2 est 16 et non 13. Pour rétablir la priorité des opérateurs arithmétiques il est nécessaire d’ajouter des parenthèses.
3 + (5 * 2)
Mais quel que soit le langage, les opérateurs pouvant être inclus dans une expression logique sont sensiblement identiques et pour la majorité d’entre eux, il est théoriquement possible d’écrire des expressions extrêmement complexes :
((--a + b += 10) << 1) <= c && (d / e.getValue() * f) | g
Heureusement, le bon sens nous interdit d’écrire des expressions ayant plus de cinq opérandes et effectuant des opérations diverses (opérations arithmétiques, logiques, relationnelles, assignations, etc.). Néanmoins, les compilateurs sont dans l’obligation de gérer les cas les plus complexes. Écrire un compilateur est compliqué et la transformation d’une expression logique en bytecode fait partie de l’une des tâches les plus complexes. Mais, aujourd’hui le sujet n’est pas la création d’un compilateur (nous gardons ce sujet pour plus tard), mais de comprendre les mécanismes rudimentaires nous permettant de traduire une expression logique en bytecode.
Le code est disponible sur Github (tag et branche)
Tous les articles déjà publiés de la série portent le tag jvmhardcore.
Analyse syntaxique
Sans entrer dans les détails, nous avons tout de même besoin de savoir comment un analyseur syntaxique va créer un graphe d’objets utilisables. En réalité, nous avons déjà traité ce cas dans les parties 7, 8 et 9 traitant de notre analyseur d’expressions arithmétiques.
Résumons les trois articles succinctement, nous avons créé un analyseur pouvant extraire des nombres, des opérateurs arithmétiques et des parenthèses à partir d’une chaîne de caractères, pour créer une liste représentant l’expression sous une forme postfixée (par exemple 3 4 + 2 *). Ensuite, à partir de cette forme postfixée nous avons créé un interpréteur pouvant résoudre des expressions arithmétiques en s’appuyant sur une pile. Le mécanisme de résolution étant le suivant :
- Lire l’expression de gauche à droite, un nombre ou un opérateur à la fois
- Lorsque l’on rencontre un nombre on l’empile
- Lorsque l’on rencontre un opérateur
- on dépile deux nombres du sommet de la pile
- on effectue l’opération (en se rappelant que le premier élément dépilé est la seconde opérande)
- on empile le résultat pour qu’il soit utilisé par l’opération suivante.
Lorsque tous ces concepts sont bien compris, il n’est pas compliqué de rajouter quelques opérateurs, tels que des opérateurs relationnels (<, <=, >, >=, ==, !=), logiques (&& et ||), bit à bit (<<, >>, >>>, &, | et ^), etc. tout en n’oubliant pas qu’ils peuvent avoir différentes priorités, mais aussi des littérales booléennes (true et false) et des variables – dont nous connaissons le type.
Étant donné que nous n’allons pas écrire un nouvel analyseur syntaxique, ni modifier l’ancien, nous partirons du principe que nous avons un analyseur syntaxique théorique, qui à partir de la chaîne de caractères suivante :
((a << 1) <= (b + c)) && ((d / e) | (f * g))
Génère une liste représentant l’expression postfixée :
a, 1, <<, b, c, +, <=, d, e, /, f, g, *, |, &&
et dont les littérales sont de type IntValue, les variables IntVariable, les opérateurs logiques LogicalOperator, les opérateurs relationnels RelationalOperator, les opérateurs arithmétiques ArithmeticOperator et les opérateurs bit à bit BitwiseOperator.
La classe IntValue contiendra des entiers.
public class IntValue {
final final Integer data;
public IntValue(Integer data) {
this.data = data;
}
}
Et la classe IntVariable, l’index de la valeur (de type int) d’une variable dans les variables locales.
public class IntVariable {
final final Integer data;
public IntVariable(Integer data) {
this.data = data;
}
}
Les opérateurs sont quant à eux des énumérations.
public enum LogicalOperator {
AND, // &&
OR; // ||
}
public enum RelationalOperator {
EQ, // ==
NE, // !=
LT, // <
LE, // <=
GT, // >
GE; // >=
}
public enum ArithmeticOperator {
PLUS, MINUS, TIMES, DIVIDE;
}
public enum BitwiseOperator {
SHL, // <<
SHR, // >>
USHR,// >>>
AND, // &
OR, // |
XOR; // ^
}
Note : Pour rester dans la simplicité, nous allons limiter les littérales et les variables au type int, et utiliser uniquement trois types d’opérateur en laissant de côté les opérateurs unaires (++ et --), d’assignation (=, +=, /=, etc.) et ternaires (? :).
A l’aide de ces nouveaux types, nous pouvons donc convertir la liste
a, 1, <<, b, c, +, <=, d, e, /, f, g, *, |, &&
en Java (où la valeur de a est à l’index 0, celle de b à l’index 1, etc.) :
List<Object> list = Arrays.asList(new IntVariable(0),
new IntValue(1),
BitwiseOperator.SHL,
new IntVariable(1),
new IntVariable(2),
ArithméticOperator.PLUS,
RelationalOperator.LE,
new IntVariable(3),
new IntVariable(4),
ArithméticOperator.DIVIDE,
new IntVariable(5),
new IntVariable(6),
ArithméticOperator.TIMES,
BitwiseOperator.OR,
LogicalOperator.AND
);
Arbre syntaxique
A partir de cette liste nous pouvons créer un arbre syntaxique (nommé aussi AST).
