
ElasticSearch
ElasticSearch est un moteur de recherche libre (open source) d’architecture REST (REpresentational State Transfer) basé sur Apache Lucene. Il permet l’indexation de données sous forme de documents, leur recherche et une analyse de ces données en temps réel.
Voici donc le compte-rendu d’une présentation de cette petite merveille faite par David Pilato chez Soat.
Concepts en quelques mots
Pour commencer, voici une présentation rapide des différents concepts et principes clefs d’ElasticSearch.
Données et analyse en temps réel 

Dans le monde réel, les données peuvent être intégrées dans un système d’information à tout moment. La question importante du coté métier étant : “À partir de quand ces données peuvent elles être utilisées ?” Avec ElasticSearch, la réponse est : “immédiatement” !
Orienté “document” (au sens NoSQL du terme), toutes les données sont stockées sous forme de documents JSON structurés. Tous les champs sont indexés par défaut, et tous les index peuvent être utilisés dans une même requête, pour retourner les résultats correspondant à une recherche à une vitesse impressionnante.
Liberté de la structure des documents
Aucun format de document n’est imposé. Lors de l’ajout d’un document JSON, ElasticSearch va détecter la structure de données, indexer ces données et les rendre consultables. Ensuite, suivant les spécificités du domaine d’utilisation, il sera intéressant de structurer fonctionnellement ces documents pour personnaliser la façon dont ces données seront indexées. Après tout, l’un des slogans d’ElasticSearch est : “Your Data, your search”
Sécurisation des données
 Il y a une persistance des données par opération, les modifications apportées à un document sont loguées sur différents nœuds du cluster pour minimiser les risques de perte de données. De plus les clusters ElasticSearch sont résilients, ils détectent et suppriment les nœuds défaillants et se réorganisent pour assurer que les données restent sécurisées et accessibles. Une gestion des conflits peut aussi être utilisée (via un contrôle de version) pour s’assurer que les données ne sont jamais perdues en raison de changements contradictoires de plusieurs processus.
Il y a une persistance des données par opération, les modifications apportées à un document sont loguées sur différents nœuds du cluster pour minimiser les risques de perte de données. De plus les clusters ElasticSearch sont résilients, ils détectent et suppriment les nœuds défaillants et se réorganisent pour assurer que les données restent sécurisées et accessibles. Une gestion des conflits peut aussi être utilisée (via un contrôle de version) pour s’assurer que les données ne sont jamais perdues en raison de changements contradictoires de plusieurs processus.
Modulable et extensible
L’architecture distribuée permet de commencer petit, et de grandir en fonction des besoins. Il suffit pour cela de rajouter de nouveaux nœuds, et de laisser le cluster se réorganiser tout seul pour profiter des ressources matérielles supplémentaires. Un cluster peut héberger plusieurs ensembles d’index qui peuvent être interrogés de manière indépendante ou en tant que groupe. Un système d’alias permet d’ajouter des index à la volée, tout en étant transparent pour les applications clientes.
Open source, facile à connecter, construit à partir d’Apache Lucene ™
Apache Lucene est une librairie écrite en JAVA, performante et riche en fonctionnalités. Presque toute action sur ElasticSearch peut être réalisée en utilisant une API RESTful basique utilisant JSON via HTTP. ElasticSearch peut être téléchargé, utilisé et modifié gratuitement : il est disponible sous la licence Apache 2, l’une des licences open source les plus flexibles disponibles.
Recherche en texte intégral 

