
Les plans d’exécutions et les statistiques Oracle

Les bases de données doivent répondre à la problématique suivante : exécuter les requêtes SQL le plus efficacement possible. Pour cela, la base doit utiliser les informations et l’infrastructure (index par exemple) à sa disposition et lorsque cela est opportun, réaliser des filtres, faire des correspondances de données correctement selon le nombre de lignes etc… C’est la tâche de l’optimiseur.
Le fonctionnement de l’optimiseur est secret et relativement complexe mais nous pouvons comprendre ses principes de fonctionnement.
Pour cet article (et pour les suivants), nous vous proposons un modèle de données qui nous servira pour nos exemples. Les scripts de création vous sont fourni ici : fichier sql de génération du modèle.
Mise en place de notre modèle
Nous vous avons préparé 3 tables qui permettent d’enregistrer les informations sur les consultants d’une entreprise (table CONSULTANT). Ces consultants sont placés en mission dans différentes entreprises via les tables ENTREPRISE et EN_MISSION. Nous avons ensuite généré un ensemble de personnes et d’entreprises.

Les 3 tables sont créées sur le tablespace DATA. Les index sont créés sur le tablespace qui leur est réservé (ouf, nous respectons nos propres conseils). Il y a 2 séquences qui s’occupent d’incrémenter les ID au déclenchement des 2 Triggers sur les tables CONSULTANT et ENTREPRISE.
Pour égayer cela, nous avons embauchés vos héros de StarWars qui travaillent soit pour l’Ordre Jedi, soit pour les Sith (soit pour les deux, n’est-ce pas monsieur Vador ?).
Définition d’un plan d’exécution
Le plan d’exécution est un moyen de présenter les différentes opérations qu’Oracle va réaliser pour répondre à votre requête. Lorsque vous demandez le contenu d’une table, Oracle va devoir lire les blocs de cette table.
Mais dans certains cas, un index peut accélérer la lecture ; s’il l’utilise Oracle va donc lire l’index puis les blocs de la table référencés par l’index. Le plan d’exécution comporte là 2 étapes :
1) Lecture d’un index
2) Lecture des blocs référencés par l’index
Ce plan peut s’écrire sous forme d’arbre :
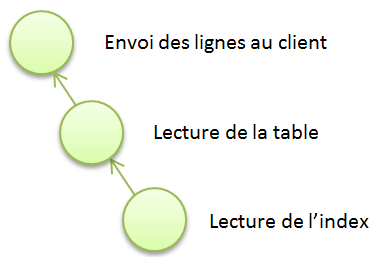
Mais vos DBA préférés aiment la ligne de commande ; voici un plan d’exécution tel qu’Oracle l’écrit en mode texte :
---------------------------------------------------
| Id| Operation | Name |
---------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID| CONSULTANT |
| 2 | INDEX RANGE SCAN | CONSULTANT_PK |
---------------------------------------------------
Les plans d’exécution se complexifient lorsqu’on réalise des jointures. Dans ce cas, Oracle ajoute une étape pour faire correspondre le contenu des blocs d’une table avec une autre.
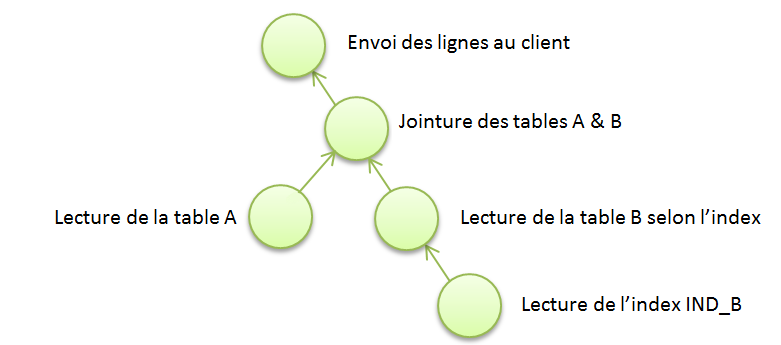
C’est le cas lorsque vous voulez voir les dates de début de mission pour les consultant dont le prénom est “Luke” (Je suis ton père :)…bon ok on sort) ; il faut faire une jointure sur les tables Consultant et En_mission.
SELECT DEBUT
FROM CONSULTANT C
INNER JOIN EN_MISSION M on C.ID_CONSULTANT=M.ID_CONSULTANT
WHERE C.PRENOM='Luke';
Visualiser un plan d’exécution
Les plans d’exécution ne sont pas secrets sous Oracle. Il faut néanmoins demander à vos DBAs préférés d’avoir fait le nécessaire, à savoir d’avoir créé la table plan_table où sera stocké le plan de la requête et de vous avoir donné les droits sur celle-ci .