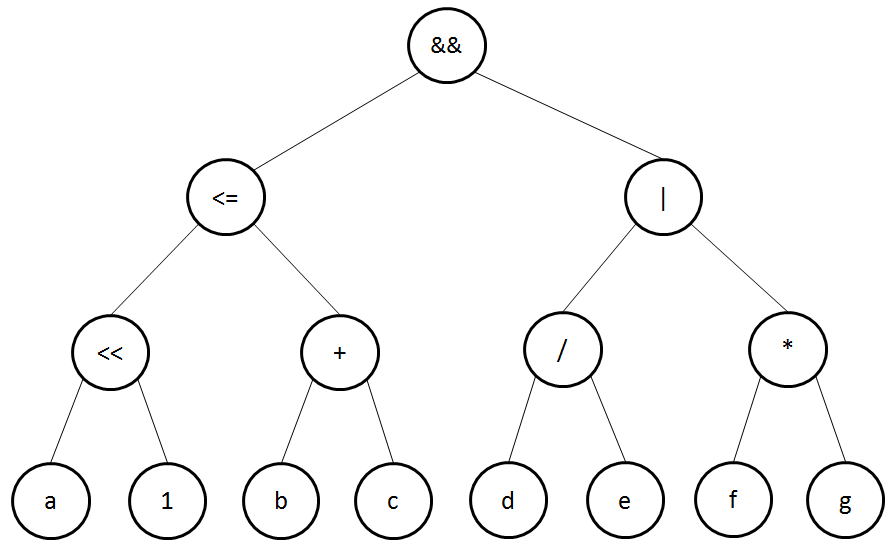
Un arbre syntaxique est un type de structure de données composé de nœuds, avec au sommet un nœud unique, nommé le nœud racine. Chaque nœud peut avoir zéro ou plusieurs enfants. Un nœud ne possédant pas d’enfant est dit terminal (aussi nommé une feuille).
Mais rien ne nous empêche d’avoir des arbres parcellaires (les feuilles ne sont pas toujours à la profondeur la plus élevée)
La profondeur (ou hauteur) est le nombre de nœuds qu’il faut traverser, en partant du nœud racine, pour atteindre le nœud qui nous intéresse (en comptant à partir de 0). Par exemple, sur le schéma ci-dessous, b a une profondeur de 2, d de 3, etc.

Dans le cas présent, il s’agit d’un arbre binaire, dont chaque nœud peut avoir au plus deux enfants, généralement identifiés par l’enfant de gauche et l’enfant de droite.
L’utilisation d’un arbre binaire est plutôt simple à comprendre si l’on considère que l’on utilise uniquement des opérateurs binaires (opérateurs nécessitant deux opérandes).
Un nœud d’un arbre binaire peut être représenté par l’objet Java suivant :
class Node<V> {
Node<V> left;
Node<V> right;
V data;
}
et une feuille :
class Leaf<V> {
V data;
}
Néanmoins, la classe Node implique que le type V soit identique pour tous les nœuds de l’arbre. Or pour représenter notre expression logique, nous savons déjà que nous avons un type IntValue et IntVariable. De fait, il nous faut utiliser un type commun pour les nœuds, leurs enfants et les feuilles.
public interface Expression {
}
public class Node<V> implements Expression {
final public Expression left;
final public Expression right;
final public V data;
public Node(Expression left, T data, Expression right) {
super();
this.left = left;
this.data = data;
this.right = right;
}
}
public class Leaf<V> implements Expression {
final public V data;
public Leaf(T data) {
super();
this.data = data;
}
}
En définitive, convertir un expression postfixée en arbre binaire est assez simple. Au lieu de résoudre l’expression comme nous l’avons vu dans la partie 9, l’opérateur doit être considéré comme le nœud parent de deux opérandes, qui seront ses enfants (ses branches de gauche et de droite). L’objet nouvellement créé est ensuite empilé sur la pile d’opérandes (pile de l’analyseur syntaxique à ne pas confondre avec la pile d’un cadre). Pour être potentiellement dépilé et devenir l’enfant d’un nouveau nœud parent.
Si l’on prend seulement une partie de l’expression logique d’exemple, nous pouvons la représenter en Java de la manière suivante (où IntVariable et IntValue étendent Leaf) :
// a, 1, <<, b, c, +, <=
new Node<RelationalOperator>(
new Node<BitwiseOperator>(
new IntVariable(0),
BitwiseOperator.SHL,
new IntValue(1)
),
RelationalOperator.LE,
new Node<BitwiseOperator>(
new IntVariable(1),
BitwiseOperator.PLUS,
new IntVariable(2)
)
)
Cela étant, certaines expressions nécessitent d’être adaptées avant que l’on puisse créer un arbre syntaxique, puisqu’elles manquent d’informations en raison de ce que l’on peut considérer comme du sucre syntaxique. Par exemple, l’expression a && b doit être décomposée en trois expressions :
(a == 1) && (b == 1)
ou
(a != 0) && (b != 0)
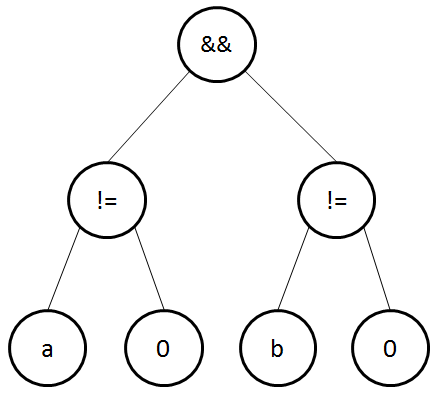
Notons que l’ajout d’objets manquants est à la charge de l’analyseur syntaxique, généralement lors de la génération de l’arbre syntaxique. Mais ce n’est pas une obligation. Cette tâche pouvant être effectuée dans une étape antérieure. L’idée étant que l’AST doit être complet lors de sa traversée qui permettra de générer du bytecode.
