
Windows Azure Table Storage 2.0 : Qu’est-ce qui a changé ?
![]() Lors de la dernière mise à jour du SDK Windows Azure, à savoir le passage à la version 1.8 courant octobre 2012, un grand nombre de nouveautés sont arrivées avec ce dernier. Cependant à mon avis, la plus grande nouveauté de celui-ci est le passage en 2.0 de la librairie pour gérer le storage Windows Azure. Dans cet article, nous allons avant tout faire un retour sur ce qu’est le Table Storage, puis nous allons regarder les différentes évolutions qu’il y a eu sur le Table Storage et nous allons voir comment développer avec ce dernier.
Lors de la dernière mise à jour du SDK Windows Azure, à savoir le passage à la version 1.8 courant octobre 2012, un grand nombre de nouveautés sont arrivées avec ce dernier. Cependant à mon avis, la plus grande nouveauté de celui-ci est le passage en 2.0 de la librairie pour gérer le storage Windows Azure. Dans cet article, nous allons avant tout faire un retour sur ce qu’est le Table Storage, puis nous allons regarder les différentes évolutions qu’il y a eu sur le Table Storage et nous allons voir comment développer avec ce dernier.
Qu’est-ce que le Windows Azure Table Storage ?
Le table storage est un système de stockage qui existe sur Windows Azure depuis les débuts de la plateforme, même si ce dernier a porté divers noms au fil des années. Ce système de stockage est un système de type NoSql, ce qui nous permet de gérer des données en ligne. Pour résumer, il est possible de créer des tables, et d’y ajouter des lignes au sein de celui-ci, en respectant le fait que le couple “PartitionKey + RowKey” soit unique. Par la suite les données sont séparées via des “Partitions”, nous aurons donc des requêtes très rapides lorsque l’on recherche des données via sa PartitionKey. On dit souvent que ce système de stockage est parfait pour stocker des données comme des logs, mais il est possible de l’utiliser dans d’autres cas ! Par exemple, je cite l’application Movie Battle que nous avons développé avec la team Soat Experts.
Pour information, à ce jour, le Table Storage est énormément utilisé, vu qu’on peut recenser 4 Trillions d’objets au mois de juin 2012 comme le montre cet article sur MSDN. Pour le calcul rapide, cela correspond à 4 milliards de millards, cela fait donc une bonne utilisation de dernier.
Plusieurs versions qui co-existent ?
Comme je l’ai précisé en introduction, lors de la dernière mise à jour du SDK , une version 2.0 du Storage est arrivée, avant celle-ci, on en était à la version 1.7 de la librairie. La dernière mise à jour apporte de nombreuses modifications, notamment un changement total de l’utilisation de l’API, cependant la librarie apporte deux façon différentes d’utiliser le Table Storage, celle que que j’appelle la version 1.8 qui reprend les principes de l’ancien SDK, et une nouvelle façon qui selon moi est plus claire et qui induit beaucoup moins les développeurs en erreur; de plus cette version apporte certains concepts supplémentaires qui peuvent être fortement utiles pendant les développement. Nous avons dons maintenant en 2 assemblages, 3 façons différentes d’utiliser le Table Storage, on va donc voir les 3, et cela sera à vous de choisir celle que vous préférez.
Etape 0 : Référencer les bonnes assemblies
Il existe donc deux librairies différentes, la première que vous pouvez retrouver au sein de Visual Studio lorsque vous installez le SDK 1.7. Pour rappel, le chemin de cette dernière est “C:\Program Files\Microsoft SDKs\Windows Azure.NET SDK\2012-10\ref\Microsoft.WindowsAzure.StorageClient.dll”
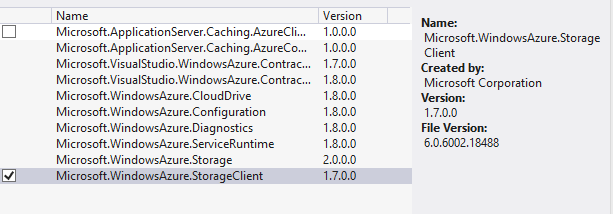
Et pour les deux autres versions, vous allez pouvoir utiliser votre utilitaire de package préféré, j’ai nommé NuGet en recherchant WindowsAzure.Storage
![]()
On peut notamment voir que nous sommes en version 2.0.4.0, et donc que l’équipe chargée du Storage chez Microsoft continue de fournir des évolutions sur sa librairie sans qu’un SDK soit redistribué publiquement.
