
L’organisation des objets sous Oracle
 Dans la base de données relationnelle, nous imaginons instinctivement que lorsque que nous insérons des données dans une table ou que nous créons des objets, ceux-ci sont écrits directement dans des fichiers sur les disques au fur et à mesure de leur remplissage. Ce qui en fait n’est pas le cas !
Dans la base de données relationnelle, nous imaginons instinctivement que lorsque que nous insérons des données dans une table ou que nous créons des objets, ceux-ci sont écrits directement dans des fichiers sur les disques au fur et à mesure de leur remplissage. Ce qui en fait n’est pas le cas !
Selon les SGBDR que ce soit Sybase, SQL Server ou Oracle, l’organisation des structures de données diffère et nous allons voir dans cet article quel est celle proposée par Oracle.
Cet article se veut le premier d’une longue série sur les bonnes pratiques de développement d’applications avec Oracle ; nous allons commencer par définir certains concepts.
Instance, schémas et objets
- Quels sont les éléments logiques minimaux pour utiliser un objet tel qu’une table, un index etc… ?
Une instance Oracle, un compte utilisateur, l’objet.
L’instance Oracle est l’ensemble des processus et des zones mémoire qui permet de faire fonctionner le SGBDR. Nous ne détaillerons pas le concept dans cet article mais lorsque vous avez un problème sur une base et que vous appelez votre administrateur de base données préféré (plus communément appelé DBA), c’est le nom de l’instance que vous indiquez pour qu’il localise le problème.
Contrairement à d’autres SGBDR, Oracle utilise le concept de databased’un point de vue physique (fichiers vus par l’OS). Sous MySQL par exemple, la database est la structure logique qui contient les tables. De son côté, Oracle lie l’objet au compte utilisateur qui la crée. On parle alors de propriétaire de l’objet ou de schéma.
Un schémaest donc un compte utilisateur qui possède des tables, indexes et autres objets.

- Mais alors, chaque compte qui se connecte peut créer des objets ?
Non ; Comme pour la plupart des SGBDR, il faut avoir les droits pour le faire. Sous MySQL, on donne le droit CREATE, sous Oracle, on donne le droit CREATE TABLE ; CREATE VIEW etc…
- Comment le compte utilisateur U2 peut-il lire la table PRODUITS de l’utilisateur U1 ?
Très simple, il suffit de préfixer le nom de la table par le nom de son propriétaire.
SELECT * FROM U1.PRODUITS; D’autres solutions existent via les synonymes ; vues etc…
Bien sûr, il faut que l’utilisateur U2 ait le droit de SELECT sur la table qui ne lui appartient pas.
L’organisation en Schéma permet ainsi de structurer les objets d’un point de vue logique. Par exemple, tout ce qui concerne l’application App1 appartiendra au schéma U1 alors que l’App2 aura comme propriétaire le schéma U2. Elle permet aussi des distinguer les différents comptes, utilisateur en lecture seul, batch applicatifs etc etc.
Remarque : Les rôles permettent de rassembler un ensemble de droits. Il peut être intéressant de créer un rôle donnant le droit de créer des objets, un rôle de lecture ayant uniquement des droits de select… Les rôles sont ensuite attribués aux comptes ; par exemple, le rôle de lecture à un utilisateur de consultation.
Les Tablespaces, liens avec la structure physique
Du point de vue Oracle une base de données est constituée d’un ensemble de fichiers :
– les datafiles (fichiers de données), qui sont les fichiers qui stockent les données utiles aux applications
– les controlfiles (fichiers de contrôle), qui contiennent les métadonnées de la base de données, c’est à dire les informations sur sa structure physique
– les redologs (fichiers de redo), qui contiennent l’historique des ordres de création/modification/suppression d’objets où les mises à jours de données
– et généralement pour les bases de production, les archiveslogs (ou fichiers redo archivés) qui sont des copies des fichiers redo
Les fichiers qui nous intéressent pour cet article sont les datafiles. Ils contiennent les octets des tables, indexes et autres. Les datafiles sont regroupés pour former les Tablespaces.
Ce sont les Tablespaces qui font le lien entre les objets et la structure physique de la base de données. Chaque objet d’une instance existe sur un et un seul Tablespace qui est composé d’un ou de plusieurs fichiers (datafiles).
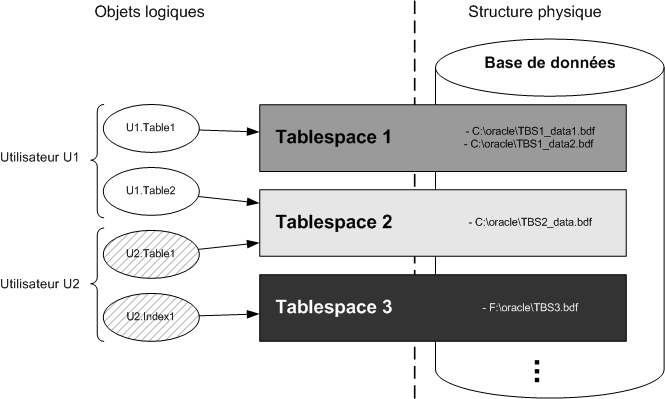
Ainsi, tous les octets de la table Table1 du schéma U1 seront écrits dans le Tablespace1 (fichier TBS1_data1.bdf et/ou TBS1_data2.bdf).
- Pourquoi mon code SQL de création de table a toujours fonctionné alors que je n’ai jamais précisé de Tablespace ?
La raison est : tous les comptes ont un Tablespace par défaut. On peut imaginer que l’administrateur qui vous a créé votre compte vous a attribué un Tablespace qui vous satisfera.
- Alors pourquoi s’en préoccuper ?
Le DBA ne peut pas répartir les objets de façon optimale car il ne sait pas comment fonctionne l’application. Généralement, le DBA va créer deux tablespaces : 1 Tablespace pour les tables + 1 Tablespace pour les indexes (pour chaque schéma). Ces 2 Tablespaces auront leurs fichiers sur des disques distincts. De cette manière, les lectures/écritures seront réparties sur les disques.
Il faut ensuite à chaque création d’objet, préciser le Tablespace cible.
Nous allons voir 3 exemples avec une répartition des lectures/écritures :
- Lorsqu’on lit une table en utilisant un index, on va lire l’index et la table ; s’ils sont dans 2 Tablespaces différents, on améliore la lecture car Oracle pourra lire les 2 objets “en parallèle”.
- Les traitements lourds devraient réaliser les mises à jour sur un(des) Tablespace(s) non utilisé(s) par les sessions utilisateurs ; de cette façon, ils seront moins pénalisant pour l’IHM.
- Si l’infrastructure met à disposition des disques de différentes vitesses (stockage NAS, disques SCSI, disques SSD), le DBA pourra créer des Tablespaces sur chacun d’eux. Il faudra alors choisir les objets à créer sur les Tablespaces dédiés à la vitesse et ceux dédiés à la capacité de stockage.
Pour ces 3 cas, le DBA n’a pas connaissance de la répartition optimale ; c’est avec la connaissance de l’application que les objets peuvent être créés sur le Tablespace optimal.
Conclusion
Nous venons de voir comment le SGBDR Oracle organise les données. Pour l’organisation logique, tout se fait en fonction du propriétaire de l’objet ; le Schema. Pour la répartition physique, Oracle organise indirectement les données via les Tablespace.