Traverser un arbre binaire
La traversée d’un arbre (binaire ou non) est le fait de parcourir tous les nœuds de l’arbre dans un ordre précis.
Il existe deux méthodes pour traverser un arbre :
- En largeur
- En profondeur
- préordre
- inordre
- postordre
En reprenant l’exemple précédent, voyons les différents cas :

Toute cette théorie ne doit pas nous faire perdre notre objectif, qui est de générer du bytecode, et c’est ce que nous allons faire en traversant notre arbre binaire.
Nous savons comment traverser un arbre binaire en théorie, voyons à présent comment le faire en Java, en nous contentant des traversées en profondeur, avec l’aide d’un visiteur :
public void preorder(Visitor visitor) {
visitor.visit(data);
if (left != null) left.preorder(visitor);
if (right != null) right.preorder(visitor);
}
public void inorder(Visitor visitor) {
if (left != null) left.inorder(visitor);
visitor.visit(data);
if (right != null) right.inorder(visitor);
}
public void postorder(Visitor visitor) {
if (left != null) left.postorder(visitor);
if (right != null) right.postorder(visitor);
visitor.visit(data);
}
Avec toutes ces informations, nous pouvons convertir des expressions contenant des opérateurs arithmétiques et bit à bit en bytecode très simplement grâce à la traversée postordre.
public interface Visitable {
void accept(Visitor visitor);
}
public interface Visitor {
void visit(ArithmeticOperator data);
void visit(BitwiseOperator data);
void visitIntValue(Integer integer);
void visitIntVariable(Integer integer);
}
Le patron de conception visiteur ne fonctionnant pas avec des génériques nous devons typer chacune des expressions, comme Node en ArithmeticExpression.
public class ArithmeticExpression extends Node<ArithmeticOperator> {
public ArithmeticExpression(Expression left,
ArithmeticOperator data,
Expression right) {
super(left, data, right);
}
@Override
public void accept(Visitor visitor) {
super.left.accept(visitor);
super.right.accept(visitor);
visitor.visit(this.data);
}
}
Il en va de même pour Node.
public class BitwiseExpression extends Node<BitwiseOperator> {
public BitwiseExpression(Expression left,
BitwiseOperator data,
Expression right) {
super(left, data, right);
}
@Override
public void accept(Visitor visitor) {
super.left.accept(visitor);
super.right.accept(visitor);
visitor.visit(this.data);
}
}
Nous pouvons donc créer une classe Compiler implémentant l’interface Visitor, dont la méthode compile() retourne une chaîne de caractères représentant le bytecode.
public class Compiler implements Visitor {
final private StringBuilder bytecode;
final private Expression expression;
public Compiler(Expression expression) {
this.bytecode = new StringBuilder();
this.expression = expression;
}
public String compile() {
this.expression.accept(this);
return this.bytecode.toString();
}
// ...
}
Il ne nous reste plus qu’à implémenter les quatre méthodes de l’interface Visitor.
public class Compiler implements Visitor {
// ...
@Override
public void visit(ArithmeticOperator operator) {
String instruction = null;
switch (operator) {
case PLUS:
instruction = "iadd";
break;
case MINUS:
instruction = "isub";
break;
case TIMES:
instruction = "imul";
break;
case DIVIDE:
instruction = "idiv";
break;
}
this.bytecode.append(instruction).append("\n");
}
@Override
public void visit(BitwiseOperator operator) {
String instruction = null;
switch (operator) {
case SHL:
instruction = "ishl";
break;
case SHR:
instruction = "ishr";
break;
case USHR:
instruction = "iushr";
break;
case AND:
instruction = "iand";
break;
case OR:
instruction = "ior";
break;
case XOR:
instruction = "ixor";
break;
}
this.bytecode.append(instruction).append("\n");
}
@Override
public void visitIntValue(Integer value) {
this.bytecode.append("ldc ").append(value).append("\n");
}
@Override
public void visitIntVariable(Integer indexInLV) {
this.bytecode.append("iload ").append(indexInLV).append("\n");
}
}
Notons que pour des raisons de simplicité, pour les variables et les littérales, nous utilisons uniquement les instructions ldc et iload, et non les instructions plus spécifiques lorsque nécessaire telles que bipush, sipush, iload_0, etc.
Nous pouvons tester la classe Compiler très simplement. Par exemple, essayons de convertir l’expression (a | 2) + 567 * b (où a et b sont des variables dont les valeurs sont respectivement aux index 0 et 1 des variables locales) en bytecode :
@Test
public void arithmeticAndBitwise() {
final Expression e = new ArithmeticExpression(
new BitwiseExpression(
new IntVariable(0),
BitwiseOperator.OR,
new IntValue(2)
),
ArithmeticOperator.PLUS,
new ArithmeticExpression(
new IntValue(567),
ArithmeticOperator.TIMES,
new IntVariable(1)
)
);
final Compiler compiler = new Compiler(e);
Assert.assertEquals("iload 0"
+ "ldc 2"
+ "ior"
+ "ldc 567"
+ "iload 1"
+ "imul"
+ "iadd",
compiler.compile());
}
Bien évidemment ceci fonctionne parfaitement puisque nous utilisons uniquement des littérales et des variables de type int. En introduisant d’autres types, les méthodes visit(ArithmeticOperator operator) et visit(BitwiseOperator operator) ne généreraient la bonne instruction que dans le cas où les deux opérandes sont de type int. Dans ce cas, il sera alors nécessaire de modifier légèrement le mécanisme, mais nous y reviendrons.