Bien entendu, vu que c’est une librairie sur Windows Azure, elle est disponible sur GitHub, et donc vous pouvez voir comment elle est conçue.
Etape 1 : Déclarer nos entités
On va donc commencer par créer des classes qui vont gérer le mapping entre notre Table Storage et nos objets. A noter qu’il est possible d’avoir des classes qui ne contiennent pas toutes les colonnes présentes dans la Table cible et vice-versa.
Commençons par le SDK 1.7 :
public class TestEntity : Microsoft.WindowsAzure.StorageClient.TableServiceEntity
{
public string Text { get; set; }
public DateTime Date { get; set; }
public int Integer { get; set; }
public bool IsEnabled { get; set; }
public Guid UniqueIdentifier { get; set; }
public long LongValue { get; set; }
}
On voit donc qu’il faut faire hériter notre entité de la classe TableServiceEntity qui est abstraite et qui contient les champs PartitionKey, RowKey et TimeStamp par défaut. Les deux premiers sont des propriétés de type string et virtuelle, quand au dernier il s’agit d’une date comme son nom l’indique.
Passons maintenant au SDK 1.8 :
public class TestEntity : Microsoft.WindowsAzure.Storage.Table.DataServices.TableServiceEntity
{
public string Text { get; set; }
public DateTime Date { get; set; }
public int Integer { get; set; }
public bool IsEnabled { get; set; }
public Guid UniqueIdentifier { get; set; }
public long LongValue { get; set; }
}
Comme on peut le voir dans cette version, nous avons exactement la même chose que dans la précédente sauf que le namespace de TableServiceEntity a changé.
Et maintenant, la nouvelle version :
public class TestEntity : Microsoft.WindowsAzure.Storage.Table.TableEntity
{
public string Text { get; set; }
public DateTime Date { get; set; }
public int Integer { get; set; }
public bool IsEnabled { get; set; }
public Guid UniqueIdentifier { get; set; }
public long LongValue { get; set; }
}
Dans celle-ci, il y a beaucoup plus de modifications, notamment la classe dont on hérite est maintenant TableEntity, elle n’est plus abstraite, et elle contient les propriétés PartitionKey, RowKey, Timestamp et ETag. Les deux premières propriétés ne sont plus virtuelles, le Timestamp est maintenant de type DateTimeOffSet, et la propriété ETag peut maintenant être renseigné via cette entité. Cette classe contient aussi des méthodes que l’on peut surchargées, mais cela fera l’objet d’un autre article.
Etape 2 : Se connecter au Windows Azure Table Storage
Maintenant qu’on sait comment schématiser nos tables au niveau de notre application, voyons comment nous connecter au Table Storage. Pour cela, on va utiliser la classe CloudStorageAccount, mais comme vous allez le voir, il y a encore des différences entre les différents SDKs.
Commençons avec le SDK 1.7
public void Connect()
{
// From development environment
var csa = Microsoft.WindowsAzure.CloudStorageAccount.DevelopmentStorageAccount;
// With a StorageCredentialsAccountAndKey
var csa2 = new Microsoft.WindowsAzure.CloudStorageAccount(new StorageCredentialsAccountAndKey("MyAccountName", "MyAccountKey"), true);
// Parse a connection string
var csa3 = Microsoft.WindowsAzure.CloudStorageAccount.Parse("DefaultEndpointsProtocol=https;AccountName=ACCOUNTNAME;AccountKey=ACCOUNTKEY");
}
On voit donc qu’il y a différents moyens de créer un CloudStorageAccount en C#, pour ma part j’utilisais au plus possible la deuxième méthode, car je la trouve plus simple à relire, et pour extraire les informations de connexion.