Pour les afficher, nous procédons en 2 étapes :
1) Demander à l’optimiseur de calculer le plan pour une requête donnée
2) Afficher le plan
Exemple avec la requête :
SELECT * FROM CONSULTANT WHERE ID_CONSULTANT < 5;
explain plan for SELECT * FROM CONSULTANT WHERE ID_CONSULTANT < 5;
set pages 0
SELECT * FROM table(DBMS_XPLAN.DISPLAY);
Plan hash value: 3631186423
-------------------------------------------------------------------------------------------
| Id| Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 4 | 16208 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| CONSULTANT | 4 | 16208 | 3 (0)| 00:00:01 |
|*2 | INDEX RANGE SCAN | CONSULTANT_PK | 4 | | 2 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID_CONSULTANT"<5)
Note
-----
- dynamic sampling used for this statement (level=2)
Qu’en lire ?
Toujours lire le plan de bas en haut. Oracle va parcourir l’index CONSULTANT_PK à l’étape 2 ; cette étape est préfixée d’un * qui est un renvoi à “Predicate Information” qui indique qu’à l’étape 2 on filtre les lignes (normal, l’index porte sur l’ID).
Puis Oracle va faire un accès à la table pour chaque ROWID trouvé dans l’index : étape 1.
Note : Le ROWID est l’identifiant d’une ligne d’une table sur toute une base de donnée. C’est rien de moins que le pointeur de l’index vers la ligne.
Avec le plan d’exécution, d’autres informations sont données comme le coût d’une étape ou bien le temps passé sur celle-ci. Pour mieux les comprendre, nous allons vous présenter comment Oracle construit ces plans. Petit historique…
Optimiseur antérieur à Oracle 7 (<1992 !)
Avant Oracle version 7, l’optimiseur fonctionnait en mode “RULES”. Cet optimiseur avait un arbre de décisions (des “if then else” imbriqués) implémenté afin de trouver le plan optimal. Il commençait par rechercher si un index était présent sur la colonne que nous filtrons. S’il y en avait un, il proposait un plan qui lisait l’index puis la table ; s’il n’en avait pas, il proposait un plan qui lisait toute la table.
En réalité, cet optimiseur était plus complexe, notamment lorsqu’il y avait des jointures dans les requêtes. En effet, il faut alors rechercher si une des tables a un index, puis faire un choix entre ceux présents et enfin choisir le type de jointure qui sera réalisé.
Note : C’est à cette époque que vos amis les DBA demandaient aux développeurs de faire bien attention à l’ ordre des tables dans la clause WHERE…
Vous trouvere ici l’ensemble des règles qui étaient implémentées dans cet optimiseur.
Oracle 7 : le CBO (chicken/bacon/onion)
Avec Oracle 7, l’optimiseur change. Au lieu d’utiliser des règles fixes, Oracle va la nuit collecter dans les tables un ensemble d’informations que l’on appelle les statistiques, puis va utiliser ces statistiques afin de choisir les index à utiliser et les jointures à réaliser.
Les statistiques portent sur des informations telles que la volumétrie, le nombre de lignes, la distribution des différentes valeurs des colonnes indexées, etc..
Quand une requête inconnue arrive, l’optimiseur propose un ensemble de plans d’exécution sans se préoccuper de l’existence d’index ni privilégier un type de jointure. Ensuite, il va déterminer le “coût de la requête” si ce plan est exécuté (en utilisant les statistiques précédemment collectées). L’optimisation se fait en prenant le plan dont le coût est le plus faible.
Voyons le cheminement de l’optimiseur pour notre requête
Oracle va imaginer un plan (plan A) qui lit toute la table CONSULTANT puis qui filtre les lignes dont l’ID est inférieur à 5 ; un autre plan (plan B) qui utilise l’index CONSULTANT_PK pour trouver les ID<5 puis lire les lignes correspondantes.
Ensuite, l’optimiseur calcule les coûts. Le plan A va avoir un coût de 100 car il faut beaucoup d’i/o (lectures sur le disque); le plan B aura un coût de 3… Oracle prend donc le plan B.
Le C ost B ased O ptimizer est né !
Quoi de neuf depuis 1992 avec cet optimiseur ?
L’optimiseur n’a pas changé de fonctionnement. Lors de sa phase de génération de plan, il est aujourd’hui plus inventif : il a de nouvelles possibilités de jointures, il sait utiliser les nouveaux concepts.
Dès la version 8, Oracle pose une limite sur le nombre maximum de plans générés pour une requête et… la limite est 2 000 ! Ne sous-estimez pas sa créativité 😉
Pour les nouveautés importantes, il faut regarder du côté du calcul des statistiques.