Pour l’instant, nous avons exploré une solution différente à celle de la partie 9 pour convertir une expression arithmétique (contenant des opérateurs arithmétiques et bit à bit) en bytecode, mais nous n’avons toujours pas abordé le cœur de l’article, qui est la conversion d’une expression logique (expression contenant des opérateurs arithmétiques et bit à bit, mais aussi logiques et relationnels).
Les opérateurs logiques et relationnels
Jusqu’à présent convertir une expression en bytecode était plutôt simple puisqu’il suffisait de traverser nos arbres dans l’ordre postordre et de générer l’instruction associée à chaque nœud. Néanmoins, avec l’introduction des opérateurs logiques et relationnels les choses se compliquent :
- l’exécution des instructions n’est plus linéaire, il est nécessaire de prendre en compte un mécanisme de débranchement et ;
- les opérateurs logiques n’ayant aucune instruction équivalente, il est nécessaire d’orchestrer ces débranchements de manière à obtenir le fonctionnement escompté. Pour ce faire, la seule solution est d’avoir un aperçu des nœuds parents avant de pouvoir traiter les nœuds enfant, de manière à faire le choix le plus adapté.
Sans plus tarder, voyons comment prendre en compte ces deux points.
Tout d’abord, il est nécessaire de fixer l’ordre des blocs ok et ko. Par exemple, en Java le bloc ok suit toujours la condition.
if (a < b) {
// bloc ok
} else {
// bloc ko
}
Dans le cas présent, mais aussi dans tous les cas ne contenant pas d’opérateurs logiques, il suffit d’inverser l’opérateur relationnel dans la condition. Si a et b sont des variables de type int, où les valeurs de a et b sont aux index 0 et 1 des variables locales, nous obtenons :
iload_0
iload_1
if_icmpge ko @ >= est l'inverse de <
@ bloc ok
ko:
@ bloc ko
Cela en tête, il nous suffit de reprendre le fonctionnement des classes ArithmeticExpression et BitwiseExpression, puis d’ajouter une méthode à l’interface Visitor, nous permettant de visiter l’opérateur BitwiseOperator
public class BitwiseExpression extends Node<BitwiseOperator> {
public BitwiseExpression(Expression left,
BitwiseOperator data,
Expression right) {
super(left, data, right);
}
@Override
public void accept(Visitor visitor) {
super.left.accept(visitor);
super.right.accept(visitor);
visitor.visit(this.data);
}
}
Il ne nous reste plus qu’à implémenter la méthode visit(RelationalOperator data) dans la classe Compiler.
public void visit(RelationalOperator operator) {
final RelationalOperator inverse = operator.inverse();
String instruction = null;
switch (inverse) {
case EQ:
instruction = "if_icmpeq";
break;
case GE:
instruction = "if_icmpge";
break;
case GT:
instruction = "if_icmpgt";
break;
case LE:
instruction = "if_icmple";
break;
case LT:
instruction = "if_icmplt";
break;
case NE:
instruction = "if_icmpne";
break;
}
this.bytecode.append(instruction).append(" ko\n");
}
Le test n’est quant à lui pas plus compliqué :
@Test
public void relational0() {
// a < b
final Expression e = new RelationalExpression(
new IntVariable(0),
RelationalOperator.LT,
new IntVariable(1)
);
final Compiler compiler = new Compiler(e);
Assert.assertEquals("iload 0\n"
+ "iload 1\n"
+ "if_icmpge ko\n",
compiler.compile());
}
Notons que les blocs ok et ko ne sont pas générés puisqu’ils ne font pas partie des expressions mais de structures telles que if/else, while, for ou return.
Outre le fait, qu’une fois encore la simplification nous a fait ignorer le cas des comparaisons avec 0 et par conséquent des instructions associées, ce mécanisme montre ses limites dès lors que l’on souhaite utiliser un opérateur logique :
- l’inversion de l’opérateur ne doit pas avoir lieu dans tous les cas
- le bloc de débranchement n’est pas toujours le bloc
ko, comme nous avons pu le voir dans quelques exemples des deux articles précédents.
Mais avant de poursuivre intéressons-nous à quelques cas nominaux restreints aux instructions de comparaison, c’est-à-dire pour lesquels les instructions ldc, load et les blocs ok/ko ont été omis.
| AND | OR | |
|---|---|---|
a == 1 X b == 1 |
ifeq koifeq ko |
ifne okifeq ko |
a == 0 X b == 0 |
ifne koifne ko |
ifeq okifne ko |
a < b X c > d |
if_icmpge koif_icmple ko |
if_icmplt okif_icmple ko |
a >= b X c <= d |
if_icmplt koif_icmpgt ko |
if_icmpge okif_icmpgt ko |
Note : Dans la colonne de gauche, le X doit être remplacé par AND dans la seconde colonne et OR dans la troisième.