Maintenant avec le SDK 1.8 :
public void Connect()
{
// From development environment
var csa = Microsoft.WindowsAzure.Storage.CloudStorageAccount.DevelopmentStorageAccount;
// With a StorageCredentialsAccountAndKey
var csa2 = new Microsoft.WindowsAzure.Storage.CloudStorageAccount(new Microsoft.WindowsAzure.Storage.Auth.StorageCredentials("MyAccountName", "MyAccountKey"), true);
// Parse a connection string
var csa3 = Microsoft.WindowsAzure.Storage.CloudStorageAccount.Parse("DefaultEndpointsProtocol=https;AccountName=ACCOUNTNAME;AccountKey=ACCOUNTKEY");
}
On peut donc voir qu’il y a peu de changement à part les namespaces, et le fait que la classe StorageCredentialsAccountAndKey a été renommée pour changer son nom à rallonge ! Bonne nouvelle pour la V2, c’est la même chose que cette version.
Etape 3 : Créer des tables
Bon maintenant que nous avons le schéma de nos tables, et que nous savons comment initialiser notre chaîne, il est temps de créer les tables où nous allons stocker nos données. Cette fois encore, nous allons pouvoir y voir des modifications entre les différentes versions, mais rien de bien majeur.
En 1.7, il faut avant tout créer un contexte pour effectuer n’importe quelle action, nous allons voir que cela ressemble beaucoup à un DataServiceContext, et cela est normal puisque notre classe TableServiceContext hérite de cette dernière !
public class ServiceContext : Microsoft.WindowsAzure.StorageClient.TableServiceContext
{
private readonly Microsoft.WindowsAzure.CloudStorageAccount _storageAccount;
public ServiceContext(Microsoft.WindowsAzure.CloudStorageAccount storageAccount)
: base(storageAccount.TableEndpoint.ToString(), storageAccount.Credentials)
{
_storageAccount = storageAccount;
CreateTables();
}
private void CreateTables()
{
var tableClient = _storageAccount.CreateCloudTableClient();
tableClient.CreateTableIfNotExist("NameOfMyTable");
// Or with an async mode
Task.Factory.FromAsync(tableClient.BeginCreateTableIfNotExist,
iar => tableClient.EndCreateTableIfNotExist(iar),
"NameOfMyTable2", null);
}
}
On peut donc voir qu’il faut commencer par créer un ServiceContext, et pour cela il nous suffit d’avoir une instance d’un CloudStorageAccount afin de pouvoir en extraire l’url de notre service, et les différentes informations d’identifications. Par la suite, il est possible de créer notre table soit de manière synchrone, soit de manière asynchrone. A noter qu’il est possible de créer notre table si elle n’existe pas, il est possible d’utiliser uniquement la méthode CreateTable mais celle-ci nous renvoie une erreur si la table existe déjà.
Passons maintenant à la 1.8, vu que celle-ci est une version hybride, nous avons deux versions différentes pour créer nos tables, néanmoins si vous comptez l’utiliser après une migration, je vous conseille d’utiliser la méthode à l’ancienne.