Oracle 8 :
Oracle 8 arrive avec le package système DBMS_STATS. Ce package permet tout un ensemble d’opérations sur les statistiques. Avec lui, Oracle donne la possibilité de lancer un calcul de stat sur tous les objets d’une base. En version 7, les statistiques étaient collectées avec la commande ANALYZE fonctionnant sur une table ou un index ; il fallait donc lancer de nombreux ANALYZE. Toutes les futures nouveautés sont implémentées sur le package DBMS_STATS et non sur ANALYZE.
Oracle 9 :
- Nouveauté importante avec la version 9, le principe des tables “STALE”. Les statistiques sont calculées sur les tables qui ont subies un nombre important de modifications (c-a-d plus de 10% d’insert+update+delete de la taille de la table). Ce changement permet de ne calculer les statistiques que là où elles sont éloignées de la réalité. En effet, vous pouvez avoir des statistiques qui datent de 6 mois mais qui restent correctes car les données dans la table n’ont pas changé.
- En v9, Oracle propose de collecter les statistiques sur les performances des disques et des CPU. Ces statistiques permettent de favoriser les lectures de tables plutôt que les indexes si les performances disques sont élevées et celles CPU faibles par exemple.
Oracle 10 :
- Une nouvelle fois, Oracle essaie de calculer les statistiques plus rapidement : les statistiques peuvent être échantillonnées. Le système va lire par exemple 10% d’une table puis va extrapoler les statistiques pour l’ensemble de la table. Le gain est considérable mais les erreurs d’extrapolation peuvent mener à de mauvais plans d’exécution.
- Autre nouveauté : l’optimiseur va calculer des statistiques à la volée. Si un plan doit être trouvé mais avec des objets sans statistiques, Oracle va échantillonner (très faiblement) ces objets pour avoir des statistiques. C’est le principe du “dynamic sampling”. On voit cela dans les plans affichés précédemment dans l’article. Ces statistiques dynamiques ne sont pas conservées et si une autre requête arrive, le sampling sera refait.
Oracle 11 :
Avec cette version, Oracle propose de nouvelles solutions pour stabiliser les plans d’exécution. Trop souvent, les plans changent car un calcul de statistique a favorisé un nouveau plan. Les solutions déployées sont :
- Adaptive Cursor Sharing = C’est une fonctionnalité permettant à l’optimiseur de choisir un plan parmi une sélection de plans pour des requêtes bindées.
- SQL Plan Management = Cette fonctionnalité permet à vos DBA préférés de sélectionner des plans d’exécution pour diverses requêtes et l’optimiseur n’a le droit de choisir QUE parmi ces plans validés manuellement.
Les bonnes pratiques ?
Maintenant que vous avez compris le fonctionnement de l’optimiseur, vous savez que les statistiques sont primordiales pour avoir de bonnes performances. Encore faut-il calculer les statistiques lorsque les données sont représentatives pour les traitements à venir. Calculer par exemple des statistiques en mode full (exhaustif) sur un datawharehouse dépassant le Téra n’a pas de sens !
Sachez que vous, développeurs, êtes les mieux placés pour savoir comment et quand calculer les stats. Vos DBA préférés ne savent pas comment avoir de bonnes statistiques (pire, sans aide extérieure, ils peuvent lancer le calcul des statistiques à des horaires où les tables sont vides – généralement à 22h).
Il n’est pas conseillé de calculer les statistiques en journée ou en même temps qu’un traitement car le calcul est consommateur en CPU.
– Oui, vous pouvez en fin de traitement quotidien déterminer s’il ne faudrait pas calculer les stats : un traitement de chargement qui supprime/insert une grande quantité de données devrait être suivi d’un calcul de stats.
– Oui, vous savez si vos tables ont des données relativement homogènes (dans ce cas, un échantillonnage faible sera suffisant pour avoir des stats correctes).
– Oui, vous savez quand il ne faut surtout pas calculer les stats. Si un traitement de calcul commence par vider la table “RESULTAT” pour la remplir avec des données à jour, il ne faut surtout pas calculer les stats lorsque la table est vide !
Avec l’aide des DBA, vous pourrez savoir s’il n’est pas opportun de calculer les statistiques avant de lancer un traitement important (batch de nuit) ; de cette façon, le traitement prend en compte des statistiques très proche de la réalité avant de calculer les plans d’exécution.
Aller plus loin
https://www.oracle.com/technetwork/middleware/bi-foundation/twp-general-cbo-migration-10gr2-040-129948.pdf
https://en.wikipedia.org/wiki/Oracle_Database
https://www.oracle-base.com/articles/misc/cost-based-optimizer-and-database-statistics.php
https://www.oracle.com/technetwork/database/bi-datawarehousing/twp-bidw-optimizer-10gr2-0208-130973.pdf
https://www.oracle.com/technetwork/database/bi-datawarehousing/twp-upgrading-10g-to-11g-what-to-ex-133707.pdf
https://docs.oracle.com/cd/E11882_01/server.112/e16638/optimops.htm#i80683