A la vue de ces quelques cas, un pattern se dessine clairement.
a op b AND c op d
donne
op_inverse ko
op_inverse ko
et
a op b OR c op d
donne
op ok
op_inverse ko
Ceci et l’exemple précédent (concernant les expressions relationnelles) nous permettent d’esquisser trois règles :
- Si le nœud d’un opérateur relationnel n’a pas de nœud parent nous prenons l’opérateur inverse et le label associé à l’instruction est toujours
ko. - Si le nœud d’un opérateur relationnel est l’enfant de gauche d’un nœud AND nous prenons l’opérateur inverse.
- Si le nœud d’un opérateur relationnel est l’enfant de gauche d’un nœud OR nous prenons l’opérateur.
La totalité des expressions, contenant des opérateurs logiques, pouvant être écrite en Java suivent seulement ces trois règles que nous allons détailler.
Voyons l’ensemble des cas possibles.
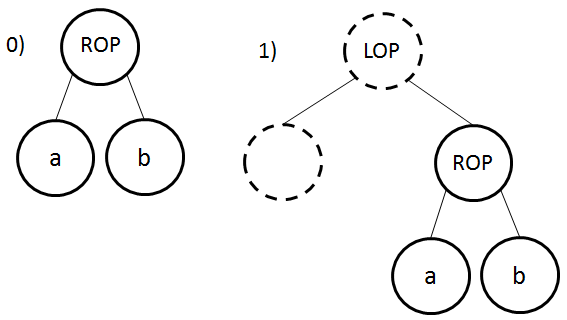
Règle 1 – Le nœud ROP n’est pas à gauche d’un nœud de profondeur inférieure
Notes :
- ROP signifie opérateur relationnel
- LOP signifie opérateur logique
Dans les deux cas ci-dessus, si a ROP b est vrai nous continuons à l’instruction suivante. Sinon nous devons débrancher vers le bloc ko.
Pour le cas 1, que le nœud LOP représente l’opérateur AND ou OR n’a pas d’importance, tout comme le fait que nous pourrions avoir une succession de nœuds LOP enfants de droite, puisque si le nœud ROP est le nœud le plus à droite, il n’y a plus d’alternative.
En conclusion, l’expression a ROP b sera transformée en bytecode de la manière suivante :
iload_0
iload_1
inverse_rop ko
iconst_1
ireturn
ko:
iconst_0
ireturn
La première règle est la suivante :
- Si un nœud ROP n’est pas à gauche d’un nœud de profondeur inférieure, nous prenons l’opérateur inverse et le label associé est
ko.
Règle 2 – Le nœud ROP est à gauche d’un nœud AND de profondeur inférieure
Pour comprendre cette règle, nous devons attribuer un label à tous les nœuds représentant des opérateurs logiques. Ces labels seront ceux utilisés en argument des instructions de comparaison en PJB ou lorsque l’on utilise la classe MethodBuilder.

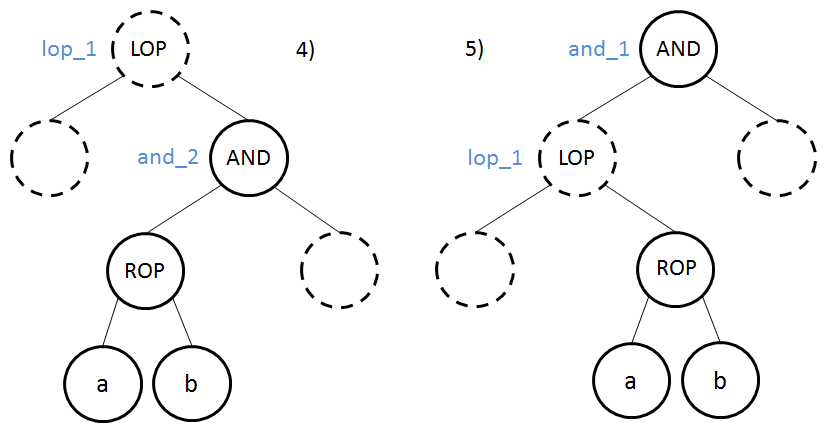
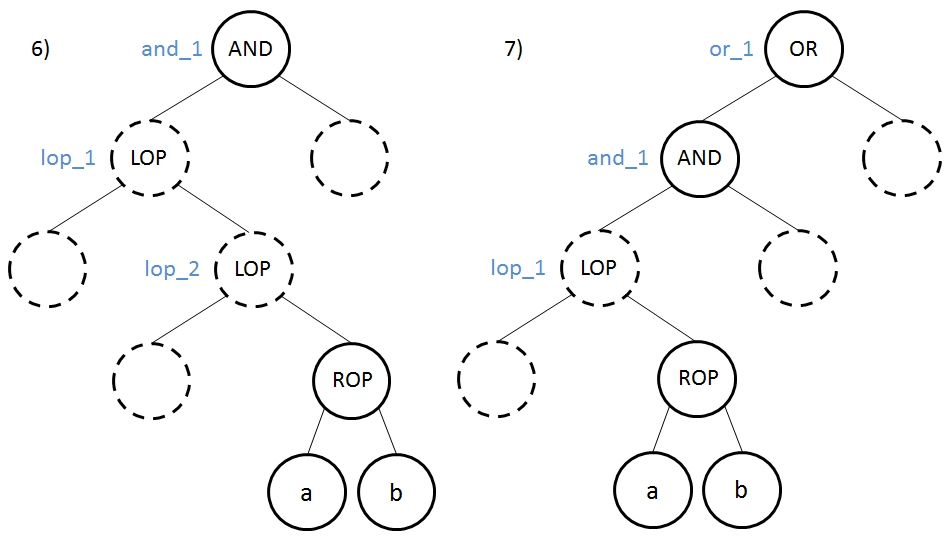
Si a ROP b est vrai, nous continuons au nœud suivant. Sinon nous devons débrancher vers le bloc ko (2, 4, 5 et 6) ou or_1 (3 et 7).