On va donc commencer par la version “à l’ancienne”
public class ServiceContext : Microsoft.WindowsAzure.Storage.Table.DataServices.TableServiceContext
{
public ServiceContext(Microsoft.WindowsAzure.Storage.CloudStorageAccount storageAccount)
: base(storageAccount.CreateCloudTableClient())
{
var tableClient = storageAccount.CreateCloudTableClient();
var table = tableClient.GetTableReference("TableName");
table.CreateIfNotExists();
//or with an async pattern
Task.Factory.FromAsync(table.BeginCreateIfNotExists, iar => table.EndCreateIfNotExists(iar), null);
}
}
La premère modification que l’on peut, et que l’on ne passe plus par le TableClient pour créer nos tables, mais via une instance de CloudTable, ce qui selon moi précise le fait que l’on travaille sur une table spécifique et non l’ensemble des tables. De plus, on peut voir qu’il y a des changements de namespaces, et des noms de méthodes qui sont beaucoup plus simples, ils ont surtout renommé les méthodes selon ce pattern : CreateTableIfNotExists -> CreateIfNotExists. Et l’on peut voir aussi que le constructeur de TableServiceContext a été simplifié et qu’il ne lui faut que le TableClient comme paramètre. De plus, la classe TableServiceContext est maintenant Disposable, car ce n’était pas le cas avant, et cela pouvait poser des problèmes en mémoire. Ce problème est maintenant résolu.
Et maintenant, voyons la deuxième solution pour le SDK 1.8, qui marche exactement de la même façon pour le SDK 2.0
public void CreateTables()
{
var tableClient = _storageAccount.CreateCloudTableClient();
var table = tableClient.GetTableReference("TableName");
table.CreateIfNotExists();
// Or with an async pattern
Task.Factory.FromAsync(table.BeginCreateIfNotExists, iar => table.EndCreateIfNotExists(iar), null);
}
On peut donc voir que cette méthode est beaucoup plus simple, et moins verbeuse que la précédente, et selon simplifie la lecture du code.
Autre nouveauté, que je vous conseille d’utiliser lorsque vous utilisez cette méthode est la RetryPolicy, elle est simple à mettre en place, et cela vous permet d’ajouter une sécurité à votre code en cas de non réponse de la plateforme. Ou par exemple de votre émulateur que vous avez oublié d’allumer (ce qui m’arrive très souvent)
var table2 = tableClient.GetTableReference("NameOfMyTable");
table2.CreateIfNotExists(new Microsoft.WindowsAzure.Storage.Table.TableRequestOptions()
{
MaximumExecutionTime = TimeSpan.FromMinutes(5),
RetryPolicy = new ExponentialRetry(TimeSpan.FromMilliseconds(100), 10),
ServerTimeout = TimeSpan.FromMinutes(10)
});
Voilà pour la création de vos tables, je vous conseille de lancer les demandes de création avant chaque requête notamment si vous souhaitez stocker des logs. Puisqu’au bout d’un moment il est plus rapide (et moins coûteux) de supprimer une table que l’ensemble des données qu’elle contient. Pour vous donner un exemple que j’ai vécu : Vider une table de logs qui a 3 mois d’existence prend quelques heures … Supprimer la table, quelques secondes ….
Etape 4 : Insérer des données
Maintenant que nous avons pu modéliser nos tables, que nous savons nous connecter au moteur Table Storage via les différents SDK et que nous pouvons créer des tables simplement que ce soit de manière synchrone ou asynchrone. Il est maintenant temps d’insérer des données dans nos tables. Alors là encore il y a des différences entre les différentes versions du SDK, pour les versions 1.7 et 1.8, on doit passer via notre ServiceContext que nous avons créé précédemment.
Voici, un exemple de requête d’insertion simple avec le SDK 1.7 ou 1.8. Bien entendu, nous sommes dans une classe qui hérite du TableServiceContext.
public void InsertData()
{
TestEntity entityToInsert = new TestEntity()
{
Date = DateTime.Now,
Integer = 42,
IsEnabled = false,
LongValue = 42,
PartitionKey = "MyPartitionKey",
RowKey = "MyRowKeyFrom1.7",
Text = "Any Text",
UniqueIdentifier = Guid.NewGuid()
};
base.AddObject("NameOfMyTable", entityToInsert);
base.SaveChanges();
}
On peut donc voir que c’est extrêmement simple, puisqu’il s’agit de créer notre entité, en remplissant les différents champs qui nous intéresse tout en prenant compte que la PartitionKey et la RowKey sont des champs obligatoires et que le couple se doit être unique au sein de chaque table. L’essentiel est donc d’ajouter notre objet à notre table, et donc de la redéfinir à chaque fois (sous peine de faire une faute en la tapant, si vous la copier à chaque fois) et enfin de faire un Save afin de … sauvegarder. A noter qu’il existe plusieurs options comme le SaveWithRetries afin de s’affranchir d’éventuels problèmes réseaux, et de plus il est possible d’ignorer les erreurs qui sont levées lors de la sauvegarde comme par exemple l’ajout d’un doublon dans la table.