ElasticSearch utilise Apache Lucene, le meilleur moteur de recherche de texte intégral sur le marché de l’open-source. Il dispose donc d’un support multi langues, d’un puissant langage de requêtes, d’un support de géolocalisation, de la proposition de suggestion de saisie et d’autocomplétion et de snippets de recherche.
Un moteur de recherche
La qualité d’une recherche est évaluée par le positionnement et la pertinence des résultats. Cependant, d’autres facteurs entrent en compte dans une recherche. La rapidité est un facteur déterminant pour traiter une vaste quantité d’informations. De même, pouvoir supporter des requêtes simples ou complexes, des interrogations de phrases, les résultats de positionnement et de tri sont aussi importants qu’une syntaxe facile à prendre en main pour saisir ces requêtes.
La recherche via les moyens habituels
En général, la recherche de données se fait via un formulaire de recherche dans lequel l’utilisateur aura accès à différents champs lui permettant de cibler sa recherche. Ces critères seront ensuite utilisés pour retrouver les données au sein d’une base de données relationnelle. Par exemple, dans le cas de la recherche d’un contact dans un répertoire téléphonique, on aurait :
- un champ nom ;
- un champ prénom ;
- un champ numéro de téléphone ;
- voir même des champs tels que deuxième prénom, nom de jeune fille, …
Ce qui conduirait, dans une requête relationnelle SQL, à un code devant interroger différents champs d’une table, gérer les champs renseignés “à moitié”, gérer les champs vides, etc… entraînant à partir d’une certaine volumétrie une dégradation des performances.
Mais surtout cela oblige l’utilisateur à connaitre exactement dans quel champ doit se trouver telle donnée : le contact “Juju” doit-il être recherché dans le champ prénom, nom, pseudonyme, ou autre ?
La recherche via ElasticSearch
De son côté, ElasticSearch propose une recherche en mode “moteur de recherche” où il n’est désormais plus besoin que d’une unique zone de saisie cherchant tous les éléments correspondant à la recherche. Il n’est donc plus nécessaire de savoir exactement l’architecture interne des enregistrements, il suffit simplement de saisir les informations à trouver.
Qui plus est, ceci se fait en temps réel, car dès qu’un document est indexé, il est disponible à la recherche.
Un moteur d’indexation
Afin d’assurer une recherche facile et efficace, il existe une étape primordiale : l’indexation. Jusqu’à l’explosion d’internet, la classification décimale de Dewey (cf. Ressources) était très efficace pour catégoriser des objets dans une bibliothèque. Suite à l’explosion du nombre de données collectées, il a fallu trouver d’autres moyens plus rapides et dynamiques pour rechercher des informations.
C’est pourquoi, au cœur des moteurs de recherche se trouve un système d’indexation automatique qui permet, en ne traitant qu’une seule fois les données brutes, de leur donner de multiples liens efficients. Il n’est alors plus besoin de parcourir chaque document lors de la recherche d’un terme spécifique, il suffit d’aller interroger la table d’index. Ce concept correspond en quelque sorte à l’index terminologique généralement présent à la fin d’une encyclopédie et renvoyant aux différents articles de celle-ci.
Injection des données : la River

L’injection de données dans ElasticSearch se fait à l’aide d’une river (rivière). Une river est un service pluggable permettant de déverser (d’où son nom ;o)) en continu dans ElasticSearch des documents qui seront ensuite indexés dans le cluster. Une river est composée d’un nom unique et d’un type (à noter que plusieurs rivers du même type, mais de noms différents, peuvent être lancées au sein d’un même cluster). Les rivers sont des singletons dans le cluster, elles sont allouées automatiquement à un nœud et lancées ; si ce dit-nœud tombe, la river est automatiquement réaffectée à un autre nœud.
Analyse des données pour indexation
Lors du déversement des documents dans ElasticSearch, ils sont analysés par un “Analyzer“. Celui ci est composé de 2 éléments principaux : le tokenizer et le filtre, fonctionnant de pair. Le Tokenizer se charge de découper les différents éléments d’une chaîne en tokens. Le Filtre, quant à lui, se charge de supprimer ou de transformer ces tokens. En fonction des besoins, ceux ci pourront se trouver cumulés afin d’offrir la meilleurs gestion possible des données de chaque application cliente et de ses utilisateurs. En voici quelques exemples :
- whitespace tokenizer : très basique, il va séparer les tokens à chaque espace trouvé

- standard tokenizer : ne va prendre en compte ni les articles (pour éviter de polluer les index avec des valeurs non pertinentes), ni la ponctuation, ni la casse (ainsi, que l’utilisateur recherche “DOG” ou “dog”, il obtiendra les mêmes résultats)
- asciifolding filter
- stemmer filter (french) : permet de regrouper les termes français ayant une même racine sur un même index (ainsi, l’utilisateur n’a pas besoin de réfléchir aux notions de genre ou de nombre dans ses recherches)
- phonetic (plugin) : gestion phonétique permettant, par exemple, de ne pas tenir compte des erreurs d’orthographe lors d’une recherche
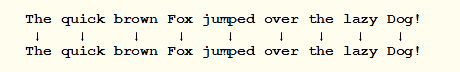
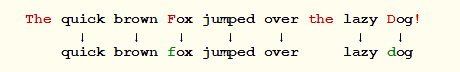