La deuxième règle est la suivante :
- Si un nœud
ROPest à gauche d’un nœudANDde profondeur inférieure, nous prenons l’opérateur inverse et le label associé est le nom du dernier nœudOR(celui le plus proche du nœudROPde profondeur inférieure) où le nœudROPappartient à un sous-arbre dont le nœud racine est à gauche du nœudOR.
Les cas 3 et 7 illustrent parfaitement l’utilisation du label d’un nœud OR. Pour le cas 7, le nœud ROP appartient à une sous-arbre dont le nœud racine AND (and_1) est l’enfant de gauche d’un nœud OR (or_1).
Règle 3 – Le nœud ROP est à gauche d’un nœud OR de profondeur inférieure

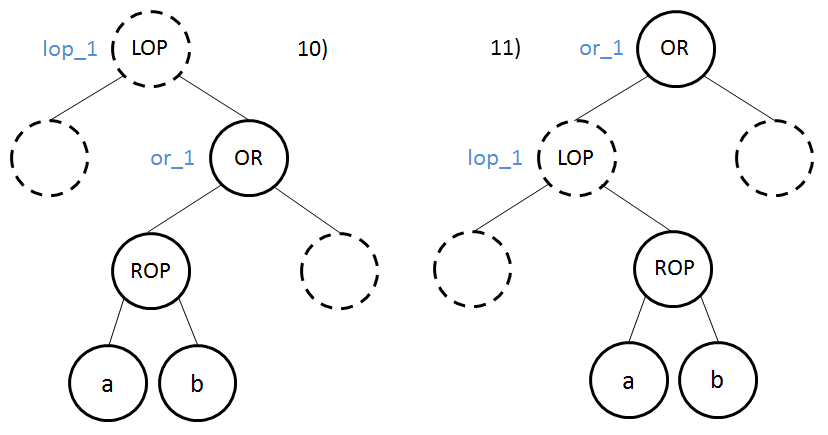
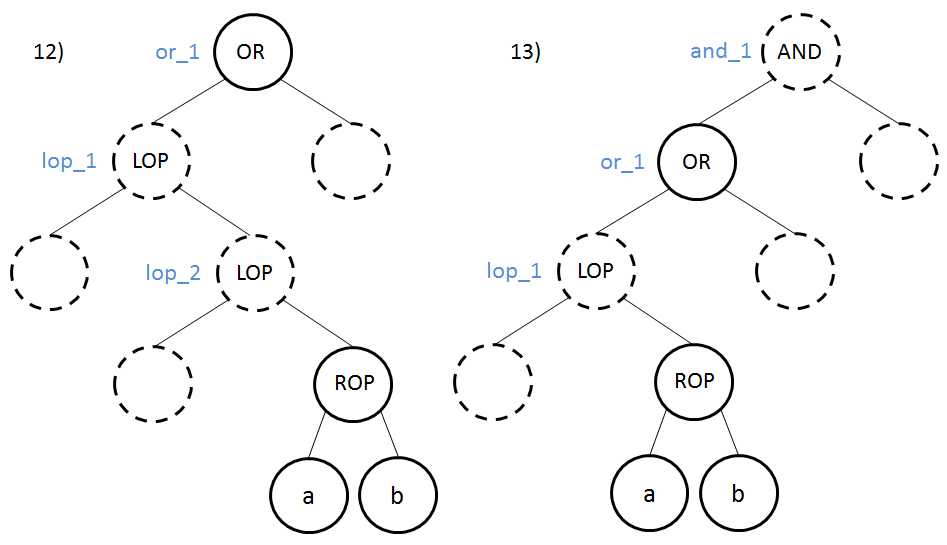
Si a ROP b est vrai, nous devons débrancher vers le bloc ok (8, 10, 11 et 12) ou and_1 (9 et 13). Sinon nous continuons au nœud suivant.
La troisième règle est la suivante :
- Si un nœud
ROPest à gauche d’un nœudORde profondeur inférieure, nous prenons l’opérateur. Le label associé est le nom du dernier nœudAND(celui le plus proche du nœudROPde profondeur inférieure) pour lequel le nœudROPappartient à un sous-arbre dont le nœud racine est à gauche du nœudAND.
Implémentation
Commençons par résumer nos trois règles. Si le nœud ROP, en train d’être visité
- n’appartient pas à un sous-arbre dont le nœud racine est l’enfant de droite d’un nœud
LOP(Le nœudROPpeut être le nœud racine du sous-arbre).
- Nous prenons l’opérateur inverse et générons l’instruction associée avec pour argument le label
ko.
- appartient à un sous arbre dont le nœud racine est l’enfant d’un
nœud
AND, nous prenons l’opérateur et générons l’instruction associée avec pour argument le nom du dernier nœudORs’il existe (où le nœudROPappartient à un sous-arbre dont le nœud racine est l’enfant de droite du nœudOR), sinonko.OR, nous prenons l’opérateur et générons l’instruction associée avec pour argument le nom du dernier nœudANDs’il existe (où le nœudROPappartient à un sous-arbre dont le nœud racine est l’enfant de droite du nœudAND), sinonok.