Maintenant passons à la nouvelle version du SDK, on va voir qu’il y a plusieurs changements qui peuvent fortement vous simplifier la vie comme on peut le voir.
public void InsertData()
{
TestEntity entityToInsert = new TestEntity()
{
Date = DateTime.Now,
Integer = 42,
IsEnabled = false,
LongValue = 42,
PartitionKey = "MyPartitionKey",
RowKey = "MyRowKeyFrom2.0",
Text = "Any Text",
UniqueIdentifier = Guid.NewGuid()
};
var tableClient = _storageAccount.CreateCloudTableClient();
var table = tableClient.GetTableReference("NameOfMyTable");
var insertOperation = TableOperation.Insert(entityToInsert);
//var insertOperation = TableOperation.InsertOrMerge(entityToInsert);
//var insertOperation = TableOperation.InsertOrReplace(entityToInsert);
table.Execute(insertOperation);
}
Afin de pouvoir insérer une donnée dans notre table, il faut donc récupérer la référence de la table, je vous conseille pour cela de ne pas faire comme dans mon exemple et de créer une factory pour cela. Après il est possible d’insérer nos données simplement, et même de traiter les cas d’erreurs en cas de doublon, on peut soit réalisé un Merge ou directement un Replace de nos données. Et pour finir, il suffit d’exécuter notre opération. A noter, qu’il est possible de batcher nos opérations afin de faire une seule requête pour effectuer plusieurs insertions par exemple. Bien entendu ce batch a des limites, il faut qu’il concerne moins de 100 entités et que celles-ci soient sur la même table, et qu’elles aient la même PartitionKey.
Etape 5 : Requêter nos données
Maintenant que nous avons inséré des données dans notre table, il est important de savoir les lire. Pour cette opération, il y a aussi des changements divers entre les différents SDK, et pour cette opération spécifique il s’agit de changements majeurs qui peuvent être pertubants lors de la première utilisation du nouveau storage.
Commençons donc avec le SDK 1.7, il était possible de faire des requêtes via notre ServiceContext que nous avons créer précédemment.
Avant de réaliser la moindre requête, il fallait créer un objet pour effectuer des requêtes comme cela :
public IQueryable Entities
{
get
{
return base.CreateQuery("NameOfMyTable");
}
}
Cet objet est donc de la forme IQueryable<T> qui je ne doute pas doit vous rappeler quelques notions de Linq … Et oui, il est possible de faire du Linq via cette version du Table Storage. Et c’est donc à partir de là que commence les problèmes, car en effet on voit les différentes méthodes de Linq qui sont disponibles dans notre intellisense, mais quasiment aucune n’est supportée; Il n’y a que From, Where, Take (avec une valeur maximale de 1000), First, FirstOrDefault, Select autant dire quasiment rien par rapport au nombre total de méthode.
Voici donc quelques manières de requêter des éléments au sein du Table Storage.