ElasticSearch : Aller plus loin dans la recherche
Rechercher des données dans des documents parfaitement indexés, c’est bien ! Mais maintenant il serait bon de pouvoir facilement jouer avec ces données pour les faire parler…
Analyse des données : la puissance des Facet
Le principal objectif d’un moteur de recherche “full-text” est de retourner un nombre limité de documents répondant à une requête. Les facettes (Facet) fournissent des agrégats sur les résultats d’une recherche. A partir de ces facettes, l’utilisateur peut alors affiner sa recherche en ayant un visuel sur les résultats qui seront ramenés, plutôt que de le faire à l’aveugle…
Les différentes facettes disponibles sont :
- Terms : permet de retourner les termes les plus fréquents ;
- Range : permet de spécifier des intervalles de données ;
- Geo Distance : permet de fournir les données correspondant à un intervalle de distance géographique ;
- Histogram : fonctionne avec des données numériques par la construction d’un histogramme à travers les intervalles des valeurs du champ ;
- Date Histogram : une histogram facet spécifique fonctionnant sur des champs date ;
- Filter : permet de retourner un nombre de hits correspondant un filtre ;
- Query : permet de retourner un nombre de hits correspondant une requête ;
- Statistical : permet de calculer des données statistiques sur un champ numérique. Les données statistiques incluent le décompte, le total, la somme des carrés, la moyenne, le minimum, le maximum, la variance et l’écart type ;
- Terms Stats : combine à la fois les facettes term et statistical.
La recherche inversée : la Percolation
En général, dans un moteur de recherche, l’utilisateur lance une recherche, obtient ses résultats, et si de nouvelles données pertinentes arrivent entre-temps dans le système, il lui faut relancer la recherche pour voir les-dites données. Avec ElasticSearch, il n’est plus besoin à l’utilisateur de s’enquérir de l’arrivée de ces nouvelles données, elles lui sont directement remontées sans action de sa part.
Afin de réaliser ce “miracle”, on a simplement un “listener” (ceux du monde Java ne seront pas perdus) sur le moteur d’indexation : le Percolateur ! A chaque nouvel ajout de document, le percolateur vérifie si celui-ci correspond aux critères de la recherche enregistrée, et renvoie au besoin les données au moteur de recherche pour que soient mis à jours les résultats et facettes.
Architecture
Il est maintenant temps d’aller faire un petit tour sous le capot pour comprendre comment ElasticSearch est construit. Et avant tout, pour éviter d’être perdu, quelques termes lexicaux :
- Nœud (node) : une instance d’ElasticSearch
- Cluster : un ensemble de nœuds
- Partition (shard) : une instance de Lucène permettant de découper un index en plusieurs parties pour y distribuer les documents
- Réplication (replica) : recopie d’un shard en une ou plusieurs copies dans l’ensemble du cluster
Réplication
Afin d’assurer une pérennité des données, à partir du moment où il existe 2 nœuds, l’un sert de réplication à l’autre. Ainsi, si l’un tombe, les données ne sont pas perdues. Il n’y a pas de limite au nombre de réplica. Plus il y a d’utilisateurs, plus il peut être intéressant d’avoir des réplicas (recherche distribuée).

Réallocation dynamique
Lors du rajout de nœuds, les shards sont ré-alloués dynamiquement. Un bon tuning consistant à trouver le bon équilibre entre le nombre de nœuds, shards et réplicas pour satisfaire au mieux aux besoins fonctionnels.
{kind=link}
Indexation
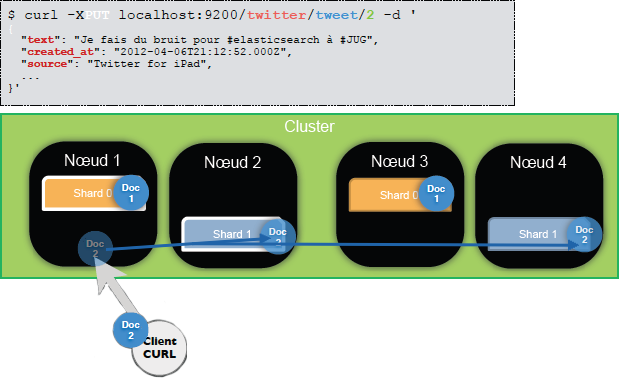
Lors de l’indexation d’un document, celui-ci est envoyé au nœud principal, puis est automatiquement alloué à un shard et répliqué.
Recherche
Lors d’une recherche, on va interroger le nœud principal qui va renvoyer la recherche aux autres nœuds de façon distribuée (recherche sur les nœuds originaux ou sur leur réplica, en fonction de la charge), et les documents correspondants seront renvoyés au client.

Quelques exemples d’utilisation
Voici à présent quelques exemples d’utilisation d’ElasticSearch, afin de pouvoir mieux se rendre compte en pratique des différents points théoriques abordés précédemment.
Scrut my docs
Tout d’abord, un exemple du site Scrutmydocs.org où l’on peut voir que le terme “notice” a été trouvé 6 fois sur 2 documents différents :
- une fois dans le titre d’un de ces documents
- les autres fois dans le corps du texte

The one million tweet map
Et à présent, le site onemilliontweetmap.com où l’on peut voir à l’oeuvre de nombreux points abordés jusqu’ici tel que Term Facet, Range Facet, Geo distance Facet, Percolation, etc… Dans le cas présent, on cherchait le “soleil” dans les tweets (il paraît que c’est de saison… ;o))

Ressources
Et enfin, pour ceux qui souhaitent en savoir plus, voici quelques liens intéressants :
- “One Million Tweet Map”
- “Scrut My Docs”
- elasticsearch.org
- elasticsearch.com
- ElasticSearch par Wikipedia
- ElasticSearch : moteur de recherche taillé pour le Cloud
- Exemple d’une API fonctionnant avec ElasticSearch
- La classification décimale de Dewey
- Lucene par Wikipedia
- Vidéo de présentation de l’architecture distribuée
© SOAT
Toute reproduction interdite sans autorisation de la société SOAT