Pour répondre à ce besoin, nous allons utiliser trois piles :
- la première contenant les opérateurs logiques dont l’enfant de gauche est le nœud racine d’un sous-arbre en train d’être traversé ;
- la seconde contenant les labels des nœuds
ANDdont l’enfant de gauche est le nœud racine d’un sous-arbre en train d’être traversé et ; - la troisième contenant les labels des nœuds
ORdont l’enfant de gauche est le nœud racine d’un sous-arbre en train d’être traversé
Voyons à présent comment parcourir les nœuds LOP pour que la pile d’opérateurs logiques contienne les bonnes valeurs (le mécanisme est identique pour les deux autres piles).
[slideshare id=29937778&doc=18lopstraversal-140112172232-phpapp02]
Le fonctionnement théorique d’un compilateur d’expressions logiques en bytecode ayant été expliqué en détail, voyons comment nous pouvons traduire tout ceci en Java.
Nous allons tout d’abord ajouter une classe LogicalExpression qui à l’instar des classes XxxExpression que nous avons vues jusqu’à présent hérite de Node, mais contient aussi un champ name qui pourra être utilisé en tant que label.
public class LogicalExpression extends Node<LogicalOperator> {
final public String name;
public LogicalExpression(String name,
Expression left,
LogicalOperator data,
Expression right) {
super(left, data, right);
this.name = name;
}
@Override
public void accept(Visitor visitor) {
visitor.visitBeforeLeft(this.name, super.data);
this.left.accept(visitor);
visitor.visitAfterLeft(this.name, super.data);
this.right.accept(visitor);
}
}
La méthode accept() est légèrement différente de toutes celles que nous avons vu jusqu’à présent, puisque pour gérer les trois piles (présentées au-dessus), il nous faut visiter le nœud LOP deux fois. Une fois avant de visiter l’enfant de gauche et une seconde fois après l’avoir visiter, avant de visiter l’enfant de droite. Et ceci à l’aide de deux nouvelles méthodes ajoutées à l’interface Visitor, visitBeforeLeft() et visitAfterLeft(). Toutes deux prenant le nom du nœud et de son opérateur associé.
Pour que nous puissions utiliser les instructions de comparaison à zéro, la solution la plus simple est de rajouter une classe.
public class ZeroRelationalExpression extends RelationalExpression {
public ZeroRelationalExpression(Expression left) {
super(left, RelationalOperator.NE, null);
}
public ZeroRelationalExpression(Expression left,
RelationalOperator data) {
super(left, data, null);
}
@Override
public void accept(Visitor visitor) {
super.left.accept(visitor);
visitor.visitZeroRelationExpression(this.data);
}
}
Contrairement aux autres classes XxxExpression, la classe ZeroRelationalExpression a deux constructeurs, dont aucun ne permet pas d’attribuer une valeur à l’enfant de droite, qui dans le cas présent sera toujours égal null (représentant zéro) et n’aura pas besoin d’être visité puisque nous ne souhaitons pas générer d’instruction associée.
De plus, pour que la classe Compiler puisse faire la distinction entre la visite d’un opérateur relation de la classe ZeroRelationalExpression et RelationalExpression nous avons remplacé la méthode visit(RelationalOperator operator) par deux nouvelles :
void visitRelationExpression(RelationalOperator expression);
void visitZeroRelationExpression(RelationalOperator expression);
La méthode accept() de la classe RelationalExpression ayant été modifiée pour prendre en compte le changement :
public class RelationalExpression extends Node<RelationalOperator> {
// ...
@Override
public void accept(Visitor visitor) {
super.left.accept(visitor);
super.right.accept(visitor);
visitor.visitRelationExpression(this.data);
}
}
Il ne nous reste plus qu’à implémenter les quatre nouvelles méthodes dans la classe Compiler.
public class Compiler implements Visitor {
final private Set<String> usedLabels;
final private Stack<String> andLabels;
final private Stack<String> orLabels;
final private Stack<LogicalOperator> logicalOperators;
// ...
}
Nous avons tout d’abord ajouté les trois piles dont nous avions déjà discuté, mais aussi une liste des labels utilisés, ou plus précisément des labels utilisés en argument d’une instruction. Puisque nous n’avons pas encore abordé la question du placement du label de débranchement (le label suivi du deux-points en PJB et qui précède le bloc de débranchement), il s’agit d’un point important mais très simple à prendre en compte.
Voyons ensuite les deux premières méthodes.
@Override
public void visitBeforeLeft(String name, LogicalOperator operator) {
this.logicalOperators.push(operator);
if (operator == LogicalOperator.AND) {
this.andLabels.push(name);
} else {
this.orLabels.push(name);
}
}
@Override
public void visitAfterLeft(String name, LogicalOperator operator) {
this.logicalOperators.pop();
if (operator == LogicalOperator.AND) {
this.andLabels.pop();
} else if (operator == LogicalOperator.OR) {
this.orLabels.pop();
}
if (this.usedLabels.remove(name)) {
this.writeLabel(name);
}
}
private void writeLabel(String label) {
this.bytecode.append(label).append(":\n");
}
La méthode visitBeforeLeft(), ne fait qu’ajouter des éléments aux trois piles, et la méthode visitAfterLeft() les retire.
De plus, la méthode visitAfterLeft() contient le mécanisme permettant de générer les labels de débranchement. Nous savons que le prochain nœud que nous allons visité est un enfant de droite, et si le nom de son nœud parent a été utilisé, ceci signifie qu’il y a un débranchement vers le code constitué de l’ensemble d’un sous-arbre dont l’enfant de droite est le nœud racine.