// Get an entity with this PartitionKey and this RowKey
var queryWithPKAndRK = from n in Entities
where n.PartitionKey == "MyPartitionKey" && n.RowKey == "MyRowKeyFrom1.7"
select n;
// Get entities with a specific Partition Key
var queryWithPK = from n in Entities
where n.PartitionKey == "MyPartitionKey"
select n;
// Get all entities in the table, max return entities = 1000
var queryAllTable = from n in Entities
select n;
// Get top 10 entities in selected table
var queryWithTake = (from n in Entities
select n).Take(10);
// Get all entities in the table without take limit.
var queryMoreThan1KEntity = (from n in Entities
select n).AsTableServiceQuery();
Et maintenant si l’on souhaite faire de la pagination lors de l’exécution de nos requêtes par exemple pour créer un explorateur de Storage, il faut pour cela utiliser l’objet ContinuationToken comme on peut le voir ci-dessous, même si dans cet exemple je requête l’intégralité de la table :
Microsoft.WindowsAzure.StorageClient.ResultContinuation token = null;
List<TestEntity> results = new List<TestEntity>();
do
{
Microsoft.WindowsAzure.StorageClient.CloudTableQuery query = Entities.AsTableServiceQuery();
query.BeginExecuteSegmented(token, cb =>
{
var result = query.EndExecuteSegmented(cb);
token = result.ContinuationToken;
results.AddRange(result.Results);
}, null);
} while (token != null);
Pour la version 1.8, il y a extrêmement peu de changement, à part 2/3 namespaces qui changent mais rien de bien impactant, donc je vous laisse découvrir les modifications seuls ! Enfin Visual Studio devrait amplement vous aider là dessus !
Et maintenant voyons comment on fait avec le SDK 2.0, et là le nombre de différence n’est pas négligeable ! Premièrement, ils ont enlevé la syntaxe Linq que l’on avait avant et qui selon moi offrait trop de possibilité de faire du grand n’importe quoi avec le Storage, et donc pouvait faire perdre du temps lors des développements, et pire encore dégrader fortement les performances de nos requêtes. Bon passons maintenant à l’implémentation, afin que ce soit plus clair au niveau des changements.
var csa = CloudStorageAccount.DevelopmentStorageAccount;
var tableClient = csa.CreateCloudTableClient();
var table = tableClient.GetTableReference("NameOfMyTable");
// Get an entity with this PartitionKey and this RowKey
Microsoft.WindowsAzure.Storage.Table.TableOperation retrieveOperation =
TableOperation.Retrieve<TestEntity>("MyPartitionKey", "MyRowKeyFrom2.0");
TestEntity resultWithPKAndRK = table.Execute(retrieveOperation).Result as TestEntity;
// Get entities with a specific Partition Key
Microsoft.WindowsAzure.Storage.Table.TableQuery<TestEntity> queryWithPK =
new TableQuery<TestEntity>().Where(TableQuery.GenerateFilterCondition("PartitionKey", QueryComparisons.Equal, "MyPartitionKey"));
List<TestEntity> resultsWithPK = table.ExecuteQuery(queryWithPK).ToList();
// Get all entities in the table
Microsoft.WindowsAzure.Storage.Table.TableQuery<TestEntity> queryAllTable =
new TableQuery<TestEntity>();
List<TestEntity> resultsAllTable = table.ExecuteQuery(queryAllTable).ToList();
// Get top 10 entities in selected table
Microsoft.WindowsAzure.Storage.Table.TableQuery<TestEntity> queryWithTake =
new TableQuery<TestEntity>().Take(10);
List<TestEntity> resultsWithTake = table.ExecuteQuery(queryWithTake).ToList();
Et voilà, on peut voir qu’il y a beaucoup de changement, dont le premier qui n’est pas visible au premier coup d’oeil, l’exécution des requêtes n’est pas différé ! Vu que là on demande explicitement d’effectuer cette dernière. De plus, il existe une méthode pour retrouver un objet directement via sa PartitionKey et sa RowKey sans avoir à spécifier une requête. Le Seul bémol à mon avis est la nouvelle méthode Where qui prend en paramètre un String uniquement, et même si le nouveau SDK apporte des méthodes pour générer notre requête, c’est beaucoup moins simple qu’auparavant.
Et la pagination me direz-vous, et bien oui c’est toujours faisable, on ne va pas enlever ce qui est bien pratique tout de même.