@Override
public void visitRelationExpression(RelationalOperator operator) {
final RelationalParams params = this.getRelationalParams(operator);
String instruction = null;
// switch/case permettant de récupérer l'instruction
// associée à l'opérateur
this.bytecode.append(instruction).append(" ")
.append(params.label).append("\n");
}
@Override
public void visitZeroRelationExpression(RelationalOperator operator) {
final RelationalParams params = this.getRelationalParams(operator);
String instruction = null;
// switch/case permettant de récupérer l'instruction
// associée à l'opérateur
this.bytecode.append(instruction).append(" ")
.append(params.label).append("\n");
}
Les méthodes visitRelationExpression() et visitZeroRelationExpression() génèrent les instructions de comparaison avec leur argument, mais délègue leur gestion à une méthode getRelationalParams() qui contient la version Java du résumé des trois règles énoncées en début de la partie en cours (implémentation).
private RelationalParams getRelationalParams(RelationalOperator operator) {
RelationalOperator relationalOperator = null;
String label = null;
if (this.logicalOperators.isEmpty()) {
relationalOperator = operator.inverse();
label = "ko";
} else if (this.logicalOperators.peek() == LogicalOperator.AND) {
label = !this.orLabels.isEmpty() ? this.orLabels.peek() : "ko";
relationalOperator = operator.inverse();
} else if (this.logicalOperators.peek() == LogicalOperator.OR) {
label = !this.andLabels.isEmpty() ? this.andLabels.peek() : "ok";
relationalOperator = operator;
} else {
throw new RuntimeException("Don't know what to do!");
}
this.usedLabels.add(label);
return new RelationalParams(relationalOperator, label);
}
private class RelationalParams {
final RelationalOperator operator;
final String label;
public RelationalParams(RelationalOperator operator, String label) {
super();
this.operator = operator;
this.label = label;
}
}
La méthode getRelationalParams() ajoute aussi le label qui sera utilisé avec l’instruction à la liste usedLabels.
Ceci conclut l’implémentation de notre classe Compiler.
Nous pouvons tester l’ensemble de ce code en prenant un exemple un peu complexe.
@Test
public void mixed3() {
// ((a || b) && (c && (d || e))) || (f || (g && h))
final Expression e =
new LogicalExpression("or1",
new LogicalExpression("and1",
new LogicalExpression("or2",
new ZeroRelationalExpression(new IntVariable(0)),
LogicalOperator.OR,
new ZeroRelationalExpression(new IntVariable(1))
),
LogicalOperator.AND,
new LogicalExpression("and2",
new ZeroRelationalExpression(new IntVariable(2)),
LogicalOperator.AND,
new LogicalExpression("or3",
new ZeroRelationalExpression(new IntVariable(3)),
LogicalOperator.OR,
new ZeroRelationalExpression(new IntVariable(4))
)
)
),
LogicalOperator.OR,
new LogicalExpression("or4",
new ZeroRelationalExpression(new IntVariable(5)),
LogicalOperator.OR,
new LogicalExpression("and3",
new ZeroRelationalExpression(new IntVariable(6)),
LogicalOperator.AND,
new ZeroRelationalExpression(new IntVariable(7))
)
)
);
final Compiler compiler = new Compiler(e);
Assert.assertEquals("iload 0\n"
+ "ifne and1\n"
+ "iload 1\n"
+ "ifeq or1\n"
+ "and1:\n"
+ "iload 2\n"
+ "ifeq or1\n"
+ "iload 3\n"
+ "ifne ok\n"
+ "iload 4\n"
+ "ifne ok\n"
+ "or1:\n"
+ "iload 5\n"
+ "ifne ok\n"
+ "iload 6\n"
+ "ifeq ko\n"
+ "iload 7\n"
+ "ifeq ko\n",
compiler.compile());
}
Les autres tests unitaires sont disponibles dans la classe CompilerTest.
L’opérateur unaire NOT
Au cours de cet article, nous n’avons pas vu d’exemple utilisant l’opérateur unaire NOT (!) car il n’existe pas en bytecode, et contrairement aux opérateurs AND (&&) et OR (||) sa gestion ne revient pas au compilateur mais à l’analyseur syntaxique.
Voyons ceci sommairement. Si l’opérateur NOT s’applique à une expression relationnelle, il suffit de prendre l’opérateur inverse pour que l’on puisse l’enlever au même titre que les parenthèses :
L'expression !(a < b) est égale à a >= b
L'expression !(a != b)) est égale à a == b
Lorsque l’opérateur NOT s’applique à une expression logique contenant l’opérateur AND et/ou OR, il est nécessaire d’appliquer les lois de De Morgan qui sont les suivantes :
La négation d’une conjonction (
AND) est la disjonction des négations
La négation d’une disjonction (OR) est la conjonction des négations
Ce qui donne en pseudo-code :
!(a && b) == !a || !b
!(a || b) == !a && !b
Notons que ces règles sont applicables quel que soit le nombre d’opérandes et lorsque les opérateurs AND et OR sont de priorités équivalentes. En d’autres termes !(a && b || c) == !a || !b && !c pour un langage tel que Smalltalk, en revanche en Java il est nécessaire de forcer la priorité à l’aide de parenthèses :
!(a && b || c) == (!a || !b) && !c
What’s next ?
Dans l’article suivant nous nous intéresserons à l’implémentation de toutes les instructions que nous avons vues dans les deux articles précédents.