List<TestEntity> results = new List<TestEntity>();
TableQuery<TestEntity> queryWithPagination = new TableQuery<TestEntity>();
do
{
Microsoft.WindowsAzure.Storage.Table.TableQuerySegment<TestEntity> resQuery = table.ExecuteQuerySegmented(queryWithPagination, token);
token = resQuery.ContinuationToken;
results.AddRange(resQuery.ToList());
} while (token != null);
Voilà les différences des requêtes de sélection, certes un peu déroutant au début, mais au final beaucoup plus pratique à utiliser.
Etape 6 : Mettre à jour nos données
Maintenant qu’on a des données, qu’on sait comment les requêter, il faut pouvoir les mettre à jour en cas de besoin.
Alors sur le SDK 1.7 et 1.8 c’est sensiblement la même chose, donc je ne vous mettrais que l’exemple de la 1.7. Le problème principal est qu’il faut que les objets que vous souhaitez mettre à jour (ou supprimer) doivent être attachés au contexte, ce qui selon moi est moins flexible qu’un mode POCO.
Pour mettre à jour vos données, il faut donc utiliser le code suivant :
public void Update(TestEntity entity)
{
entity.Timestamp = DateTime.Now;
var descriptor = this.GetEntityDescriptor(entity);
if (descriptor.State == EntityStates.Detached)
{
this.AttachTo(entity.GetType().Name, entity, "*");
}
this.UpdateObject(entity);
this.SaveChanges();
}
Voilà comment on réalise un update, je vous conseille de faire ainsi car cela permet de vérifier le statut de l’objet dans notre contexte et de le mettre à jour. Pour ma part, je modifie le Timestamp de l’objet mais ce n’est pas obligatoire.
Maintenant en 2.0, nous n’avons plus ce contexte, mais il est possible, néanmoins on peut toujours mettre à jour nos données via la façon suivante :
public void Update(TestEntity entity)
{
var csa = CloudStorageAccount.DevelopmentStorageAccount;
var tableClient = csa.CreateCloudTableClient();
var table = tableClient.GetTableReference("NameOfMyTable");
entity.Timestamp = DateTime.Now;
TableOperation updateOperation = TableOperation.Merge(entity);
//TableOperation updateOperation = TableOperation.Replace(entity);
table.Execute(updateOperation);
}
Dans cette version, il est soit possible de faire un Merge de notre entité, soit totalement la remplacer; Cela simplifie grandement l’opération selon car on n’a plus de contexte et on supprime la complexité d’attachement et de détachement de nos objets à un système qui est purement en REST à la base.
Etape 7 : Supprimer nos données
Pour supprimer nos données, c’est le même principe que l’update comme nous pouvons le voir ci-dessous.
En 1.7 et 1.8 :
public void Delete(TestEntity entity)
{
var descriptor = this.GetEntityDescriptor(entity);
if (descriptor.State == EntityStates.Detached)
{
this.AttachTo(entity.GetType().Name, entity, "*");
}
this.DeleteObject(entity);
this.SaveChanges();
}
En 2.0 :
public void Delete(TestEntity entity)
{
var csa = CloudStorageAccount.DevelopmentStorageAccount;
var tableClient = csa.CreateCloudTableClient();
var table = tableClient.GetTableReference("NameOfMyTable");
TableOperation deleteOperation = TableOperation.Merge(entity);
table.Execute(deleteOperation);
}
Je ne m’étendrais pas plus sur cette partie tellement elle est similaire à l’update.
Conclusion
Comme on a pu le voir, beaucoup de changements sont survenus avec cette nouvelle release, c’est certes un peu déroutant à la base mais elle est beaucoup plus pratique à utiliser. Pour retrouver nos données, c’est un peu différent de la version précédente car nous n’avons plus la syntaxe Linq, mais elle empêche les développeurs de requêter le storage de n’importe quelle manière. Selon moi l’essayer c’est l’adopter, j’écrirais d’autres articles sur le sujet notamment comment faciliter la gestion des requêtes “Select”. 🙂